
编译原理:基于flex&bison工具的PL0编译器(C语言实现)
C语言实现的pl0编译器 flex&bison实验构成及说明实验环境: WINDOWS & cmd + gcc实现语言: C实验工具: flex & bison1.词法部分2.语法部分3.语义部分Attention !!!参考资料:话不多说,代码地址:https://github.com/RealAmanCao/PL0_Compiler实验构成及说明1.词法部...
编译原理:基于flex&bison工具的PL0编译器(C语言实现)
话不多说,代码地址:https://github.com/Aman-4-Real/PL0_Compiler
一、实验目的
- 理解编译器的工作机制,理清词法、语法、语义各个步骤编译器的工作内容,掌握编译器的构造方法
- 掌握词法分析器的生成工具 LEX 、 语法分析器的生成工具 bison 的用法
- 熟悉 PL/0 语言的编译原理和过程,理解中间代码类 pcode 和编译运行的关系,了解类 pcode 代码的运行机制
二、实验构成及说明
每个部分的实验依赖于上一个部分,层层递进,各个实验需求的输入输出不太一样,详情可以参照各实验报告。如果需要了解整个过程建议先看看最下面的参考资料。
整个pl0编译器支持If, then, else, while, do, read, write, call, begin, end, const, var, procedure, odd以及拓展的case和endcase共16个关键字,支持最多14位变量和常量,暂时仅限正整数(负数和浮点数在词法.l文件中有定义但语法语义部分未使用),过程和变量不能同名,过程和循环均支持嵌套,case不支持嵌套。
实验环境: WINDOWS & cmd + gcc
实现语言: C
实验工具: flex & bison
下面说明一下代码( https://github.com/Aman-4-Real/PL0_Compiler )中的文件和构成:
1.词法部分
说明一下各个文件:
.pl0文件(测试pl0代码,用于最后实现后测试,下同)
test.l文件(词法部分主要文件,包含各识别规则,后更名为Word.l,下同)
steps.txt(最初用来记录实验步骤的,实验报告里面也有)
Output.txt(词法输出文件,输出识别的符号,类型和所在行列数,后更名为WordOutput.txt,下同)
flex.exe(flex工具文件,下同)
lex.yy.c&lex.yy.exe(不做解释。。不知道的话去看相关资料和博客,下同)
词法分析器实验报告(←看字!)
2.语法部分
说明一下各个文件:
Syntax.y(语法部分主要文件,包含各文法即产生式,EBNF范式见Lab3实验报告,下同)
SynOutput.txt&hierarchy.txt(按规约顺序输出的产生式和语法层次结构,下同)
Syntax.tab.c&Syntax.tab.exe(bison Syntax.y生成的c代码及其编译后的exe,下同)
Syntax.tab.h(bison -d Syntax.y生成的头文件,Word.l中有引用)
Syntax.output(bison -v Syntax.y生成的output文件,用来debug解决移进规约冲突)
test.y系列文件(.y样例文件,小型计算器的语法实现)
bison.exe&其他文件或文件夹(bison工具文件,下同)
语法分析器实验报告(←看字!)
3.语义部分
说明一下各个文件:
out.exe(联合编译Syntax.tab.c和lex.yy.c后生成的可执行文件)
pcode.txt(存放.y程序输出类pcode代码的文本文件)
pcode_test.txt(test.pl0的类pcode代码)
interprete.c(解释程序,读取pcode.txt中的类pcode代码并运行,用于测试功能是否正常)
PL0编译器实验报告(←看字!三个部分的实验报告汇总)
三、实验内容
1. PL/0 语言简介
A. PL/0 语言是 Pascal 语言的子集
- 数据类型只有整型
- 标识符的有效长度是 10 ,以字母开头的字母数字串
- 数最多 14 位
- 过程无参,可嵌套(最多三层),可递归调用
- 变量的作用域同 Pascal ,常量为全局的
B. 语句类型:
- 赋值语句: if…then…, while…do…, read, write, call
- 复合语句: begin …end
- 说明语句: const…, var…, procedure…
C. 13个保留字:
- If/then, while/do, read/write, call, begin/end, const, var, procedure, odd
2. PL0 语言的 EBNF 范式




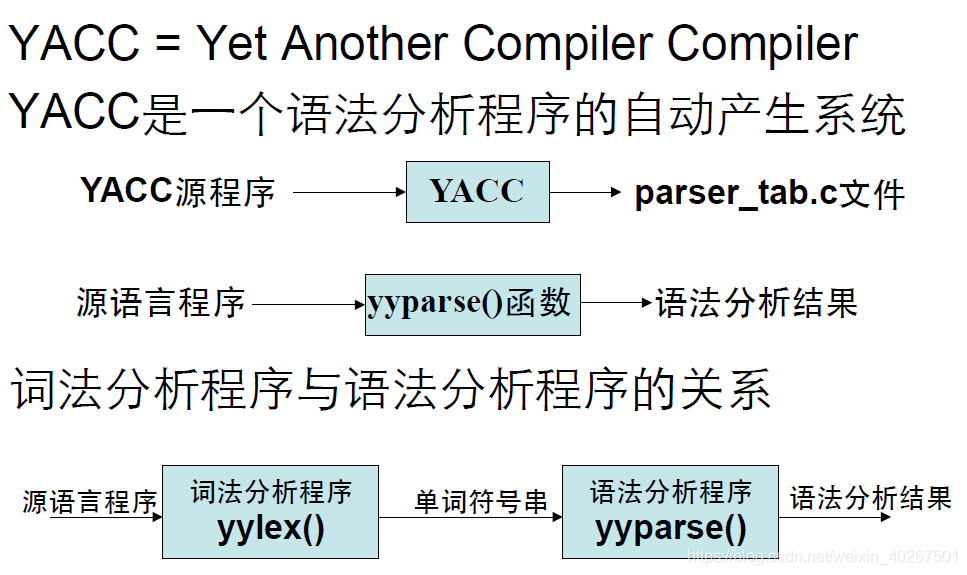
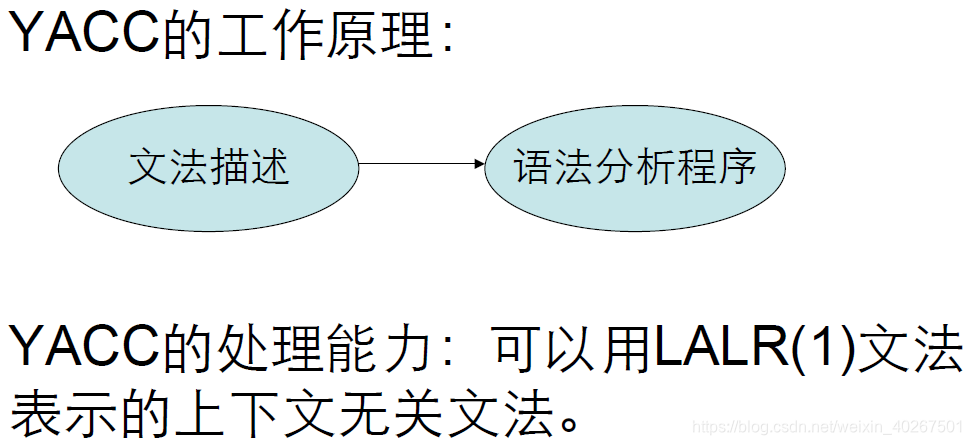
3. YACC 简介
4. 类 pcode 代码简介
A. 目标代码类 pcode 是一种栈式机的汇编语言
-
栈式机系统结构:没有累加器和寄存器,只有存储栈指针,所有运算都在栈顶
-
指令格式: fla
f:功能码 l:层次差(标识符引用层减去定义层) a:根据不同的指令有所区别
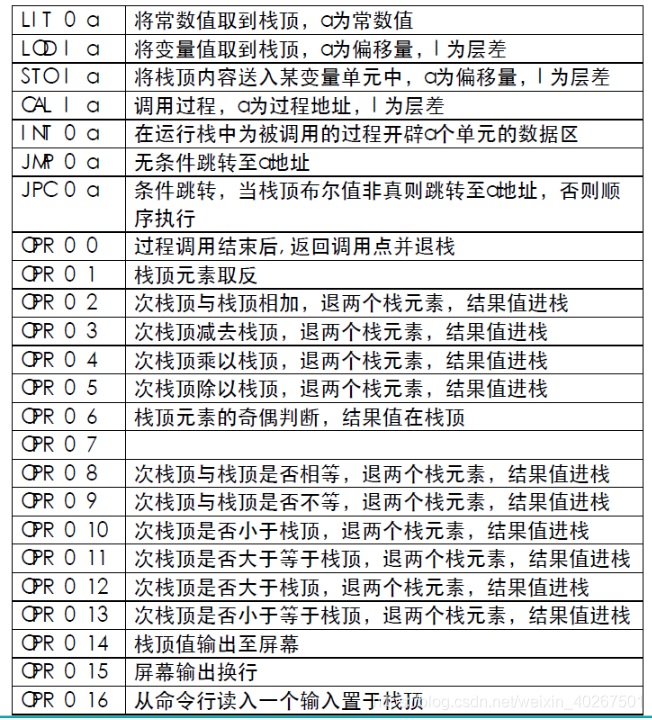
B. 指令功能表
5. 实验内容
(1)词法部分
1)用 flex 工具生成一个 PL/0 语言的词法分析程序,对 PL/0 语言的源程序进行扫描,识别出单词符号的类别,输出各种符号的信息 。
2)输入 PL/0 源程序
3)输出 把单词符号分为下面六类,然后按单词符号出现顺序依次 输出各单词符号的种类和出现在源程序中的位置(行数和列数)
- K 类(关键字)
- I 类(标识符)
- C 类(常量)
- O 类(算符)
- D 类(界符)
- T 类(其他)
4)实验环境
- Windows & C 或 C++
- 词法分析器生成工具: flex
(2)语法部分
1)用 bison 工具生成一个 PL/0 语言的语法分析程序,对 PL/0 源程序进行语法分析。
- 输入:PL/0 源程序
- 输出:
• 按归约顺序 用到 的语法规则
• 语法单位的层次结构关系
2)实验环境
- Windows & C
- 语法分析器生成工具: bison
(3)语义部分
1)在语法分析的基础上,在 bison 工具生成的 .y 文件中, 进行静态(类型检查和作用域分析) 和动态(根据产生式进行翻译)的语义分析, 构造符号表, 在相应的语法规约规则后添加适当的语义动作,生成可以用 interprete.c 程序直接读取并运行的类 pcode 代码。
- 输入 PL/0 源程序
- 输出: 源程序对应的类 pcode 代码
2)实验环境
- Windows & C
- 语法分析器生成工具: bison
- 类 pcode 代码解释器
interprete.c程序
四、实验步骤
1. 词法部分
(1)思路说明
根据词法部分的要求,将对应的词法定义规则写到 .l 文件中。定义不区分大小写的 13 个保留字(之后增加了保留字 else 的功能,共 14 个)、标识符、常量(正负整数和浮点数)、算符、界符等的识别规则和动作 ,并将相应内容输出到词法输出文件中 。
(2)识别规则:
KeyWord [iI][fF]|[tT][hH][eE][nN]|[eE][lL][sS][eE]|[wW][hH][iI][lL][eE]|[dD][oO]|[rR][eE][aA][dD]|
[wW][rR][iI][tT][eE]|[cC][aA][lL][lL]|[bB][eE][gG][iI][nN]|[eE][nN][dD]|[cC][oO][nN][sS][tT]|
[vV][aA][rR]|[pP][rR][oO][cC][eE][dD][uU][rR][eE]|[oO][dD][dD]|[cC][aA][sS][eE]|
[eE][nN][dD][cC][aA][sS][eE]
Identifier [A-Za-z][A-Za-z0-9]*
Zero [0]
PossiInt ([+]?[1-9][0-9]*)
NegatiInt ([-]?[0-9]+)
Float {Zero}|{PossiInt}|{NegatiInt}(.[0-9]+)
Constant {PossiInt}|{NegatiInt}|{Zero}
Operator [\[\]\^\-\*\+\?\{\}\"\\\(\)\|\/\$\<\>\#\=]|:=|<=|>=
Delimiter [\,\;\.\:]
Space (\ )
Tab (\t)
Other [^{KeyWord}{Identifier}{Constant}{Operator}{Delimiter}]
(3)对代码的说明
代码分为四个部分:声明、辅助定义、识别规则和用户子程序
- 声明部分定义了要用到的全局变量;
- 辅助定义定义了
Keyword,Identifier等正规式,以便后续的代码更加易读。(尽管 PL/0 语言中数据类型只有整型,也同时定义了识别正负浮点数的正规式并通过了测试 ,可供功能拓展); - 识别规则则是给出了对相关正规式识别后的一系列操作,包括输出到 txt 文件和错误处理等;
- 用户子程序主要是调用
yylex()函数,并增加yywrap()函数(由于不增加时在编译lex.yy.c文件过程中会报错,故增加直接返回 1 的yylex()函数);
对于未匹配的字符,程序会识别为 T 类,同时对于长度超过限定的标识符和常量会进行报错。
(4)操作命令:
a.将 flex .exe 文件、写好的 lex 程序和待输入的 PL/0 程序源代码放到同一个文件夹
b. 在 Windows 系统下打开 cmd ,进行入当前文件夹
c. 在 cmd 下输入命令 flex lex.l 将 lex 程序用 flex 工具生成 lex.yy.c 文件,在 C 编译环境下对该文件进行编译,生成 lex.yy.exe 文件
d. 输入命令 lex.yy.exe < max.pl0 对 max .pl0 文件进行词法分析
2. 语法部分
(1)思路说明:
对于第一个输出,按规约顺序输出用到的语法规则,思路比较简明,yyparse函数执行规约的时候会按照程序本身的顺序进行规约,即直接在对应产生式规约后执行的动作中加上将该产生式输出到输出文件的操作即可。
对于第二个输出,建立一个栈,在词法每次进行匹配的时候,将匹配到的终结符入栈。同时建立一个树,左节点表示孩子节点,右节点表示兄弟节点。在语法文件进行规约的时候,在规约动作中,将产生式右边的对应的终结符或者非终结符出栈,并建立新节点作为产生式左部的非终结符,将产生式右部的第一个符号作为产生式左部的孩子节点,并以此次将右部其他节点作为其左边节点的兄弟节点,最后将产生式左部的节点压入栈中。程序执行完成规约后,对建立的树进行先序遍历,对应层次越深缩进越多,以此来表示层次结构。
(2)实验步骤:
a. 将 flex.exe 文件、 bison 相关程序文件、写好的 lex 程序、写好的语法的 .y 程序和待输入的 PL/0 程序源代码放到同一个文件夹
b. 在当前目录下打开 cmd
c. 在 cmd 下输入命令 flex lex.l 将 lex 程序用 flex 工具生成 lex.yy.c 文件,输入命令 bison Syntax.y -d 将 .y 程序用 bison 工具生成 Syntax.tab.c 和 Syntax.tab.h 文件(提前将 Syntax. tab.h 文件在 lex.l 声明部分中引用),并在生成的 Syntax.tab.c 中的 /*Shift the lookahead token.*/ 注释下方添加 Process(key); 一行,用于在向前读取一个符号之前将上一个符号进行 Process 函数中的相关操作(详见实验结果部分)。
d. 在 cmd 下用 gcc 命令将 Syntax.tab.c 和 lex .yy.c 文件联合编译
gcc -o Syntax.tab.exe Syntax.tab.c lex .yy.c
e. 输入命令 Syntax.tab.exe < test syn.pl0 对 test syn.pl0 文件进 行对应输出
(3)对代码的说明
下面对部分相关代码进行说明:
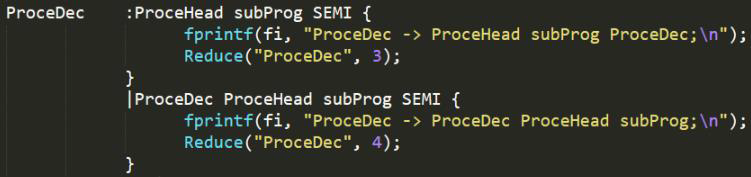
- 上图是过程并列的部分产生式定义,采用左递归方式 ,对应规约动作为输出该产生式,并调用
Reduce函数进行出栈入栈和连接节点操作
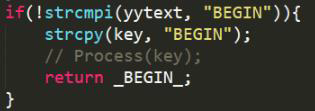
- 上图为词法
.l文件中的代码,匹配到BEGIN终结符后,将该终结符压入栈中(由于 bison 会提前多看一个符号,所以将具体的Process函数即入栈操作放到了函数即入栈操作放到了Syntax.tab.c中移进操作之前),并将其中移进操作之前),并将其 return 到语法分析程序中进行处理到语法分析程序中进行处理
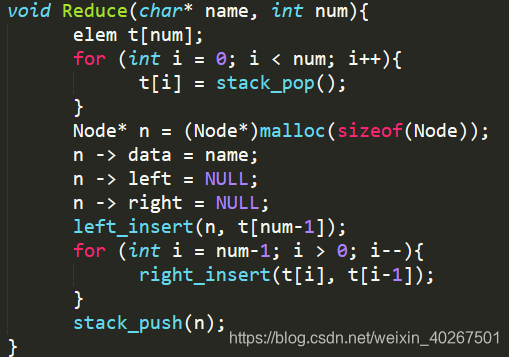
- 上图是语法规约动作中对应的规约操作,即产生式左的节点入栈,右边的节点进行连接
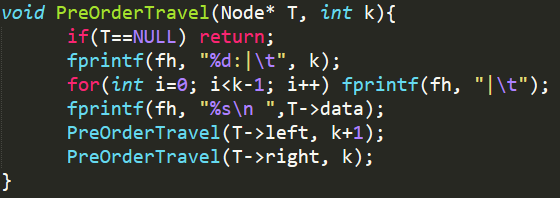
- 上图是进行先序遍历的函数,
k表示递归的层数,T是传进来的节点,最终规约完后只剩Program一个节点,即树的根节点,从其开始先序遍历即可得到对应的层次结构
3. 语义部分
(1)思路说明:
语义部分要求大致可以分为两个部分完成:符号表和生成类 pcode 代码。
对于符号表,记录了所有常量、变量、过程名的相关信息,以及相应的还有 display 表。用结构体数组实现符号表,其中包含了各个标识符的类型、名字、层次等信息,具体结构如下:
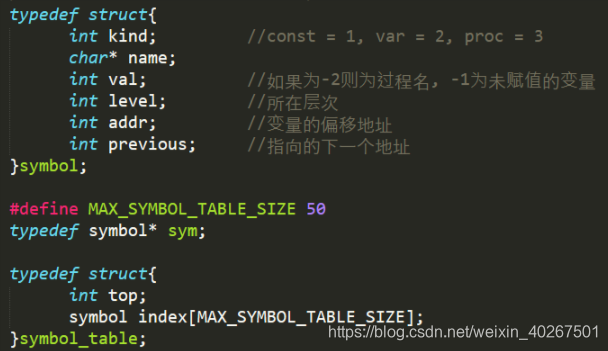
其中 level 标记了标识符所在的层次,主程序所在的层次为 0;kind 记录了标识符的类型; val 存储变量的值,为进行区分,未赋值的变量为 -1,过程名为 -2;addr 只有变量使用,记录了变量在运行栈中相对于及地址的偏移量 ,从静态连、动态链、返回地址之后开始,即从 3 开始。
在 bison 中使用 union 结构可以定义非终结符和终结符的类型,便于在识别具体的语法规则后相应的语义动作中进行值的传递。定义的类型如下:

上图也给出了 .y 文件中定义的各个终结符和非终结符及其类型,包括左结合的优先性和用 %nonassoc 定义的 else 的优先性(强于 if then ),在具体的产生式中做如下定义:

具体识别过程中则会优先判断 if then 后是否有 else 关键字,有的话则优先进行移进。
在对应的规约位置后的语义动作处进行相关操作。声明部分先对标识符进行是否定义过的判断 (故过程和变量不能同名 ),即静态语义检查,未定义过则 将其名字、值、层次等信息 写入符号表。 栈式的 display 表最底处加入主程序定义部分开始的位置,即 1 ,过程定义处将过程名加入到符号表中并将过程名在符号表中的位置写到 display 表的栈顶,同时写入符号表的时候将过程及其层次和当前类 pcode 的位置写入一个过程栈,便于在之后 call 过程的时候进行调用。
下面对类 pcode 各条代码在对应规约规则后的语义动作中具体生成方法进行介绍。 类 pcode 生成函数 gen 三个参数对应为 f l a 。
LIT :将常量取到栈顶 ,识别到常量则直接将其值生成 LIT 代码,若引用之前定义过的常量名,则在符号表中找到其值进行生成。

LOD :将 l 层差,偏移量为 a 的变量取到栈顶;在识别到标识符后取值。

STO :将栈顶值送到 l 层差,偏移量为 a 的变量单元。 在赋值语句和 read 语句规约后生成。

CAL:调用层差为 l ,位置为 a 的过程。对应过程位置到过程栈中根据过程名寻到,故过程名字不能重复。

INT:用于过程开始时开辟 a 个变量的数据区。在声明部分之后,具体语句开始之前生成,查符号表和 display 表得到当前层的常量变量个数,前 3 个数据区为静态链、动态链和返回地址,故实际开辟大小为 3 常量变量个数。

JMP:无条件跳转至第 a 条类 pcode 代码。在应无条件跳转的位置先记录位置,然后生成 JMP 0,0 的代码等待之后回填。在 while 循环中,每层循环记录循环开始位置,然后在循环结束时生成跳转到循环开始时位置的 JMP 代码,然后循环位置栈顶减一。

JPC :条件跳转,当栈顶值非真则跳转到 a 地址,否则顺序执行。 所有进行条件判断的位置记录位置并生成 JPC,0,0 的代码,在条件为非时应该执行的语句之前进行回填。

OPR :根据 a 具体的值进行相应的操作 。在程序或过程结束规约的时候生成 OPR,0,0 结束程序,在相应加减乘除 read 和 write 等操作规约时生成对应 a 值的 OPR 代码 。

对于回填的处理,设置了一个回填栈,在每次需要回填的位置先记录要回填的位置并压入栈中,到了规约要回填的时候把当前类 pcode 代码的行数 code_line 回填到栈中记录的位置,并将栈顶位置出栈。

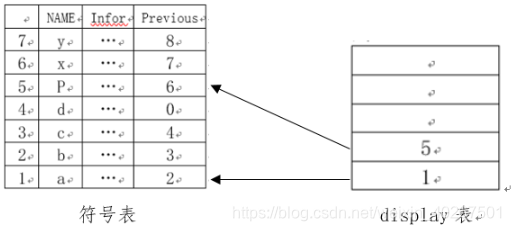
对于条件语句,带 else 的条件语句优先级比单纯的 if then 高。在对条件进行判断之后,随后记录回填位置并生成 JPC 代码,在 then 后的语句执行完之后进行回填。如果是带 else 的条件语句,在 then 执行完之后,把当前 code _line 的下一行先回填至条件判断的假出口,回填栈顶出栈后再记录当前位置为回填位置,在 else 后的语句执行完之后再进行回填。
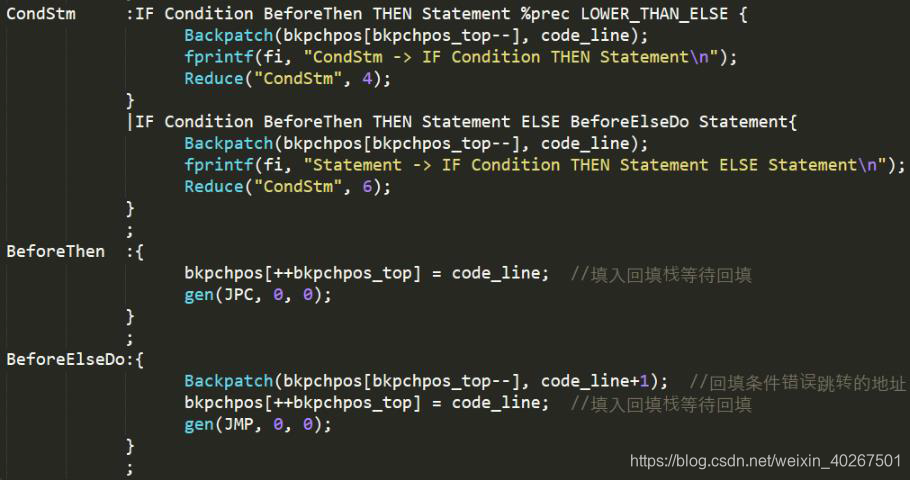
对于 while 循环语句,相似的,设置了记录循环位置的栈 whilepos ,在循环开始时记录循环所在的 code _line 位置,条件判断之后记录回填位置并生成 JPC 代码,在循环条件的真出口语句执行完之后,先生成 JMP 回记录的循环初始位置的代码,再将循环的假出口进回填。
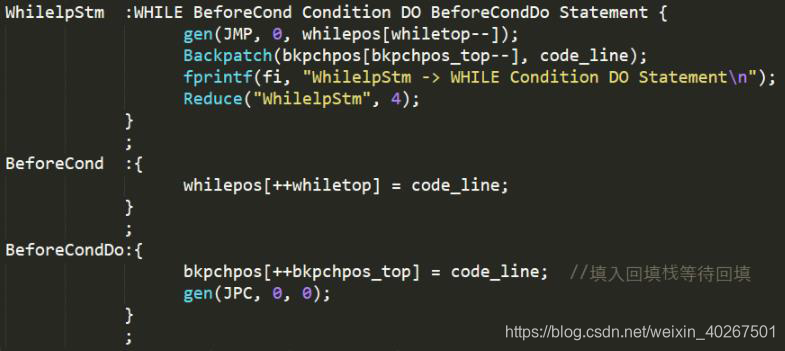
对于拓展功能 case 语句,语法定义了对于给出的标识符,和 casebody 中的每个常量进行条件比较,如果相等则执行后面的语句。在 casehead 的时候记录标识符,在常量之后记录位置等待回填,每一条 case 比较完之后进行回填,并将记录的标识符重新生成 LOD 代码。到了 endcase 规约的时候对最后一次 case 的 LOD 进行回撤,即 code line --,结束 case 语句。
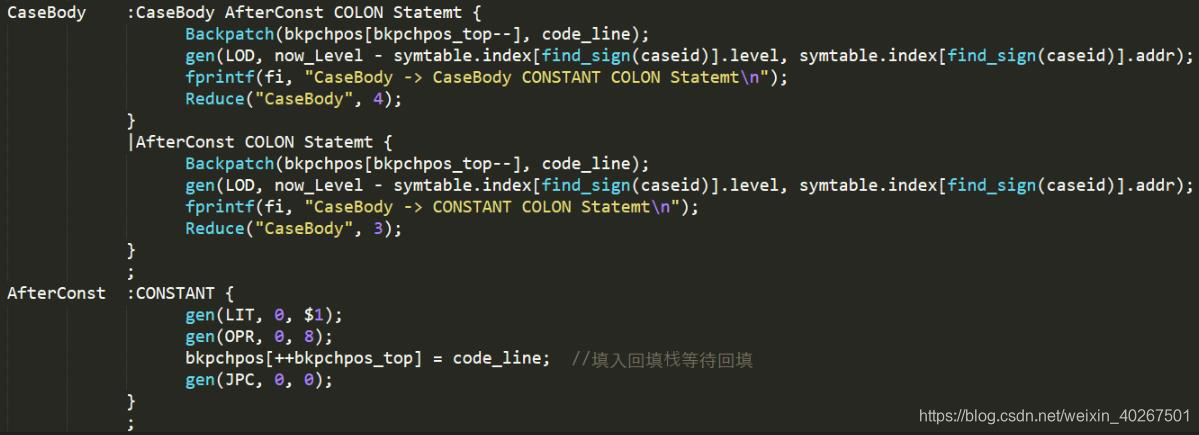
对于生成的类 pcode 代码, interprete.c 文件会从 .txt 文件中读取类 pcode 代码并进行解释, 用到的 base 函数示意图如下:

q 引用 m 的变量时层次差 l 为 2 ,所以需寻找 m 的基地址 b 。由 q 的 SL 找到 h 的基地址 b 再由 h 的 SL 找到 m 的基地址 b 。
具体实现方式如下:
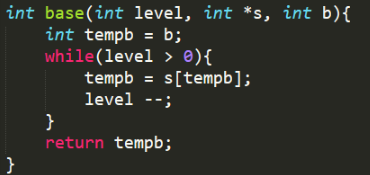
对于传入的参数和运行栈指针 s ,在层次差范围内,依次根据上一层次的基地址找上上层的基地址,最后得到所要寻找层的基地址并返回 。
五、实验结果
1. 词法部分
执行 flex test.l (语法和语义部分更名为 Word.l )命令后未报错如下:

对 lex.yy.c 进行编译,并执行 lex.yy.exe < case_test.pl0:
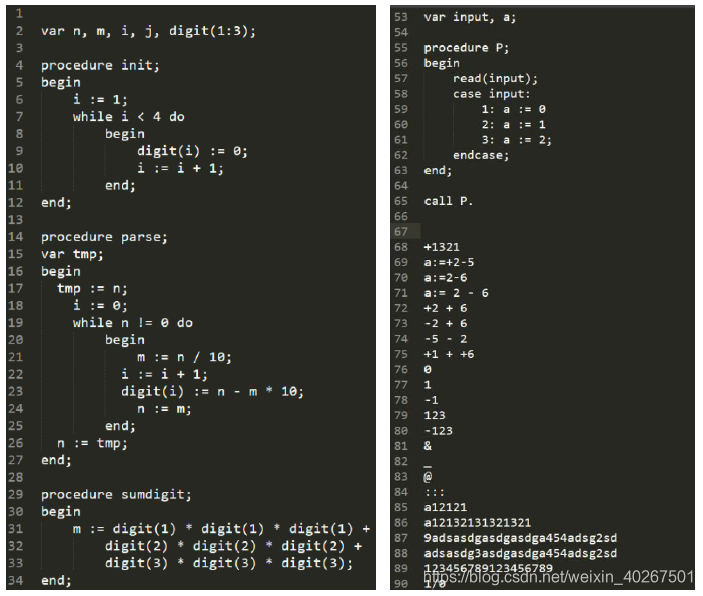
case_test.pl0 作为样例 pl0 代码所示如下,在其末尾添加了不符合规定的标识符和各种常量和符号用于测试不同情况下的输出情况。
其最终输出到 txt 文件中的结果如下:
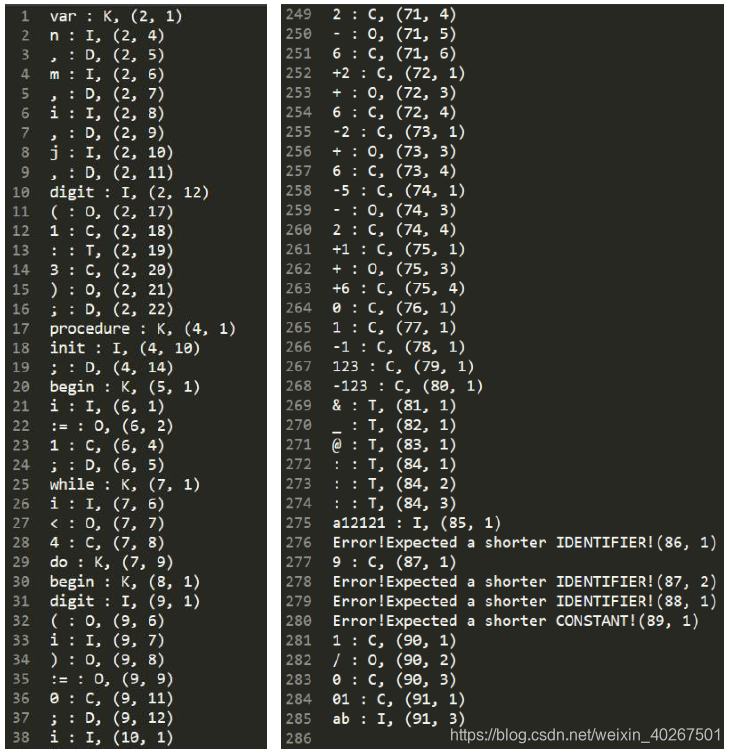
2. 语法部分
语法部分在词法 Word.l 文件中增加了新的内容,需要用 flex 对 .l 文件重新编译。在 bison 指令中 添加 -d 用于生成 .l 中引用的 Syntax.tab.h 头文件(此外若执行 bison 命令后有移进规约冲突的报错,可添加 -v 生成可读的 .output 文件,里面记录了所有的状态信息,方便查看各种移进规约冲突等的位置 )。
在使用命令 bison -d Syntax.y 生成 Syntax.tab.c 文件后,在其中查找 /*Shift the lookahead token. */ 的注释,在其下面添加一行 Process(key);代码,再用 gcc -o Syntax.tab.exe Syntax.tab.c lex.yy.c 命令进行联合编译(注:由于 bison 识别符号会自动提前 lookahead 一个符号,若在词法 Word.l 中对应的识别规则后的动作中进行 Process 函数的操作会造成生成语法层次结构的混乱,故在 lookahead 之前进行 Process 函数的操作)。
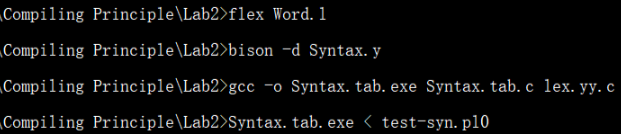
用 test-syn.pl0 文件进行测试,使用命令 Syntax.tab.exe < test-syn.pl0 按规约顺序输出的语法规则如下:

语法单位的层次结构关系如下,行首的数字表示节点(递归)的层数:
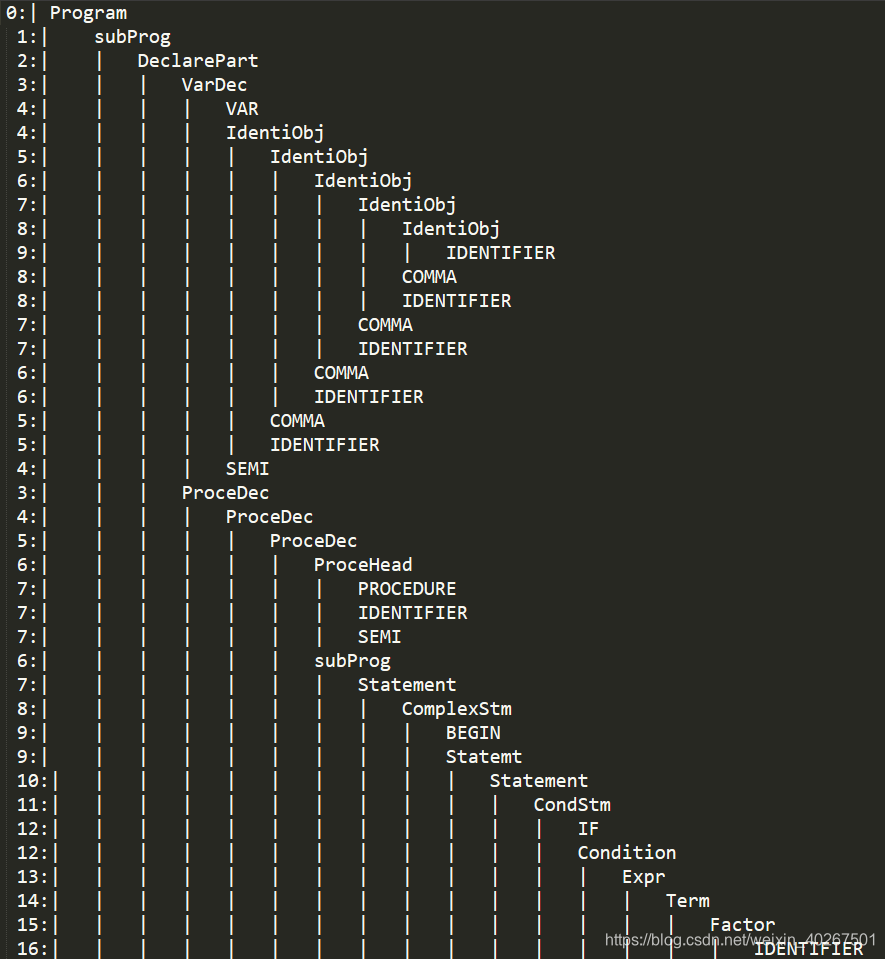
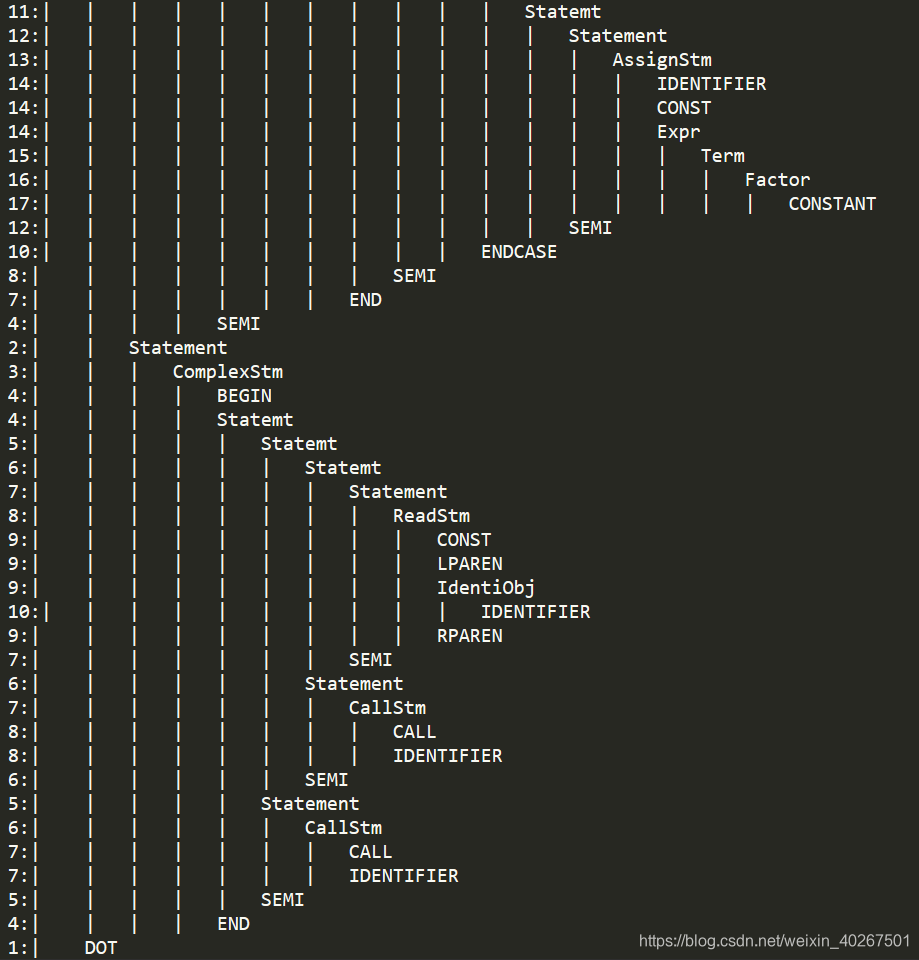
3. 语义部分
和语法部分一样,需要在编译生成 .tab.c 文件中 /* Shift the lookahead token. */ 的注释下面添加一行 Process(key); 联合编译后生成 out.exe 可执行文件,执行 out.exe < test.pl0 会在 pcode.txt 中输出生成的类 pcode 代码。 下面是用于测试的 pl0 代码,里面包含了递归调用、过程并列、过程嵌套、 if then 条件语句、 if then else 条件语句、 while 循环语句、 case 语句和常规的读写运算等操作语句。
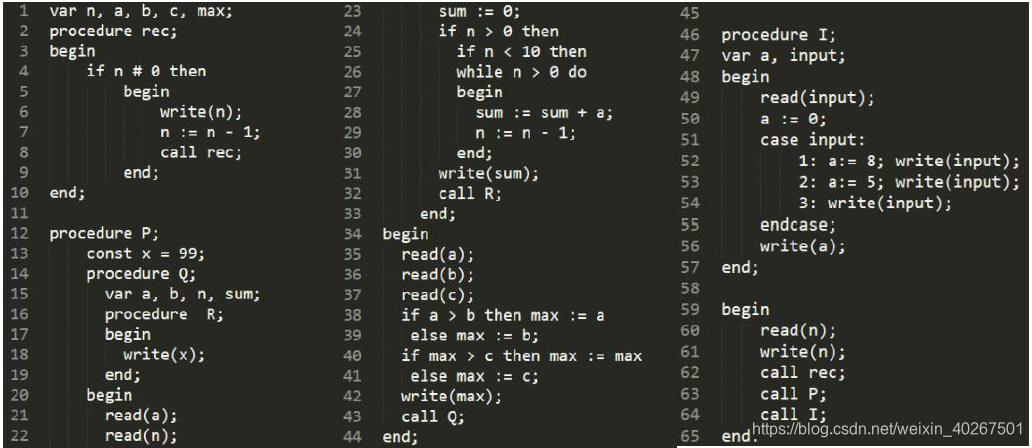
输出的类 pcode 代码如下:

执行 interprete.c 解释程序。 pl0 程序内容为:先输入 1 个数字并将其输出;调用 rec 函数, 输入 1 个数,将该数依次减 1 输出;调用 P 过程 ,输入 3 个数并将最大值输出,其中调用 Q 过程输入 2 个数并用加法方式循环计算两数之积,其中再调用 Q 过程输出 P 过程中定义的常量值;调用 I 过程根据输入的数 case 操作修改值并输出输入的数和操作执行后的 a 变量。 具体执行过程如下:

至此,整个 PL/0 编译器已经实现,包括词法、语法、语义三个部分,生成类 pcode 代码后由 interprete.c 程序读取并解释运行 ,对程序进行了多次调试和测试,运行正常 。如果遇到异常可尝试修改 interprete.c 程序中 STACKSIZE 的大小及 .y 文件中各个栈或数组的大小 。
Attention !!!
-
在cmd中运行方式参考Lab3实验报告,如
out.exe < max.pl0。 -
在
.l、.y和interprete.c中修改输出路径方可正常运行。 -
再次提醒语法和语义部分务必在编译
Syntax.tab.c前在其中/* Shift the lookahead token. */的注释下面添加一行Process(key);。
代码地址:https://github.com/Aman-4-Real/PL0_Compiler
参考资料:
[1]: pl0语言简介 https://wenku.baidu.com/view/5c16572a4b73f242336c5f68.html
[2]: lex(flex)&yacc(bison) https://blog.csdn.net/banana_baba/article/details/51526608
[3]: YACC(BISON)使用指南 https://blog.csdn.net/wp1603710463/article/details/50365640
[4]: pl0编译程序的实现 https://wenku.baidu.com/view/6a5ea41d2f3f5727a5e9856a561252d380eb20eb.html

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)