Linux服务器深度学习环境的配置
一、驱动的安装服务器中搭载的GPU为4块Tesla V100,想来用来跑深度学习程序,所以需要按驱动等。1.寻找对应的驱动去NVIDIA的驱动下载官网:https://www.nvidia.cn/Download/index.aspx?lang=cn,下载自己GPU对应的驱动。下载完了之后...
一、驱动的安装
服务器中搭载的GPU为4块Tesla V100,想来用来跑深度学习程序,所以需要按驱动等。
1.寻找对应的驱动
去NVIDIA的驱动下载官网:https://www.nvidia.cn/Download/index.aspx?lang=cn,下载自己GPU对应的驱动。
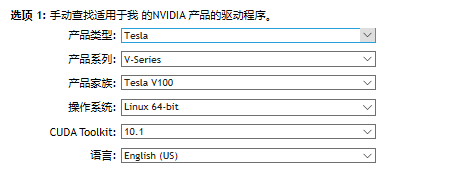
下载完了之后通过ssh上传到服务器上,我是在我的用户下创建了一个driver的文件夹,放在了这个文件夹下面。
2.禁止Linux系统自带的集成驱动
因为不禁止自带的集成驱动会出现各种问题,包括带有图形界面的循环登录等;而且也会造成无法安装NVIDIA的驱动。
将驱动添加到黑名单blacklist.conf中,但是由于该文件的属性不允许修改。所以需要先修改文件属性
查看属性:sudo ls -lh /etc/modprobe.d/blacklist.conf
修改属性:sudo chmod 666 /etc/modprobe.d/blacklist.conf
用vim编辑器打开:sudo vim /etc/modprobe.d/blacklist.conf
使用vim在打开的文件后面添加几行:
blacklist vga16fb
blacklist nouveau
blacklist rivafb
blacklist rivatv
blacklist nvidiafb
并且执行:sudo update-initramfs -u
之后,重启服务器:sudo reboot,我的重启一次大概花了2分钟。
重启之后执行:lsmod | grep nouveau
若没有输出信息则证明已经禁止了自带的集成显卡。
3.开始安装驱动
因为我的服务器是刚刚搭载的,之前没有装过NVIDIA的驱动,所以不用清除之前的残余,但一般都运行一下清除指令:
sudo apt-get --purge remove nvidia-*
在安装驱动的时候需要几个依赖包,比如gcc,g++,make ,所以在安装驱动之前先安装这几个依赖包,指令:
sudo apt-get install gcc
sudo apt-get install g++
sudo apt-get install make
接着就是安装驱动,包括了修改run文件的权限和安装:
sudo chmod a+x NVIDIA-Linux-x86_64-396.82.run
sudo ./NVIDIA-Linux-x86_64-396.82.run -no-x-check -no-nouveau-check -no-opengl-files
在上述指令中,–no-opengl-files表示只安装驱动文件,不安装OpenGL文件,这个参数最重要。–no-x-check 安装驱动时不检查X服务。–no-nouveau-check 安装驱动时不检查nouveau(注:这个选项和1.2禁止集成的nouveau驱动组成双保险,其实一项操作就可以了)
4.检查安装是否成功
nvidia-smi,如果出现了显示你GPU的框图就证明安装成功了,我的是:

显示了服务器上搭载了4块 Telsa V100,驱动的版本是396.82
也可以通过 cat /proc/driver/nvidia/version 来查看驱动的版本:
NVRM version: NVIDIA UNIX x86_64 Kernel Module 396.82 Fri Jan 25 21:07:39 PST 2019
GCC version: gcc version 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.11)
驱动这一块算是安装完成了,等着明天安装一下docker的深度学习环境 或者 直接在服务器上安装CUDA和cudnn。
二、CUDA和cudnn安装
CUDA安装:
1.CUDA下载
先通过nvidia提供的CUDA与驱动版本对应的表来选择需要安装的CUDA版本,网址为:
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/#overview
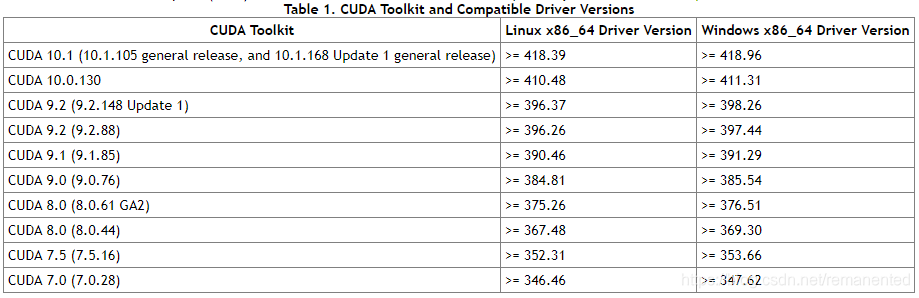
因为我安装的驱动是396.82.要大于这个版本的驱动,所以我选择了下载CUDA9.2
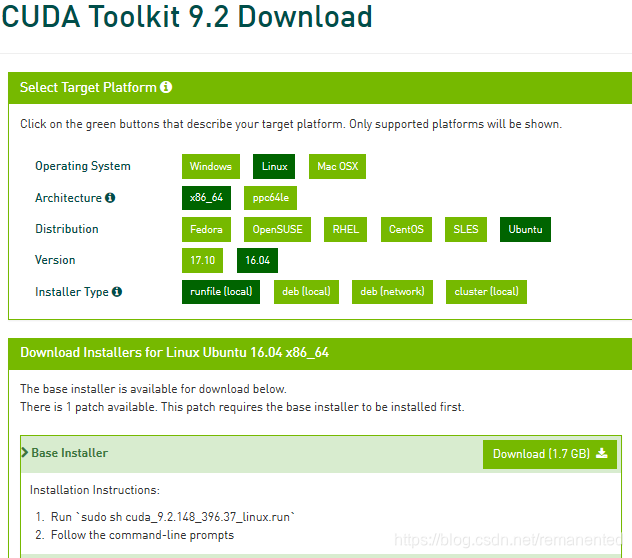
2.CUDA指令安装
下载完了之后,上传到服务器,利用指令安装:
sudo sh cuda_9.2.148_396.37_linux.run
然后就是出现了大量的条款,直接一直Enter到百分之百就可以了,之后除了让你安装驱动那一块选择no,其他的选择yes。
3.添加环境变量
接下来就是添加环境变量:
使用指令打开.bashrc: sudo vim ~/.bashrc ,接着在最后面添加三行指令:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-9.2/lib64
export PATH=$PATH:/usr/local/cuda-9.2/bin
export CUDA_HOME=$CUDA_HOME:/usr/local/cuda-9.2
使用指令让其生效:source ~/.bashrc。 nvcc -V 可以查看安装的版本信息,我的如下:

CUDA算是安装成功了。
三、安装cudnn
1.cudnn下载
去网址https://developer.nvidia.com/rdp/cudnn-archive下载对应的cudnn版本,我对应下载的为:
![]()
下载完了之后直接上传到服务器上
2.解压和复制
对cudnn文件使用指令解压:sudo tar -zxvf cudnn-9.2-linux-x64-v7.5.0.56.solitairetheme8
它会在当前的目录下创建一个cuda 的文件夹,我们需要把这个文件夹中的文件复制到/usr/local文件夹下。指令为:
sudo cp lib/lib* /usr/local/cuda/lib64/ # 将所有lib文件复制到cuda文件中
sudo cp include/cudnn.h /usr/local/cuda/include/ # 将头文件复制到cuda中
整完之后cuddn也算是装完了。接着就是下载anaconda和pytorch了,可以参考之前写的一篇文章:linux服务器下命令行对anconda进行下载及其配置。
四.服务器在不同的CUDA和cudnn版本下的兼容
因为服务器里面有各种用户,每个用户可能需要不同版本的CUDA和不同版本的cudnn,所以需要兼容。可以参考文章:多版本的CUDA和cudnn兼容,主要的思想是让不同用户下的CUDA链接不同的cudnn,建立链接。
五.顺道记录一下screen分屏
1.先Sreen -S/R test 先建立一个名为test的终端
2.Ctrl+a后,shift+s实现上下分屏;或者Ctrl+a后,| 实现左右分屏
3.Ctrl+a后,Tab 实现跳转到当前界面中下一个终端中,
4.因为分屏出来的是空的屏幕,需要Ctrl+a后,c实现添加新的终端
5.关闭当前焦点下的屏幕为Ctrl+a,X
6.关闭该焦点下的终端为Ctrl+a,k,会提示你是不是需要关闭,键入y就好
7.关闭当前界面下除了本身之外的全部屏幕为Ctrl+a,Q
其中的操作,screen -x name :attach上目前被attach的终端;screen -d name :dettach名字为name的终端
screen -r name :恢复dettach名字为name的终端;
删除一个正在运行的screen进程:screen -X -S PID quit
linux的基本shell指令:移动 rm;复制cp;删除 mv;创建文件 mkdir;查看内核 uname -r;

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)