
ELK 系统的构建与使用
ELK 项目是开源项目 Elasticsearch、 Logstash 和 Kibana 的集合,集合中每个项目的职责如下。Elasticsearch 是基于 Lucene 搜索引擎的 NoSQL 数据库。Logstash 是一个基于管道的处理工具,它从不同的数据源接收数据,执行不同的转换,然后发送数据到不同的目标系统。Kibana 工作在 Elasticsearch 上,是数据的展...
ELK 项目是开源项目 Elasticsearch、 Logstash 和 Kibana 的集合,集合中每个项目的职责如下。
- Elasticsearch 是基于 Lucene 搜索引擎的 NoSQL 数据库。
- Logstash 是一个基于管道的处理工具,它从不同的数据源接收数据,执行不同的转换,然后发送数据到不同的目标系统。
- Kibana 工作在 Elasticsearch 上,是数据的展示层系统。
这三个项目组成的 ELK 系统通常用于现代服务化系统的日志管理,也会用于其他场景,例如 BI、安全和合规、网页分析等。
Logstash 用来收集和解析日志,并且把日志存储到 Elasticsearch 中井建立索引, Kibana 通过可视化的方式把数据呈献给数据的使用者。
最近, ELK 系统每个月有 50 万的下载量,俨然成为世界上最流行的日志管理平台, 远远超过了据说只有 1 万用户的传统 Splunk 日志管理平台,是什么促成了 ELK 系统的广泛应用呢?
因为 ELK 系统满足了服务化系统的日志分析的需求,因此变得越来越流行。 Splunk 企业级 日志分析系统在市场上己经领先多年了,尽管它的功能强大,但是使用成本较高,很多小公司 无法负担这个成本,所以企业开始越来越多地倾向使用于 ELK 系统。尽管 ELK 系统与 Splunk 相比没有 Splunk 的功能丰富,但是其优点是简单、健壮和高效。另外,互联网公司倾向于使用开源软件。
ELK 系统是当前最流行的日志分析平台,本节将分别介绍 Elasticsearch、 Logstach 和 Kibana 的安装和使用 。
关于 Spring中 Log4j 集成 ELK ,前面做过简单的介绍,可以点击查看:Spring Boot (日志篇):Log4j整合ELK,搭建实时日志平台
以下安装基于 JDK 1.7 以上版本环境下
Elasticsearch
Elasticsearch 通常被认为是搜索服务器,我们通常认为需要自己开发程序来实现搜索,然而, 搜索其实是可以独立成为一个搜索服务器来为应用程序服务的, Elasticsearch 就是用来提供专业 的搜索服务的产品。
从专业角度来讲, Elasticsearch 是一个 NoSQL 数据库,我们把数据存储在一个无模式的数 据存储中时,不能使用关系型的 SQL 来查找,然而, Elasticsearch 与其他 NoSQL 数据库不同, 它聚焦于搜索功能,我们通常是通过一个 阻STAPT 认 Elasticsearch 中完成搜索和查询的。
关于 Windows版本的ES,前面写过一个专栏:https://blog.csdn.net/soinice/article/category/8681409
这里只介绍,linux下ES的搭建与部署:
下载并解压
wget https://download.Elasticsearch.org/Elasticsearch/release/org/Elasticsearch/distr 工bution/zip/Elasticsearch/2.1.1/Elasticsearch-2.1.1.zip
unzip Elasticsearch-2.1.1.zip
cd Elasticsearch-2.1.1启动服务
bin/Elasticsearch为了确保服务启动成功,使用下面的 curl 语句查看服务的状态:
curl ’ http: //127.0.0.1:9200 ’ 我们看到如下结果,证明服务器启动成功:
{
”name”:”Bloodhawk”,
”cluster_name”:”Elasticsearch”,
’version”:{
”number”:”2 .1.1”,
”build_hash ”:”40e2c53a6b6c2972b3dl3846e450e66f4375bd71”,
"build_timestamp”:”2017-6-15T15:08:33Z” ,
”build_snapshot”: false ,
”lucene_version”:” 5 . 3.1 ”
},
” tag line”:”You Know , for Search"
}服务己经启动完成,可以在 Elasticsearch 中添加数据了,我们把这个过程称为索引,为数 据建立索引时,其内部使用 Apache Lucene 来实现。
Elasticsearch 对外提供RESTful 风格的 API, 所以可以使用 HTTP PUT 或者 POST 协议来执行索引数据的功能。 如果使用 PUT 协议, 则要指定 ID,但是如果用 POST 协议, Elasticsearch 则会为我们产生一个 ID。
POST协议:
PUT协议:

要进行索引的数据使用 JSON 格式,为什么我们没有定义数据的结构,就可以对数据进行索引呢?就像其他 NoSQL 数据库一样,我们不需要在 Elasticsearch 中提前建立数据结构或者模式,当然, 为了保证性能, 我们也可以这样做。
既然已经将数据在 Elasticsearch 中进行索引了,我们可以通过 阻ST削 风格的 API 将它取 出来:
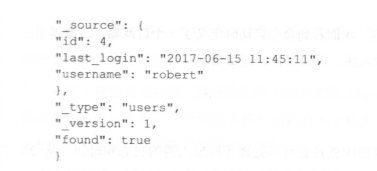
在上面命令的输出中,包含下画线的字段都是元数据字段,这个查询指定查找 ID 等于 4 的用户。
Logstash
ELK 最主要的场景是存储日志、可视化分析日志,以及处理其他基于时间顺序的数据。 Logstash 是这个流程中最主要的一个环节,负责把日志从日志源进行采集,然后存储到 Elasticsearch 中,它不仅可以帮助我们从不同的日志源采集日志,还可以过滤、处理和转换数据。 这里学习如何安装和使用 Logstash。
下载并解压
wget https://download.Elasticsearch. org/ logstash/logstash/logstash-1.4.2.tar.gz
tar zxvf logstash-1.4.2.tar.gz
cd logstash-1 .4. 2 启动服务
bin/logstash -e ’ input { stdin { I I output { stdout {} } ’ 在命令行下输入一些字符,将看到 Logstash 的输出内容:
hello logstash 2017-06-15T06:23: 21.405+0000 0.0.0 . 0 hello logstash 在上面的例子中,我们在运行 Logstash 的过程中定义了一个叫作 stdin 的数据源,还有一个 stdout 的输出目标,无论我们在命令行输入什么字符, Logstash 都会按照某种格式把数据打印到 我们的标准输出命令行中。
上面是一个最简单的 Logstash 示例,我们看到命令启动时定义了一个过滤器,过滤器里定 义了输入和输出,这里我们详细学习输入源、输出目标、过滤器。
Logstash 输入源
Logstash 得到广泛应用的一个主要原因就是它可以处理不同输入源的日志和时间。从 2.1 版本开始, Logstash 在文档中就包含了 48 个不同的输入源,通过这些输入源,我们可以从 48 个不同的技术枝、位置和服务来获取数据,包含监控系统 collectd、缓存系统 Redis、数据库系 统 MySQL,以及不同的文件系统、消息列队等。 通过这些输入源,我们能从不同的数据源导入 数据并管理数据,最终把处理后的数据发送到大数据存储和搜索系统。
我们首先需要配置输入源,如果在过滤器中不定义任何输入源,则默认的输入源就是命令 行的标准输入。 既然一次可以配置多个输入源,则我们最好对输入源进行分类和标记, 在过滤 器和输出中才能引用它们。
Logstash 输出目标
就像输入源一样, Logstash 有许多输出目标,通过这些输出目标,我们能够把日 志和时间 通过不同的技术发送到不同的位置和服务。我们也可以把事件输出到文本文件、 csv 文件和 S3 等分布式存储中,也能把它们转化成消息发送到消息系统,例如: Kafka、 RabbitMQ 等,或者 把它们发送到不同的监控系统和通知系统中,例如:短信、邮件和电话外呼等。不同的输入源 和输出目标的结合使 Logstash 成为了一个丰富的事件转换器。
既然 Logstash 能够处理来自多个输入源的事件,井可以使用多个过滤器,那么我们应该仔 细定义事件处理的输出目标,如果没有定义任何输出目标,则标准控制台输出是默认的输出目标。
Logstash 过滤器
如果 Logstah 仅仅是一个数据的管道,那么有很多可替代的技术来实现。 Logstash 的一大特点就是有丰富的过滤器,这些过滤器能够接收、处理、计算、测量事件等。
既然 Logstash 能够处理来自多个输入源的事件,以及可以使用多个输出,那么我们应该仔 细定义和配置事件的过滤器。
有了上面的基础知识,现在我们学习如何配置 Logstash。
首先 Logstash 的配置包含输入、 输出和过滤器三个段。
一个配置文件中可以有多个输入、输出和过滤器的实例,我们也可以把 它们分组井放到不同的配置文件中,例如:
- tomcat access file Elasticsearch.conf
- app_Elasticsearch.conf
- apache to Elasticsearch.conf下面是 apache_to_ Elasticsearch.conf配置文件的具体内容:
输入段告诉 Logstash 从 Apache 服务器产生的存取日志中拉取数据,并指定这些事件的类型为 apache-access。设置类型是非常重要的,因为后续我们需要根据类型来选择过滤器和输出, 类型最后也会用来在 Elasticsearch 中分类事件。
在过滤器段,我们详细声明了使用 grok 过滤器对 apache-access 类型的事件进行过滤。条件 判断 if [type] = ”apache-access”确保只有 apache-access 类型的事件才会被过滤。 如果没有这个条件判断,则 Logstash 会把其他类型的事件也应用到这个 grok 过滤器中。这个过滤器会解析 Apache 的日志行,然后组成 JSON 的日志格式。
最后,我们来看看输出段。第 1 个条件和上面过滤器的条件作用一样,确保我们只处理 apache-access 类型的事件。下面的一个条件针对我们识别不了的日志数据,假设我们不关心这 些日志数据,则简单地抛弃它们。过滤器里的顺序非常重要,在上面示例的配置中,必须是成 功解析的日志才能被存储到 Elasticsearch 中。
如果有多个配置文件,则我们在每个配置文件中都可以包含上面提到的三个段, Logstash 会把所有的配置文件组合到一起,形成一个大的配置文件。 既然可以配置多个输入源,则推荐 标记每个事件,并对每个事件分类,这样方便在后续的处理中引用:确保在定义输出段时使用 类型判断括起来,否则会出现不可思议的问题。
Kibana
Kibana 是一个基于浏览器页面的显示 Elasticsearch 数据的前端展示系统,使用 HTML 语言 和 JavaScript 实现,是为 Elasticsearch 提供日志分析的网页界面工具,可用它对日志进行高效汇 总、搜索、可视化、分析和查询等操作,可以与存储在 Elasticsearch 索引中的数据进行交互, 并执行高级的数据分析,然后以图表、表格和地图的形式查看数据。
Kibana 使得理解大容量的数据变得非常容易,它非常简单,基于浏览器的接口使我们能够 快速创建和分享显示 ES 查询结果的实时变化情况的仪表盘,所以,它的最大亮点是它的图表 和可视化展示能力。
关于 Windows 版本的,之前我写过一篇介绍:Kibana(安装篇):Windows下安装和运行Kibana
下载并解压
wget -c https://artifacts .elastic.co/downloads/kibana/kibana-5.4.0-linux-x86_64.tar.gz 下载后,将文件解压到/home/robert/working/softwares 文件夹下:
tar -zxvf kibana-4.5.0-linux-x86.tar.gz 修改位于 /home/robert/work,ing/so丘wares/kibana/config 中的配置文件,修改连接的
Elasticsearch 服务器:
Elasticsearch.url :”http://localhost:9200”
然后,通过下面的命令启动 kibana:
/home/robert/working/softwares/kibana/bin/kibana启动 Kibana 后,在浏览器中直接输入 http://localhost:5601,便可以在浏览器中查看 Kibana 所提供的分析功能了。初次进入需要至少创建一个索引模板,它对应 Elasticsearch 中的索引, 我们可以使用前面安装 Elasticsearch 时使用的 app 和 logs 索引 。 创建好索引模板后,在 Discover 的左边选择索引 app 或者 logs,在右上角选择时间,这样就可以看到日志了,左边可以选择要显示的列。
在 Discover 中的搜索框中输入查询公式进行查询,常用的基本语法如下:
- 直接在搜索框中输入关键字,所有字段只要包括就会被匹配, 比如输入一串手机号码;
- 如果是短语,则需要用双引号,中文是不会分词的,所以两个及以上的中文字的都算 短语;
- 可以用冒号指定某个字段包含某些关键字,对短语还是需要用引号;
- 非、与、或的组合逻辑;
- 组合用小括号;
- 必须包含及不可包含;
- 例如,必须来自 apache.log,但不是 6 月 15 日的时间范围:
source : (+”apache.log”-”2017-6-15”)其中 + 代表必须包含; - 代表不可包含;
- 例如,必须来自 apache.log,但不是 6 月 15 日的时间范围:
-
数字的范围(count 类型必须是数字);
-
例如:在 1 到 2 区间内查找 count 字段;
count : [1 TO 2)
-
-
通配符,与常用的一致
-
?:匹配单个字符;
-
*:匹配0到多个字符;
-
文章转载于:《分布式服务架构:原理、设计与实战》

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)