
mysql 按时间分组,然后再补上缺少的日期并将数据置为0
mysql 要按时间分组很简单,语法是select DATE_FORMAT(create_at, '%Y-%m-%d') day from user GROUP BY day结果如下但是可以发现日期是不连续的,根据某些业务场景,比如要绘制图表,不连续的日期肯定是不可以的,解决方法有很多。可以在业务代码里进行处理,但是个人感觉有些麻烦,在sql里解决的网上也查到一些方法,有...
mysql 要按时间分组很简单,语法是
select DATE_FORMAT(create_at, '%Y-%m-%d') day from user GROUP BY day
结果如下

但是可以发现日期是不连续的,根据某些业务场景,比如要绘制图表,不连续的日期肯定是不可以的,解决方法有很多。
可以在业务代码里进行处理,但是个人感觉有些麻烦,在sql里解决的网上也查到一些方法,有的是建立临时表,把从1970年开始的时间列表写进去,大约10万数据,感觉有点小题大做了。后来查到一个比较好的方法,现分享下:
SELECT data.day,IFNULL(data.count, 0), day_list.day as date from
(select DATE_FORMAT(create_at, '%Y-%m-%d') day, count(id) count from user GROUP BY day) data
right join
(SELECT @date := DATE_ADD(@date, interval 1 day) day from
(SELECT @date := DATE_ADD('2018-12-29', interval -1 day) from user)
days limit 28) day_list on day_list.day = data.day结果如下: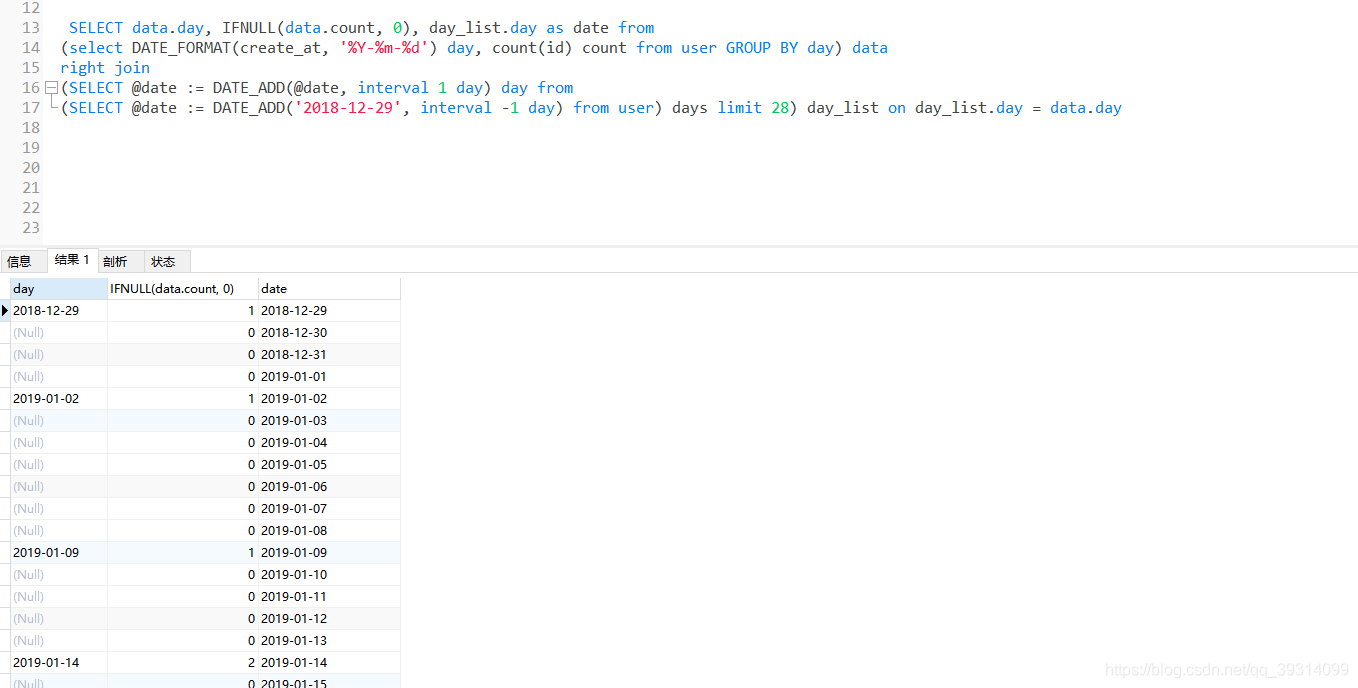
先普及一个知识,在mysql里:
= 和 := 的区别:
在update和set的时候没有区别,都是赋值的作用。:= 在select里也可以作为赋值来用。
所以分析sql:左边是具体的业务数据,右边是时间列表,我这里是取的开始时间升序排列,也可以填结束时间,然后降序排列。
主要说右边时间列表部分:先说第二个@date,这里是读取实际的业务表,然后在此同时给@date变量赋值,具体的值为我写入的规则,也就是我的查询开始时间的前一天,为什么这么写呢,因为在第一个@date那里要开始往后推导日期,为了将开始时间也推导出来,所以需要将这个起始选到前一天。需要注意的是,业务表总数据量应该大于要查询的天数,以便给变量赋值时候能对应上,否则可能会出现天数不够的情况。
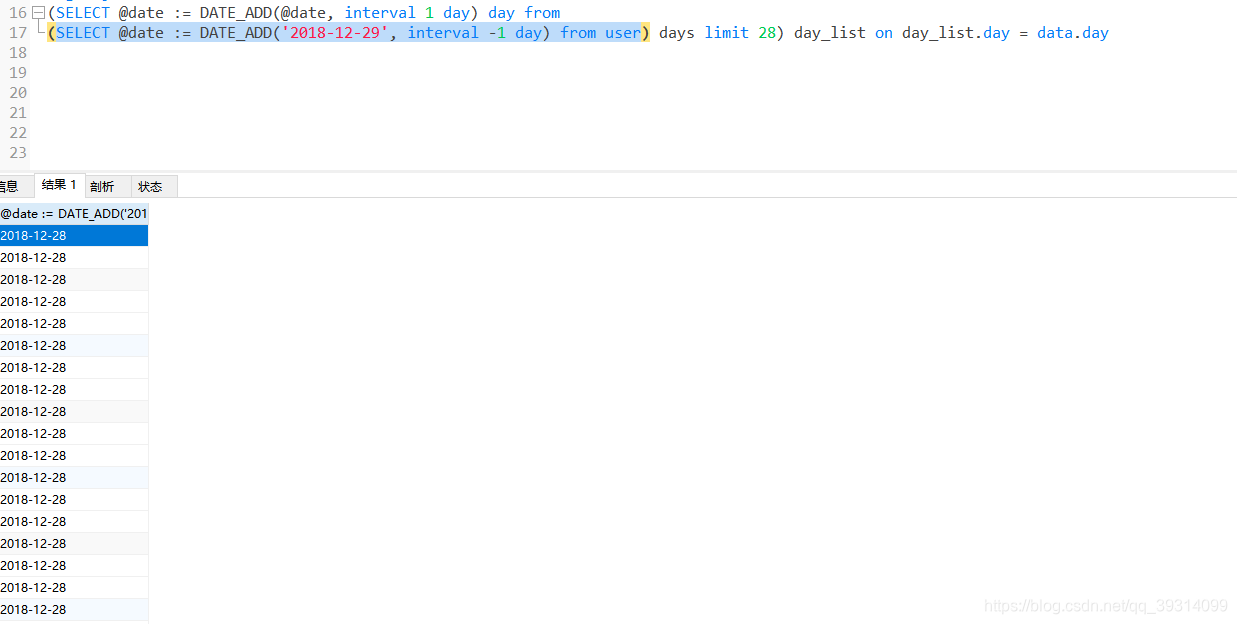
这是执行查询业务表并给变量赋值的结果,这里的条数是该业务表的条数,可以 limit 你需要的条数。此时会得到一个临时表,然后通过再一次的select 变量赋值的方法,select @date := 这个语法会对date变量赋值,比如第一个值会在dateadd函数下加一天变为,2018-12-29,此时@date变量也被赋予此值,在读取第二个值并赋值时,第二个值会变为2018-12-30,以此类推。即可得到我们想要的结果。
此时获取到想要的时间列表,然后跟实际的业务数据进行关联,让时间相等即可,此时可得到完整的时间对应数据关系,在实际业务数据里没有的日期则为空,我们置为0即可。

然后用ifnull函数处理即可。


无需安装部署,在线快速体验 Byzer
更多推荐
 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)