k8s-资源指标API及自定义指标API-二十三
一、原先版本是用heapster来收集资源指标才能看,但是现在heapster要废弃了。从k8s v1.8开始后,引入了新的功能,即把资源指标引入api;在使用heapster时,获取资源指标是由heapster自已获取的,heapster有自已的获取路径,没有通过apiserver,后来k8s引入了资源指标API(Metrics API),于是资源指标的数据就从k8s的api中的直接...
一、
原先版本是用heapster来收集资源指标才能看,但是现在heapster要废弃了。
从k8s v1.8开始后,引入了新的功能,即把资源指标引入api;
在使用heapster时,获取资源指标是由heapster自已获取的,heapster有自已的获取路径,没有通过apiserver,后来k8s引入了资源指标API(Metrics API),于是资源指标的数据就从k8s的api中的直接获取,不必再通过其它途径。
metrics-server: 它也是一种API Server,提供了核心的Metrics API,就像k8s组件kube-apiserver提供了很多API群组一样,但它不是k8s组成部分,而是托管运行在k8s之上的Pod。
为了让用户无缝的使用metrics-server当中的API,还需要把这类自定义的API,通过聚合器聚合到核心API组里,
然后可以把此API当作是核心API的一部分,通过kubectl api-versions可直接查看。
metrics-server收集指标数据的方式是从各节点上kubelet提供的Summary API 即10250端口收集数据,收集Node和Pod核心资源指标数据,主要是内存和cpu方面的使用情况,并将收集的信息存储在内存中,所以当通过kubectl top不能查看资源数据的历史情况,其它资源指标数据则通过prometheus采集了。
k8s中很多组件是依赖于资源指标API的功能 ,比如kubectl top 、hpa,如果没有一个资源指标API接口,这些组件是没法运行的;
资源指标:metrics-server
自定义指标: prometheus, k8s-prometheus-adapter
新一代架构:
- 核心指标流水线:由kubelet、metrics-server以及由API server提供的api组成;cpu累计利用率、内存实时利用率、pod的资源占用率及容器的磁盘占用率;
- 监控流水线:用于从系统收集各种指标数据并提供终端用户、存储系统以及HPA,他们包含核心指标以及许多非核心指标。非核心指标不能被k8s所解析;
metrics-server是一个api server,收集cpu利用率、内存利用率等。
二、metrics
(1)卸载上一节heapster创建的资源;

[root@master metrics]# pwd
/root/manifests/metrics
[root@master metrics]# kubectl delete -f ./
deployment.apps "monitoring-grafana" deleted
service "monitoring-grafana" deleted
clusterrolebinding.rbac.authorization.k8s.io "heapster" deleted
serviceaccount "heapster" deleted
deployment.apps "heapster" deleted
service "heapster" deleted
deployment.apps "monitoring-influxdb" deleted
service "monitoring-influxdb" deleted
pod "pod-demo" deleted
metrics-server在GitHub上有单独的项目,在kubernetes的addons里面也有关于metrics-server插件的项目yaml文件;
我们这里使用kubernetes里面的yaml:
metrics-server on kubernetes:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/metrics-server
将以下几个文件下载出来:

[root@master metrics-server]# pwd
/root/manifests/metrics/metrics-server
[root@master metrics-server]# ls
auth-delegator.yaml auth-reader.yaml metrics-apiservice.yaml metrics-server-deployment.yaml metrics-server-service.yaml resource-reader.yaml
需要修改一些内容:
目前metrics-server的镜像版本已经升级到metrics-server-amd64:v0.3.1了,此前的版本为v0.2.1,两者的启动的参数还是有所不同的。
[root@master metrics-server]# vim resource-reader.yaml
...
...
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- namespaces
- nodes/stats #添加此行
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- deployments
...
...
[root@master metrics-server]# vim metrics-server-deployment.yaml
...
...
containers:
- name: metrics-server
image: k8s.gcr.io/metrics-server-amd64:v0.3.1 #修改镜像(可以从阿里云上拉取,然后重新打标)
command:
- /metrics-server
- --metric-resolution=30s
- --kubelet-insecure-tls ##添加此行
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP #添加此行
# These are needed for GKE, which doesn't support secure communication yet.
# Remove these lines for non-GKE clusters, and when GKE supports token-based auth.
#- --kubelet-port=10255
#- --deprecated-kubelet-completely-insecure=true
ports:
- containerPort: 443
name: https
protocol: TCP
- name: metrics-server-nanny
image: k8s.gcr.io/addon-resizer:1.8.4 #修改镜像(可以从阿里云上拉取,然后重新打标)
resources:
limits:
cpu: 100m
memory: 300Mi
requests:
cpu: 5m
memory: 50Mi
...
...
# 修改containers,metrics-server-nanny 启动参数,修改好的如下:
volumeMounts:
- name: metrics-server-config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --cpu=80m
- --extra-cpu=0.5m
- --memory=80Mi
- --extra-memory=8Mi
- --threshold=5
- --deployment=metrics-server-v0.3.1
- --container=metrics-server
- --poll-period=300000
- --estimator=exponential
# Specifies the smallest cluster (defined in number of nodes)
# resources will be scaled to.
#- --minClusterSize={{ metrics_server_min_cluster_size }}
...
...
#创建
[root@master metrics-server]# kubectl apply -f ./
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
configmap/metrics-server-config created
deployment.apps/metrics-server-v0.3.1 created
service/metrics-server created
#查看,pod已经起来了
[root@master metrics-server]# kubectl get pods -n kube-system |grep metrics-server
metrics-server-v0.3.1-7d8bf87b66-8v2w9 2/2 Running 0 9m37s
[root@master ~]# kubectl api-versions |grep metrics
metrics.k8s.io/v1beta1
[root@master ~]# kubectl top nodes
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
#以下为pod中两个容器的日志
[root@master ~]# kubectl logs metrics-server-v0.3.1-7d8bf87b66-8v2w9 -c metrics-server -n kube-system
I0327 07:06:47.082938 1 serving.go:273] Generated self-signed cert (apiserver.local.config/certificates/apiserver.crt, apiserver.local.config/certificates/apiserver.key)
[restful] 2019/03/27 07:06:59 log.go:33: [restful/swagger] listing is available at https://:443/swaggerapi
[restful] 2019/03/27 07:06:59 log.go:33: [restful/swagger] https://:443/swaggerui/ is mapped to folder /swagger-ui/
I0327 07:06:59.783549 1 serve.go:96] Serving securely on [::]:443
[root@master ~]# kubectl logs metrics-server-v0.3.1-7d8bf87b66-8v2w9 -c metrics-server-nanny -n kube-system
ERROR: logging before flag.Parse: I0327 07:06:40.684552 1 pod_nanny.go:65] Invoked by [/pod_nanny --config-dir=/etc/config --cpu=80m --extra-cpu=0.5m --memory=80Mi --extra-memory=8Mi --threshold=5 --deployment=metrics-server-v0.3.1 --container=metrics-server --poll-period=300000 --estimator=exponential]
ERROR: logging before flag.Parse: I0327 07:06:40.684806 1 pod_nanny.go:81] Watching namespace: kube-system, pod: metrics-server-v0.3.1-7d8bf87b66-8v2w9, container: metrics-server.
ERROR: logging before flag.Parse: I0327 07:06:40.684829 1 pod_nanny.go:82] storage: MISSING, extra_storage: 0Gi
ERROR: logging before flag.Parse: I0327 07:06:40.689926 1 pod_nanny.go:109] cpu: 80m, extra_cpu: 0.5m, memory: 80Mi, extra_memory: 8Mi
ERROR: logging before flag.Parse: I0327 07:06:40.689970 1 pod_nanny.go:138] Resources: [{Base:{i:{value:80 scale:-3} d:{Dec:<nil>} s:80m Format:DecimalSI} ExtraPerNode:{i:{value:5 scale:-4} d:{Dec:<nil>} s: Format:DecimalSI} Name:cpu} {Base:{i:{value:83886080 scale:0} d:{Dec:<nil>} s: Format:BinarySI} ExtraPerNode:{i:{value:8388608 scale:0} d:{Dec:<nil>} s: Format:BinarySI} Name:memory}]
遗憾的是,pod虽然起来了,但是依然不能获取到资源指标;
由于初学,没有什么经验,网上查了一些资料,也没有解决;
上面贴出了日志,如果哪位大佬有此类经验,还望不吝赐教!
二、prometheus
metrics只能监控cpu和内存,对于其他指标如用户自定义的监控指标,metrics就无法监控到了。这时就需要另外一个组件叫prometheus;
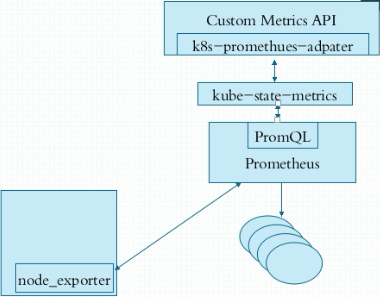
node_exporter是agent;
PromQL相当于sql语句来查询数据;
k8s-prometheus-adapter:prometheus是不能直接解析k8s的指标的,需要借助k8s-prometheus-adapter转换成api;
kube-state-metrics是用来整合数据的;
kubernetes中prometheus的项目地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
马哥的prometheus项目地址:https://github.com/ikubernetes/k8s-prom
1、部署node_exporter
[root@master metrics]# git clone https://github.com/iKubernetes/k8s-prom.git
[root@master metrics]# cd k8s-prom/
[root@master k8s-prom]# ls
k8s-prometheus-adapter kube-state-metrics namespace.yaml node_exporter podinfo prometheus README.md
#创建一个叫prom的名称空间
[root@master k8s-prom]# kubectl apply -f namespace.yaml
namespace/prom created
#部署node_exporter
[root@master k8s-prom]# cd node_exporter/
[root@master node_exporter]# ls
node-exporter-ds.yaml node-exporter-svc.yaml
[root@master node_exporter]# kubectl apply -f ./
daemonset.apps/prometheus-node-exporter created
service/prometheus-node-exporter created
[root@master ~]# kubectl get pods -n prom
NAME READY STATUS RESTARTS AGE
prometheus-node-exporter-5tfbz 1/1 Running 0 107s
prometheus-node-exporter-6rl8k 1/1 Running 0 107s
prometheus-node-exporter-rkx47 1/1 Running 0 107s
2、部署prometheus:
[root@master k8s-prom]# cd prometheus/
#prometheus-deploy.yaml文件中有限制使用内存的定义,如果内存不够用,可以将此规则删除;
[root@master ~]# kubectl describe pods prometheus-server-76dc8df7b-75vbp -n prom
0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 Insufficient memory.
[root@master prometheus]# kubectl apply -f ./
configmap/prometheus-config created
deployment.apps/prometheus-server created
clusterrole.rbac.authorization.k8s.io/prometheus created
serviceaccount/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
service/prometheus created
#查看prom名称空间下,所有资源信息
[root@master ~]# kubectl get all -n prom
NAME READY STATUS RESTARTS AGE
pod/prometheus-node-exporter-5tfbz 1/1 Running 0 15m
pod/prometheus-node-exporter-6rl8k 1/1 Running 0 15m
pod/prometheus-node-exporter-rkx47 1/1 Running 0 15m
pod/prometheus-server-556b8896d6-cztlk 1/1 Running 0 3m5s #pod起来了
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus NodePort 10.99.240.192 <none> 9090:30090/TCP 9m55s
service/prometheus-node-exporter ClusterIP None <none> 9100/TCP 15m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-node-exporter 3 3 3 3 3 <none> 15m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/prometheus-server 1/1 1 1 3m5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/prometheus-server-556b8896d6 1 1 1 3m5s
因为用的是NodePort,可以直接在集群外部访问:
浏览器输入:http://192.168.3.102:30090
192.168.3.102:为任意一个node节点的地址,不是master
生产环境应该使用pv+pvc的方式部署;
3、部署kube-state-metrics
[root@master k8s-prom]# cd kube-state-metrics/
[root@master kube-state-metrics]# ls
kube-state-metrics-deploy.yaml kube-state-metrics-rbac.yaml kube-state-metrics-svc.yaml
#创建,相关镜像可以去阿里云拉取,然后打标
[root@master kube-state-metrics]# kubectl apply -f ./
deployment.apps/kube-state-metrics created
serviceaccount/kube-state-metrics created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
service/kube-state-metrics created
[root@master ~]# kubectl get all -n prom
NAME READY STATUS RESTARTS AGE
pod/kube-state-metrics-5dbf8d5979-cc2pk 1/1 Running 0 20s
pod/prometheus-node-exporter-5tfbz 1/1 Running 0 74m
pod/prometheus-node-exporter-6rl8k 1/1 Running 0 74m
pod/prometheus-node-exporter-rkx47 1/1 Running 0 74m
pod/prometheus-server-556b8896d6-qk8jc 1/1 Running 0 48m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-state-metrics ClusterIP 10.98.0.63 <none> 8080/TCP 20s
service/prometheus NodePort 10.111.85.219 <none> 9090:30090/TCP 48m
service/prometheus-node-exporter ClusterIP None <none> 9100/TCP 74m
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-node-exporter 3 3 3 3 3 <none> 74m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kube-state-metrics 1/1 1 1 20s
deployment.apps/prometheus-server 1/1 1 1 48m
NAME DESIRED CURRENT READY AGE
replicaset.apps/kube-state-metrics-5dbf8d5979 1 1 1 20s
replicaset.apps/prometheus-server-556b8896d6 1 1 1 48m
4、部署k8s-prometheus-adapter
需要自制证书:
[root@master ~]# cd /etc/kubernetes/pki/
[root@master pki]# (umask 077; openssl genrsa -out serving.key 2048)
Generating RSA private key, 2048 bit long modulus
................+++
...+++
e is 65537 (0x10001)
创建:
#证书请求
[root@master pki]# openssl req -new -key serving.key -out serving.csr -subj "/CN=serving"
#签证:
[root@master pki]# openssl x509 -req -in serving.csr -CA ./ca.crt -CAkey ./ca.key -CAcreateserial -out serving.crt -days 3650
Signature ok
subject=/CN=serving
Getting CA Private Key
[root@master k8s-prometheus-adapter]# pwd
/root/manifests/metrics/k8s-prom/k8s-prometheus-adapter
[root@master k8s-prometheus-adapter]# tail -n 4 custom-metrics-apiserver-deployment.yaml
volumes:
- name: volume-serving-cert
secret:
secretName: cm-adapter-serving-certs #此处写了secret的名字,所以下面创建的时候要和这里一致
#创建加密的配置文件:
[root@master pki]# kubectl create secret generic cm-adapter-serving-certs --from-file=serving.crt=./serving.crt --from-file=serving.key=./serving.key -n prom
secret/cm-adapter-serving-certs created
[root@master pki]# kubectl get secrets -n prom
NAME TYPE DATA AGE
cm-adapter-serving-certs Opaque 2 23s
default-token-4jlsz kubernetes.io/service-account-token 3 17h
kube-state-metrics-token-klc7q kubernetes.io/service-account-token 3 16h
prometheus-token-qv598 kubernetes.io/service-account-token 3 17h
部署k8s-prometheus-adapter:
#这里需要去下载最新的custom-metrics-apiserver-deployment.yaml和custom-metrics-config-map.yaml
#先将现有目录中的文件移出去
[root@master k8s-prometheus-adapter]# mv custom-metrics-apiserver-deployment.yaml {,.bak}
#拉取两个文件
[root@master k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-apiserver-deployment.yaml
[root@master k8s-prometheus-adapter]# wget https://raw.githubusercontent.com/DirectXMan12/k8s-prometheus-adapter/master/deploy/manifests/custom-metrics-config-map.yaml
#把两个文件里面的namespace的字段值改成prom
#创建
[root@master k8s-prometheus-adapter]# kubectl apply -f ./
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/custom-metrics-auth-reader created
deployment.apps/custom-metrics-apiserver created
clusterrolebinding.rbac.authorization.k8s.io/custom-metrics-resource-reader created
serviceaccount/custom-metrics-apiserver created
service/custom-metrics-apiserver created
apiservice.apiregistration.k8s.io/v1beta1.custom.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/custom-metrics-server-resources created
configmap/adapter-config created
clusterrole.rbac.authorization.k8s.io/custom-metrics-resource-reader created
clusterrolebinding.rbac.authorization.k8s.io/hpa-controller-custom-metrics created
#查看
[root@master ~]# kubectl get all -n prom
NAME READY STATUS RESTARTS AGE
pod/custom-metrics-apiserver-c86bfc77-6hgjh 1/1 Running 0 50s
pod/kube-state-metrics-5dbf8d5979-cc2pk 1/1 Running 0 16h
pod/prometheus-node-exporter-5tfbz 1/1 Running 0 18h
pod/prometheus-node-exporter-6rl8k 1/1 Running 0 18h
pod/prometheus-node-exporter-rkx47 1/1 Running 0 18h
pod/prometheus-server-556b8896d6-qk8jc 1/1 Running 0 17h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/custom-metrics-apiserver ClusterIP 10.96.223.14 <none> 443/TCP 51s
service/kube-state-metrics ClusterIP 10.98.0.63 <none> 8080/TCP 16h
service/prometheus NodePort 10.111.85.219 <none> 9090:30090/TCP 17h
service/prometheus-node-exporter ClusterIP None <none> 9100/TCP 18h
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/prometheus-node-exporter 3 3 3 3 3 <none> 18h
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/custom-metrics-apiserver 1/1 1 1 53s
deployment.apps/kube-state-metrics 1/1 1 1 16h
deployment.apps/prometheus-server 1/1 1 1 17h
NAME DESIRED CURRENT READY AGE
replicaset.apps/custom-metrics-apiserver-c86bfc77 1 1 1 52s
replicaset.apps/kube-state-metrics-5dbf8d5979 1 1 1 16h
replicaset.apps/prometheus-server-556b8896d6 1 1 1 17h
[root@master ~]# kubectl get cm -n prom
NAME DATA AGE
adapter-config 1 60s
prometheus-config 1 17h
可以看到资源都起来了;
#查看api
[root@master ~]# kubectl api-versions |grep custom
custom.metrics.k8s.io/v1beta1 #此项已经有了
5、prometheus和grafana整合
1、获取grafana.yaml
2、修改yaml文件
[root@master metrics]# vim grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: prom #此处namespace改为prom
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: angelnu/heapster-grafana:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
#- name: INFLUXDB_HOST #注释此行
# value: monitoring-influxdb #注释此行
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: prom #此处namespace改为prom
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
type: NodePort #添加此行
selector:
k8s-app: grafana
3、创建grafana,整合Prometheus
[root@master metrics]# kubectl apply -f grafana.yaml
deployment.apps/monitoring-grafana created
service/monitoring-grafana created
[root@master metrics]# kubectl get pods -n prom |grep grafana
monitoring-grafana-8549b985b6-zghcj 1/1 Running 0 108s
[root@master metrics]# kubectl get svc -n prom |grep grafana
monitoring-grafana NodePort 10.101.124.148 <none> 80:31808/TCP 118s #此处为NodePort,外部直接访问31808端口
grafana运行在node02上了:
[root@master pki]# kubectl get pods -n prom -o wide |grep grafana
monitoring-grafana-8549b985b6-zghcj 1/1 Running 0 27m 10.244.2.58 node02 <none> <none>
在外部浏览器打开:

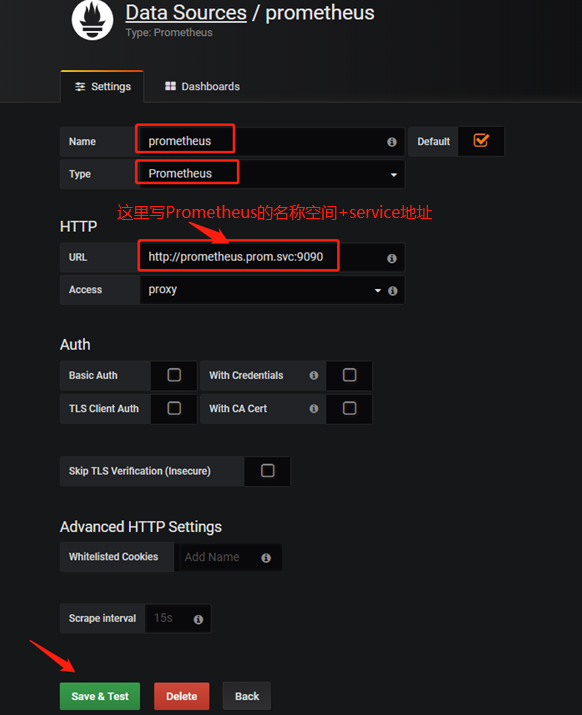
[root@master ~]# kubectl get svc -n prom -o wide |grep prometheus
prometheus NodePort 10.111.85.219 <none> 9090:30090/TCP 41h app=prometheus,component=server
然后修改框住的内容:
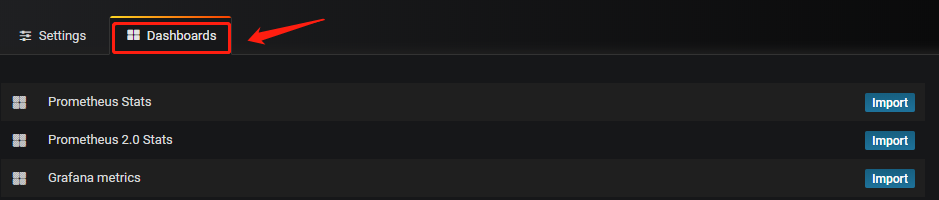
以上通过以后,点击“Dashboards”,将三个模板都导入;
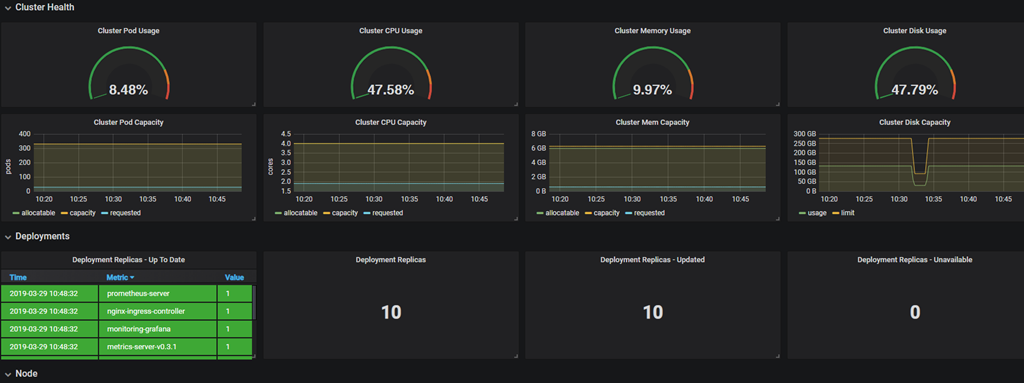
如下图,已经有些监控数据了:

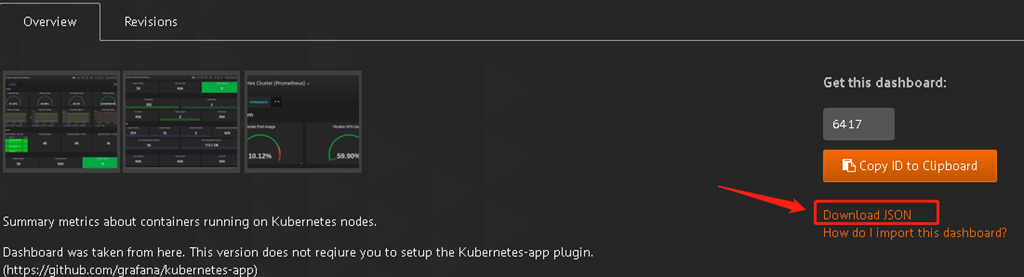
也可以去下载一些模板:
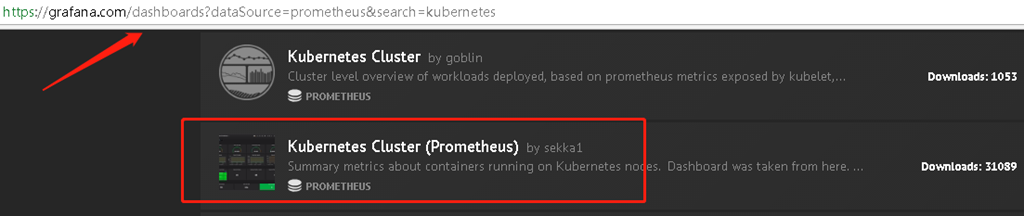
https://grafana.com/dashboards
https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
![]()
然后导入:
三、HPA(水平pod自动扩展)
(1)
Horizontal Pod Autoscaling可以根据CPU利用率(内存为不可压缩资源)自动伸缩一个Replication Controller、Deployment 或者Replica Set中的Pod数量;
目前HPA只支持两个版本,其中v1版本只支持核心指标的定义;
[root@master ~]# kubectl api-versions |grep autoscaling
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
(2)下面我们用命令行的方式创建一个带有资源限制的pod
[root@master ~]# kubectl run myapp --image=ikubernetes/myapp:v1 --replicas=1 --requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' --labels='app=myapp' --expose --port=80
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
service/myapp created
deployment.apps/myapp created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-657fb86dd-nkhhx 1/1 Running 0 56s
(3)下面我们让myapp 这个pod能自动水平扩展,用kubectl autoscale,其实就是创建HPA控制器的;
#查看帮助
[root@master ~]# kubectl autoscale -h
#创建
[root@master ~]# kubectl autoscale deployment myapp --min=1 --max=8 --cpu-percent=60
horizontalpodautoscaler.autoscaling/myapp autoscaled
--min:表示最小扩展pod的个数 --max:表示最多扩展pod的个数
--cpu-percent:cpu利用率
#查看hpa
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp Deployment/myapp 0%/60% 1 8 1 64s
[root@master ~]# kubectl get svc |grep myapp
myapp ClusterIP 10.107.17.18 <none> 80/TCP 7m46s
#把service改成NodePort的方式:
[root@master ~]# kubectl patch svc myapp -p '{"spec":{"type": "NodePort"}}'
service/myapp patched
[root@master ~]# kubectl get svc |grep myapp
myapp NodePort 10.107.17.18 <none> 80:31043/TCP 9m
接着可以对pod进行压测,看看pod会不会扩容:
#安装ab压测工具
[root@master ~]# yum -y install httpd-tools
#压测
[root@master ~]# ab -c 1000 -n 50000000 http://192.168.3.100:31043/index.html
#压测的同时,可以看到pods的cpu利用率为102%,需要扩展为2个pod了:
[root@master ~]# kubectl describe hpa |grep -A 3 "resource cpu"
resource cpu on pods (as a percentage of request): 102% (51m) / 60%
Min replicas: 1
Max replicas: 8
Deployment pods: 1 current / 2 desired
#已经扩展为两个pod了
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-657fb86dd-k4jdg 1/1 Running 0 62s
myapp-657fb86dd-nkhhx 1/1 Running 0 110m
#等压测完,cpu使用率降下来,pod数量还会自动恢复为1个,如下
[root@master ~]# kubectl describe hpa |grep -A 3 "resource cpu"
resource cpu on pods (as a percentage of request): 0% (0) / 60%
Min replicas: 1
Max replicas: 8
Deployment pods: 1 current / 1 desired
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-657fb86dd-nkhhx 1/1 Running 0 116m
#但是如果cpu使用率还是一直上升,pod数量会扩展的更多
(4)hpa v2
上面用的是hpav1来做的水平pod自动扩展的功能,hpa v1版本只能根据cpu利用率括水平自动扩展pod。
接下来我们看一下hpa v2的功能,它可以根据自定义指标利用率来水平扩展pod。
#删除刚才的hpa
[root@master ~]# kubectl delete hpa myapp
horizontalpodautoscaler.autoscaling "myapp" deleted
#hpa-v2资源定义清单
[root@master hpav2]# vim hpa-v2-demo.yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-v2
spec:
scaleTargetRef: #根据什么指标来做评估压力
apiVersion: apps/v1 #对谁来做自动扩展
kind: Deployment
name: myapp
minReplicas: 1 #最少副本数量
maxReplicas: 10 #最多副本数量
metrics: #表示依据哪些指标来进行评估
- type: Resource #表示基于资源进行评估
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 #pod cpu使用率超过55%,就自动水平扩展pod个数
#创建
[root@master hpav2]# kubectl apply -f hpa-v2-demo.yaml
horizontalpodautoscaler.autoscaling/myapp-hpa-v2 created
[root@master ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
myapp-hpa-v2 Deployment/myapp <unknown>/50% 1 10 0 9s
接着可以对pod进行压测,看看pod会不会扩容:
[root@master hpav2]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-657fb86dd-nkhhx 1/1 Running 0 3h16m
#压测
[root@master ~]# ab -c 1000 -n 80000000 http://192.168.3.100:31043/index.html
#看到cpu使用率已经到了100%
[root@master ~]# kubectl describe hpa |grep -A 3 "resource cpu"
resource cpu on pods (as a percentage of request): 100% (50m) / 50%
Min replicas: 1
Max replicas: 10
Deployment pods: 1 current / 2 desired
#pod已经自动扩容为两个了
[root@master hpav2]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-657fb86dd-fkdxq 1/1 Running 0 27s
myapp-657fb86dd-nkhhx 1/1 Running 0 3h19m
#等压测结束后,资源使用正常一段时间后,pod个数还会收缩为正常个数;
(5)hpa v2可以根据cpu和内存使用率进行伸缩Pod个数,还可以根据其他参数进行pod处理,如http并发量
[root@master hpa]# vimt hpa-v2-custom.yaml apiVersion: autoscaling/v2beta2 #从这可以看出是hpa v2版本
kind: HorizontalPodAutoscaler
metadata: name: myapp-hpa-v2
spec: scaleTargetRef: #根据什么指标来做评估压力 apiVersion: apps/v1 #对谁来做自动扩展 kind: Deployment name: myapp minReplicas: 1 #最少副本数量 maxReplicas: 10 metrics: #表示依据哪些指标来进行评估 - type: Pods #表示基于资源进行评估 pods: metricName: http_requests #自定义的资源指标 targetAverageValue: 800m #m表示个数,表示并发数800
hpa-v2版本的,有需要以后可以深入学习一下;

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)