exploring generalization indeep learing
exploring generalization indeep learingAbstract1 IntroductionNotation2 Generalization and Capacity Control in Deep Learning2.1 Network Size2.2 Norms and MarginsLipschitz continuity and robustne...
exploring generalization indeep learing
Abstract
1 Introduction
Notation
2 Generalization and Capacity Control in Deep Learning
2.1 Network Size
2.2 Norms and Margins
Lipschitz continuity and robustness
2.3 Sharpness
3 Empirical Investigation
Different Global Minima
4 Conclusion**
-
论文会议介绍
31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach洛杉矶县长滩市, CA加利福尼亚州, USA.
神经信息处理系统大会,是一个关于机器学习和计算神经科学的国际会议。该会议固定在每年的12月举行,由NIPS基金会主办。NIPS是机器学习领域的顶级会议,神经计算方面最好的会议之一 。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议,论文录取率约25% -
Abstract
文章从三个方面考虑了什么影响网络的泛化
1 norm_based control
2 sharpness
3 robustness(几乎没有)
(4)PAC-Bayes theory -
Introduction
因为网络中的参数非常多,所以可能有多个全局最小点都能让训练误差达到0,但并不是所有的全局最小点都有很好的泛化能力。泛化能力取决于算法,算法又有很多影响因素,如初始值,更新规则,学习率,停止条件等,即他们都会影响找到哪个全局最小从而影响泛化。【12】也提了。
【12】随机梯度下降的小minibatch比大minibatch有更好的泛化能力。
这些算法选择对神经网络的偏差是什么?是什么确保了神经网络的泛化?复杂性或容量控制的相关概念是什么?
【2】建议采用不同的网络参数norm来衡量神经网络的容量。
【12】建议用sharpness(robustness of the training error to perturbations in the parameters训练误差对参数扰动的鲁棒性)
【13】【8】建议PAC-Bayes
什么使复杂性度量complexity measure适合解释深度学习中的泛化?
1 complexity measure应该保证generalization
2 在此measure下,实践中学习的网络应该具有较低的复杂性。
complexity measure应该有助于解释:
1达到0训练误差的前提下,真实标签学习的网络比使用随机标签学习的相同结构网络具有更低的复杂度
2增加隐藏单元的数量,从而增加参数的数量,导致泛化误差的减少,complexity measure减少。
3相同网络结构、训练集,不同optimization methods达到0训练误差时,产生不同generalization时,我们要看complexity measure和generalization ability之间的关系
我们评估这些measures是基于它们在理论上保证泛化的能力,以及它们解释上述现象的能力。 -
notation
-
Generalization and Capacity Control in Deep Learning
有一块不知名的定义?
讨论complexity measures
1 是否足以generalization,分析 的capacity
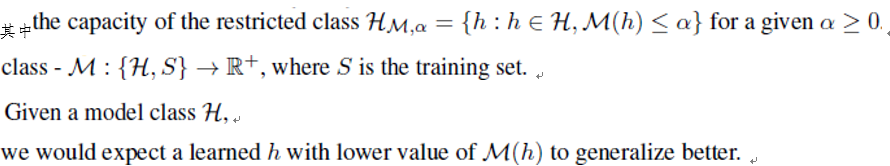
2 复杂性只有在特定的假设类H的上下文中才有意义
我们只获得一个非常粗糙的尺度为研究趋势和相对的现象,而不是一个量化的标准 -
Network Size
对于任何模型,如果它的参数具有有限的精度,它的容量在参数总数上是线性的。即使不假设参数的精度,前馈网络的VC维也可以用参数dim(w)个数来限定。在紧约束VC维上,用relu激活的前馈网络的capacity:
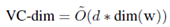
参数过多(参数数量大于样本数量)不能解释泛化,此外,用参数数量来度量复杂度并不能解释泛化误差随隐藏单元数量的增加而减少(参见图4&【30】)。 -
Norms and Margins



我们在真实标签和随机标签上比较复杂度,期望的结果:1真实的复杂度低,泛化好。2容量随训练集的增加线性增长,结果如上,l2norm 和l2 path normd 的 gap明显 纵轴是什么?
VGG网络,CIFAR10数据集,norm除以margin防止scale问题,都是训练到0误差
Gap也随着训练集的增大而增大
间隔越大越好,添加正规化条件:函数间隔/||w||=几何间隔 -
Lipschitz continuity and robustness
容量控制是通过李普希茨常数的界来实现的吗? 仅局限于Lipschitz常数就足以进行泛化了吗?
附录A? -
sharpness
【12】给的定义:sharpness对应于参数空间上的对抗扰动的鲁棒性(l-hat非常小)
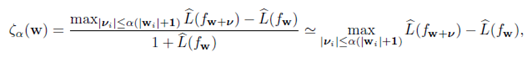
这样定义的sharpness不足以捕获泛化(之前解释了?)做以下实验证明
1在真实标签和随机标签上用sharpness预测网络的泛化行为见图2
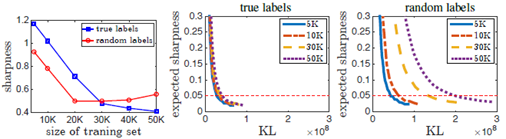
左按12的计算方法算出的max sharpness 中右期望sharpness和KL散度在PAC Bayes边界上的关系
Sharpness能在大网络上正确预测泛化行为,对于小网络真实标签的sharpness要好
Sharpness不足以控制网络的capacity:因为他的定义与w的scale有关,这是可以被手工调节的
如果不考虑缩放,锐度本身无法控制容量
图
ɛ=0.05时,使用随机标签训练的网络需要比使用真实标签训练的网络更高的范数。这种行为与我们之前的讨论一致,即锐度对参数的缩放非常敏感,而不是容量控制措施,因为它可以通过缩放网络来人为地改变。
PAC-Bayesian框架[16,17]对随机预测器(假设)的期望误差提供了保证,该随机预测器(假设)形成一个表示Q的分布
我们考虑一个分布Q除以权重为w+v的预测器
Fw从训练数据上学到的任何预测器
W从训练数据上学到的单一预测器
V随机变量
先验分布P
假设P在与训练数据无关的假设上有一个“先验”分布,fw+v的期望误差可以被限定为:
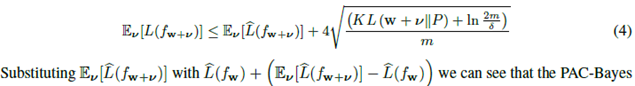
可以看到PAC-Bayes bound取决于1 sharpness 2先验p的KL散度
该界适用于任何分布测度P、任何扰动分布以及任何依赖于训练集选择w的方法。
上公式,增加范数会使锐度下降——找平衡来合理限制capacity
由于锐度和kl散度的精确结合方式并不紧密,所以我们宁愿避免在数值上优化锐度和kl散度之间的平衡。 -
Empirical Investigation
-
Different Global Minima
在相同的训练集和相同的模型类上,给定不同的全局训练损失最小值,这些度量方法是否能更好地泛化模型?
为验证,在几个不同的全局极小值上计算每个measure,并查看measure值越低是否意味着泛化误差越低。为了找到训练损失的不同全局极小值,我们设计了一个实验,通过形成一个包含随机标签样本的混淆集,迫使优化方法收敛到具有不同泛化能力的不同全局极小值。对损失进行优化,包括来自混淆集和训练集的示例。C10的子集上10000个,confusion sets(也来自c10)(随机标签怎么打)上不同大小,组成合集,训练都达到0误差。Vgg
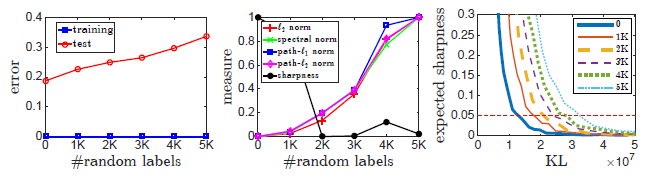
混淆集size增大,误差增大
范数可以预测泛化,sharpness能力很差
PAC-Bayes对联合锐度和KL散度的度量具有更好的行为。对于固定的期望锐度,具有更高泛化误差的网络具有更高的范数? -
Increasing Network Size
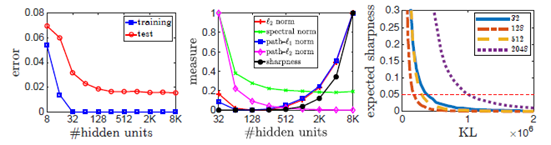
完全连接的前馈网络训练在MNIST数据集上,具有不同数量的隐藏单元,检查每个学习网络上不同复杂度度量的值
左32个隐藏单元足够匹配训练数据时,我们发现隐藏单元越多的网络泛化效果越好。
中,所有基于边界/规范的复杂性度量,对于更大的网络,减少到128个隐藏单元。对于隐藏单元较多的网络,“l2范数”和“l1path范数”随着网络规模的增大而增大。然而,正如我们在第2节中所讨论的,基于“l2path范数和谱范数”的实际复杂度度量也依赖于隐藏单元的数量,考虑到这一点,这些度量并不能解释这种现象。
右,PAC-Bayes联合方法测量了128个较大网络的下降量,但不能解释较大网络的这种泛化行为。
这表明,目前所观察到的方法不足以解释神经网络中观察到的所有泛化现象。 -
Conclusion
使用深度神经网络学习在实践中表现出良好的泛化行为,但这一现象在很大程度上仍无法解释。在本文中,我们讨论了可能解释神经网络泛化的不同复杂度度量。我们概述了研究这些措施的具体方法,并报告了研究这些措施如何很好地解释不同现象的实验。虽然目前还没有明确的选择,但预期的锐度和规范的某种组合似乎确实捕捉到了神经网络的大部分泛化行为。一个尚未解决的主要问题是,优化算法的选择是如何偏置这种复杂度的,以及优化和隐式正则化之间的精确关系是什么 -
附录vc维



-
附录PAC

-
附录kl散度


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)