

YOLOV3训练自己的数据集(VOC数据集格式)
包括内容:darknet yolov3的下载、配置、测试制作自己训练集标签(VOC数据集格式)在yolov3下训练自己的数据集验证训练结果,进行测试(一)darknet yolov3的下载、配置、测试:下载并配置yolo打开网址:https://pjreddie.com/darknet/yolo/,这是官网给出的使用及训练教程。下载yolo项目git clone https:.........
YOLOV3训练自己的数据集(VOC数据集格式)
包括内容:
- darknet yolov3的下载、配置、测试
- 制作自己训练集标签(VOC数据集格式)
- 在yolov3下训练自己的数据集
- 验证训练结果,进行测试
(一)darknet yolov3的下载、配置、测试:
下载并配置yolo
打开网址:https://pjreddie.com/darknet/yolo/,这是官网给出的使用及训练教程。
下载yolo项目
git clone https://github.com/pjreddie/darknet cd darknet make
下载完成后,会在自己电脑中生成darknet文件夹,打开darknet文件夹,找到Makefile文件进行编辑:
sudo gedit Makefile
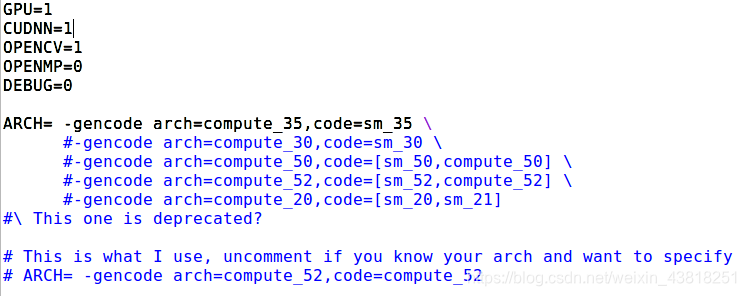
GPU、OPENCV、CUDNN 等根据自己的安装情况自行修改,如果不安装 OPENCV 后续将无法读取图片和视频。不使用 GPU 训练测试都会很慢。
我使用的GPU为Tesla K20m,所以选择对应的ARCH版本(实验室好点的显卡出现了问题,只能用老机器)。大家可以百度,或者在英伟达官网都会找到。这里有一个参考链接显卡对应的计算能力
make #修改完Makefile保存后,需要执行make才可以生效
对git的框架进行测试
先利用作者的权重,了解一下如何使用 yolo 测试图片
https://pjreddie.com/media/files/yolov3.weights 下载作者训练好的权重,可以直接做识别测试。
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
程序可以简化成:
./darknet detector test cfg/yolov3.cfg yolov3.weights data/dog.jpg
这里可以看到作者提供的测试结果:
制作自己训练集标签(VOC数据集格式)
我们对图片上的人进行了检测,只做了一个类别:person
推荐数据集标签制作工具:LabelImg

下载到的软件含有制作yolo数据集标签的选项,但初次训练yolo的时候,还是选择了制作VOC数据集的xml格式的标签

使用下面的 python或者matlab 脚本进行批量的重命名,格式是:000001.jpg 000002.jpg ……
图像尺寸进行修改,yolo训练的时候,图片最好尺寸变化区间不大,这样才有利于训练处效果更好的网络。所以在训练前,如果数据集不规范,需要对所有图片进行尺寸标准化处理。使图片统一到相同尺寸。
制作好标签后,在darknet/scripts文件夹内建立VOCdevkit文件夹,VOCdevkit文件夹内部文件形式如下
VOCdevkit
——VOC2018 #文件夹的年份可以自己取,但是要与你其他文件年份一致,看下一步就明白了
————Annotations #放入所有的xml文件
————ImageSets
——————Main #放入train.txt,val.txt文件
————JPEGImages #放入所有的图片文件
Main中的文件分别表示test.txt是测试集,train.txt是训练集,val.txt是验证集,trainval.txt是训练和验证集。
train.txt 和 test.txt 是需要自己建立的,里面存放训练集合测试集的图片名称,不包含后缀,每个名称占一行。
xml文件的形式
<annotation>
<folder>JPEGImages</folder>
<filename>00001.jpg</filename>
<path>/home/sxtj/darknet/scripts/VOCdevkit/VOC2019/JPEGImages/00001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>360</width>
<height>240</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>266</xmin>
<ymin>57</ymin>
<xmax>311</xmax>
<ymax>158</ymax>
</bndbox>
</object>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>322</xmin>
<ymin>34</ymin>
<xmax>355</xmax>
<ymax>124</ymax>
</bndbox>
</object>
</annotation>
在网上找到了对train.txt和test.txt进行划分的程序,代码如下:
import os
from os import listdir, getcwd
from os.path import join
if __name__ == '__main__':
source_folder='/home/sxtj/darknet/scripts/VOCdevkit/VOC2019/JPEGImages/'
dest='/home/sxtj/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/train.txt'
dest2='/home/sxtj/darknet/scripts/VOCdevkit/VOC2019/ImageSets/Main/test.txt'
file_list=os.listdir(source_folder)
train_file=open(dest,'a')
val_file=open(dest2,'a')
for file_obj in file_list:
file_path=os.path.join(source_folder,file_obj)
file_name,file_extend=os.path.splitext(file_obj)
print(file_name)
file_num=int(file_name)
if(file_num<140):
train_file.write(file_name+'\n')
else :
val_file.write(file_name+'\n')
train_file.close()
val_file.close()
划分完成以后,train.txt文件的形式如下:
官网上git下来的代码中包含了voc_label.py的python文件,把它放到和 VOCdevkit 同级的目录下。修改相关配置:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2019', 'train'), ('2019', 'test')]
classes = ["person"]
.
.
.
.
#os.system("cat 2019_train.txt 2019_val.txt > train.txt")
#os.system("cat 2019_train.txt 2019_val.txt > train.all.txt")
把程序的最后两行注释掉就行,运行voc_label.py文件,完事后在 VOCdevkit同级的目录下会生成2019_train.txt 和 2019_text.txt 两个文件,里面存有对应图片文件的绝对路径,训练时作为引用。
下面就可以训练网络啦!
在yolov3下训练自己的数据集
修改相关配置文件
在 darknet/data 目录下建立 myvoc.names 的文件(文件名无所谓,后缀得是.names),内容是类名:person

修改 cfg/voc.data 文件,修改后如下所示:
classes= 1
train = /home/sxtj/darknet/scripts/2019_train.txt
valid = /home/sxtj/darknet/scripts/2019_test.txt
names = data/myvoc.names
backup = /home/sxtj/darknet/backup
修改 cfg/yolov3-voc.cfg 文件(如果是 coco 数据集应该是 yolov3.cfg 文件):
主要是 filters 和 classes 的调整,文件前面的Testing和Training模式根据自己进行的方式进行选择,width和height根据自己训练的图片进行调整,但必须为32的倍数。控制训练的迭代次数为1000次:
[net]
# Testing
batch=1
subdivisions=1
# Training
#batch=64
#subdivisions=16#训练模式,每次前向的图片数目=batch/subdivisions
width=384#只能是32的倍数
height=256
channels=3
momentum=0.9#动量
decay=0.0005#权重衰减
angle=0
saturation = 1.5#饱和度
exposure = 1.5#曝光度
hue=.1#色调
learning_rate=0.001 #学习率
burn_in=1000#学习率控制的参数
max_batches = 1000#迭代次数
policy=steps
steps=40000,45000 #学习率变动不长
scales=.1,.1#学习率变动因子
........
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
......
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
......
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=1
num=9
jitter=.3
ignore_thresh = .5
truth_thresh = 1
random=1
其中:filters = 3x(classes数目+5)
训练!
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74(或者是上一次训练中途结束产生的.backup文件) -gpus 0,1 >> /home/cai/train_log.log
训练过程中,出现nan较多,可能是因为训练时batch设置过小造成~
生成检测结果
./darknet detector valid cfg/voc.data cfg/yolov3-voc.cfg weights/yolov3-voc_3.weights
在darknet/result文件夹下生成一个.txt文件
xmin,ymin,xmax,ymax
最终,我们检测结果如下:

参考:
YoLov3训练自己的数据集(小白手册)
YOLOv2训练:制作VOC格式的数据集
目标检测:YOLOv3: 训练自己的数据
YOLO网络中参数的解读

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)