
Java集合系列详解
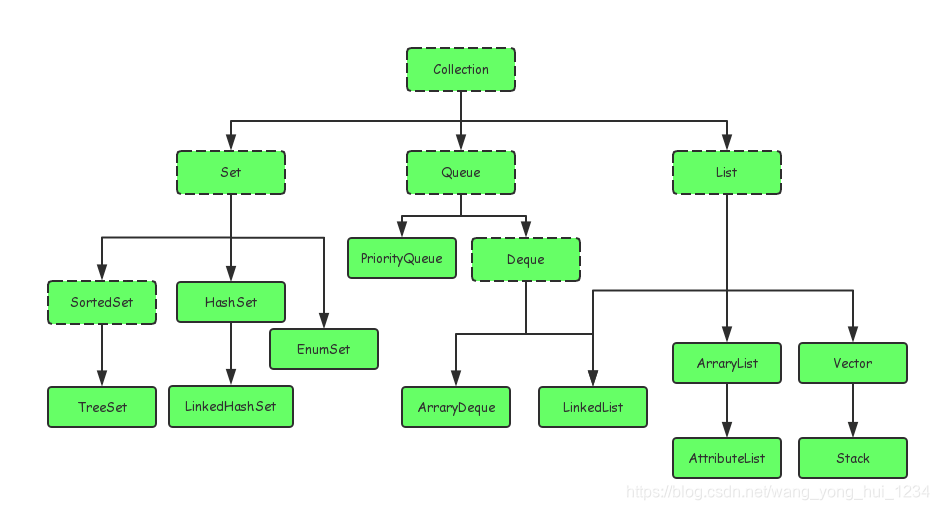
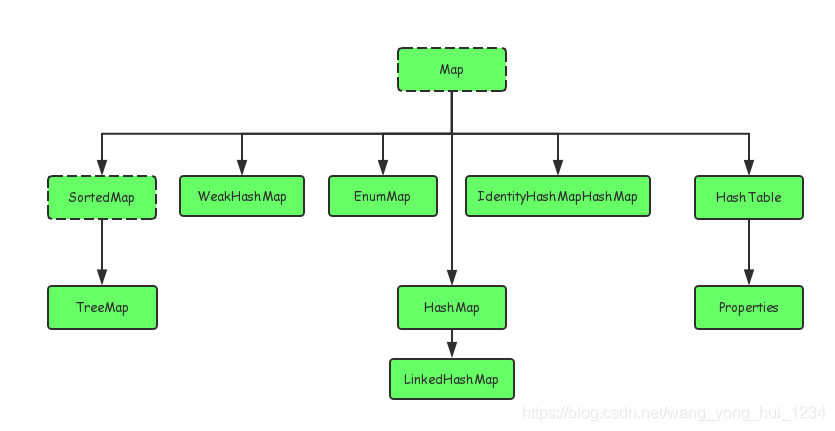
一,集合简介Java中的集合可以分为四种体系:List:代表有序、重复的集合Set:代表无序、不可重复的集合Map:代表具有映射关系的集合Queue:体系集合,代表一种队列集合实现二,Java集合类的关系Java中的集合类主要有两个接口派生:Collection和MapCollection类图如下:Map类图如下:三,Collection接口1,Set体系Set是一种...
这里写目录标题
前言
集合中的每个系列都有主要集合,把一个先搞明白,剩下的做个延伸,理解起来就很容易了。介绍过程中会讲解一些重要概念,包括一些数据结构算法,最后会形成思维导图,不管是以后面试还是开发再也不怕。**
在不同的jdk版本集合的算法和代码块有不同的变化,但基本原理和实现过程是相通的。
概念理解
集合的实现原理都基于数据结构和算法,先来简单了解一下。
数据结构:
- 线性表: 数组,链表(单链表,双链表),栈,队列(普通队列,双端队列)。
- 散列表: 散列函数(哈希算法)。
- 树: 平衡二叉树,二叉查找树,平衡二叉查找树(红黑树)。
算法:
- 排序算法: 冒泡排序,插入排序,选择排序,归并排序。
- 搜索: 深度优先搜索,广度优先搜索。
- 查找: 线性表查找,树结构查找,散列表查找。
集合简介
Java中的集合可以分为四种体系:
- List:代表有序、可重复的集合;
- Set:代表无序、不可重复的集合;
- Map:代表具有映射关系的集合;
- Queue:体系集合,代表一种队列集合实现;
Java集合类的关系
Java中的集合类主要有两个接口派生:Collection和Map
Collection类图如下:
Map类图如下:
一,List系列
List系列的核心集合是ArrayList,把ArrayList了解清楚后,别的进行对比理解,这样整个体系就串联起来了。
1.1 ArrayList
① ,基本介绍
- 无参构造默认长度为0,添加第一个元素时容量10,扩容后为原来1.5倍。
- 有参构造,如果指定长度则创建指定长度容量;
- 内部使用数组保存数据,查询快。
部分源码分析:
/**
* 默认长度10
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 默认 空数组实例
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* 默认 空数组实例与EMPTY ELEMENTDATA区分开,以了解添加*第一个元素时要膨胀多少
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 数组缓冲区,数组列表的元素被存储在其中
*/
transient Object[] elementData;
/**
* 集合长度
*/
private int size;
/**
* 有参构造,如果initialCapacity为0,elementData声明为空数组
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 无参构造
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
②,存储过程
add: 容量不足时,扩容为原来1.5倍。扩容就是数组的拷贝工作。
//这是添加元素的方法,size默认为0
public boolean add(E e) {
ensureCapacityInternal(size + 1);
//元素添加到集合 技术点:size++表示选赋值后加1,++size表示先加1后赋值。
elementData[size++] = e;
return true;
}
//来看ensureCapacityInternal方法
private void ensureCapacityInternal(int minCapacity) {
//如果是使用无参构造会进入到这里,那么minCapacity 值为10,因为第一次进来minCapacity是1,最大值就是DEFAULT_CAPACITY了。
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//最核心的grow方法
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
//如果第一次进入,minCapacity为10,条件成立,进行扩容。当集合数据存满后,继续扩容。
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容核心方法
private void grow(int minCapacity) {
//默认为零
int oldCapacity = elementData.length;
//oldCapacity >> 1 是位运算右移一位,相当于是除以2。所以从这里可以看出扩容后newCapacity 是原来的1.5倍。
//如果集合数据存满后,再次扩容newCapacity=10+5
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果是无参构造 第一次进入 newCapacity为0,minCapacity为10,条件成立
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//扩容开始 拷贝elementData数组为新数组,长度为newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
remove: 删除时如果不是最后一个元素,也需要拷贝数组进行移动位置。
//根据索引删除
public E remove(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
//拷贝数组
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
//根据对象删除
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
//遍历进行查找
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
set:
public E set(int index, E element) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
E oldValue = (E) elementData[index];
elementData[index] = element;
return oldValue;
}
get:
public E get(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
return (E) elementData[index];
}
③,总结
ArrayList内部是通过数组保存数据,数组是有序的,为了维护有序的地址,在添加和删除时需要做System.arraycopy拷贝工作。如果需要频繁进行添加删除操作时,就不太友好。
知识点
System.arraycopy() //native层方法 数组拷贝
1.2 LinkedList
① ,基本介绍
- 双向链表结构,Node中保存除了数据外还有前指针和后指针。
- 插入删除数据快,而查询数据慢。
- 链表不存在容量不足的问题,没有扩容机制。
部分源码:
//头节点指针
transient Node<E> first;
//尾节点指针
transient Node<E> last;
public LinkedList() {
}
//Node实例,next:上一个元素的指针;prev:下一个元素的指针。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
②,存储过程
add: 插入到链表头部和尾部时
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
remove: 删除头节点和尾结点
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
按对象删除,需要遍历节点
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
set 根据index修改元素,需要遍历元素
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
get 查询采用二分查找
//node方法用于查找当前节点
//判断index值是不是小于整个链表长度的一半,整个if/else逻辑是在判断查找的位置是距离链表头近还是链表尾近
Node<E> node(int index) {
//这里使用了二分查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
③,总结
LinkedList 底层是基于链表实现的,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的地址。更适合删除和添加。
1.3 知识点
二分查找
对于一组有序的数组,如果要查询对应的值,那么就需要循环遍历数组。假如这个数接近头部,那么很快就能遍历到,如果是接近尾部,则需要一直遍历到找到为止。
折半查找的意思就是每次查询的时候对数组折半。先定义三个指针,头,中,尾,拿需要查找的值和中间的进行比较,看是在左边还是在右边,如果在右边继续取中间位置,以此类推直到找到为止。

链表
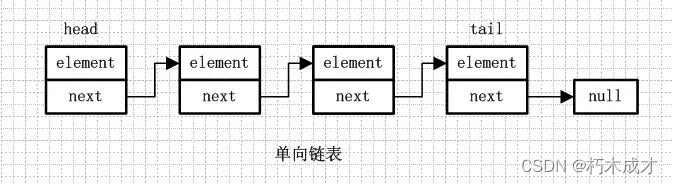
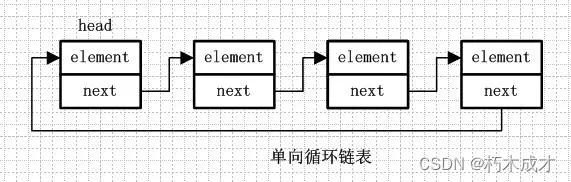
概念:链表是由一系列非连续的节点组成的存储结构,简单分下类的话,链表又分为单向链表和双向链表,而单向/双向链表又可以分为循环链表和非循环链表。
①.单向链表
单向链表就是通过每个结点的指针指向下一个结点从而链接起来的结构,最后一个节点的next指向null。
②.单向循环链表
单向循环链表和单向列表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。
③.双向链表
双向链表是包含两个指针的,pre指向前一个节点,next指向后一个节点,但是第一个节点head的pre指向null,最后一个节点的tail指向null。
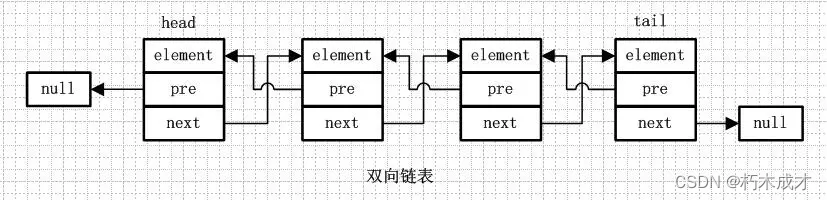
④.双向循环链表
双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。而LinkedList就是基于双向循环链表设计的。
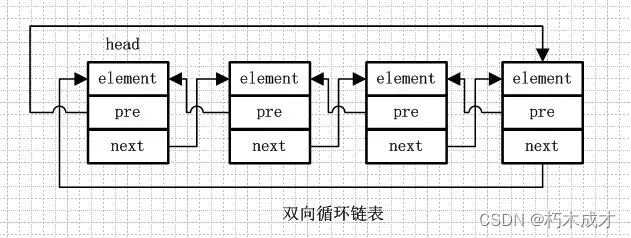
1.4 Vector
- 线程安全的,通过synchronized直接对方法加锁。
- 无参构造默认长度为10,扩容原来的两倍。
- 基本和ArrayList相同,在grow方法中扩容oldCapacity + ((capacityIncrement > 0) ?capacityIncrement : oldCapacity)。
1.5 SparseArray(安卓独有,轻量级集合)
① ,基本介绍
- 存储结构:采用两个数组,一个存储key(int类型),一个存储value。
- 有序的,基于二分查找,时间复杂度O(logN)。
- 默认容量是10,每次扩容之后大小为之前的2倍。
②,存储过程
remove: 延迟删除
remove方法主要做的就是这些,找到需要删除的key,并将对应的value用DELETED替换;但是key仍然存在于mKeys数组,因此删除是一个伪删除。这就是所谓的延迟删除机制。
public void delete(int key) {
//查找对应key在数组中的下标,如果存在,返回下标,不存在,返回下标的取反;
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//key存在于mKeys数组中,将元素删除,用DELETED替换原value,起标记作用;
if (i >= 0) {
if (mValues[i] != DELETED) {
mValues[i] = DELETED;
mGarbage = true;
}
}
}
binarySearch方法基于二分查找实现
static int binarySearch(int[] array, int size, int value) {
//lo为二分查找的左边界
int lo = 0;
//hi为二分查找的右边界
int hi = size - 1;
//还没找到,继续查找
while (lo <= hi) {
//左边界+右边界处以2,获取到mid 的index
final int mid = (lo + hi) >>> 1;
//获取中间元素
final int midVal = array[mid];
// 目标key在右部分
if (midVal < value) {
lo = mid + 1;
} else if (midVal > value) {
hi = mid - 1;
} else {
//相等,找到了,返回key对应在array的下标;
return mid; // value found
}
}
//没有找到该元素,对lo取反
return ~lo; // value not present
}
put:
由于设置了延迟删除且mValue[i]上当前的元素恰巧为DELETED,那么此时我们可以用当前的key替换原来mKeys的key,且用当前value替换DELETED;这样就成功避免了一次数组的迁移操作;
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
//原来已经有key,可能是remove后,value存放着DELETED,也可能是存放旧值,那么就替换
if (i >= 0) {
mValues[i] = value;
} else {
//没有找到,对i取反,得到i= lo(ContainerHelpers.binarySearch)
i = ~i;
//如果i小于数组长度,且mValues==DELETED(i对应的Key被延迟删除了)
if (i < mSize && mValues[i] == DELETED) {
//直接取代,实现真实删除原键值对
mKeys[i] = key;
mValues[i] = value;
return;
}
//数组中可能存在延迟删除元素且当前数组长度满,无法添加
if (mGarbage && mSize >= mKeys.length) {
//真实删除,将所有延迟删除的元素从数组中清除;
gc();
//清除后重新确定当前key在数组中的目标位置;
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
//不存在垃圾或者当前数组仍然可以继续添加元素,不需要扩容,则将i之后的元素全部后移,数组中仍然存在被DELETED的垃圾key;
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
//新元素添加成功,潜在可用元素数量+1
mSize++;
}
}
其中GrowingArrayUtils.insert主要做的就是调用System.arraycopy将数组后移,如果需要扩容则扩容;
public static int[] insert(int[] array, int currentSize, int index, int element) {
assert currentSize <= array.length;
if (currentSize + 1 <= array.length) {
System.arraycopy(array, index, array, index + 1, currentSize - index);
array[index] = element;
return array;
}
int[] newArray = ArrayUtils.newUnpaddedIntArray(growSize(currentSize));
System.arraycopy(array, 0, newArray, 0, index);
newArray[index] = element;
System.arraycopy(array, index, newArray, index + 1, array.length - index);
return newArray;
}
get: 二分查找
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
gc:
private void gc() {
//n代表gc前数组的长度;
int n = mSize;
int o = 0;
int[] keys = mKeys;
Object[] values = mValues;
for (int i = 0; i < n; i++) {
Object val = values[i];
//遍历元素,如果value不为DELETED,则用前数据放在o上,o的序号表示当前的有效元素下标。
//每遇到一次DELETED,则i-o的大小+1;
if (val != DELETED) {
//之后遇到非DELETED数据,则将后续元素的key和value往前挪
if (i != o) {
keys[o] = keys[i];
values[o] = val;
values[i] = null;
}
o++;
}
}
//此时无垃圾数据,o的序号表示mSize的大小
mGarbage = false;
mSize = o;
}
可以看到在循环遍历中,我们做的是将数组前移。因此会存在一个问题,即gc后有效数组长度为o,但是此时,keys.length可能会大于o,那么此时,最后的keys.length-o 个数组元素中仍然存在着key和value且不会消失;但是,由于mSize等于o,此时并不会访问到最后的多个废弃元素。只有在mSize数组范围内的DELETED数据才被称为延迟删除元素,mSize范围外的不会作为 被gc删除,只会被之后的put数组后移覆盖;
过程如下:
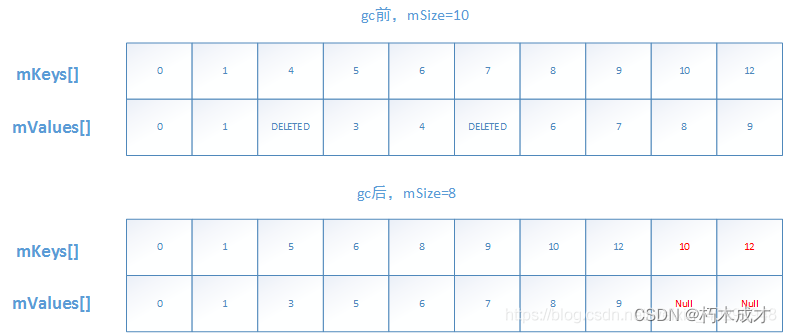
List系列已经介绍结束,最后形成思维导图。

二,Map系列
Map系列的核心是HashMap,也是常用的集合,面试常问需重点掌握。
2.1 HashMap
成员变量
//默认长度为16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//扩容因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
数组中的每一个元素为一个node,也就是链表的一个节点,node的数据包含: key的hashcode, key, value,指向下一个node节点的指针。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
...
}
随着put操作的进行,如果数组的长度超过64,且链表的长度大于8的时候, 则将链表转为红黑树,红黑树节点的结构如下:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
//...
}
①,基本介绍
- 主要用来存放键值对,默认长度是16,扩容因子0.75。
- 它是无序,线程不安全,key、value 都可以为 null,key是包装类型。
- jdk1.7采用头插法, 由 数组 + 链表 组成,链表是为了解决哈希冲突。
- jdk1.8采用尾插法,由数组+链表+红黑树。(红黑树条件:链表长度大于8,且数组长度大于64)。
②,存储过程
put:
先进行hash计算:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
核心代码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//声明了一个局部变量 tab,局部变量 Node 类型的数据 p,int 类型 n,i
Node<K,V>[] tab; Node<K,V> p; int n, i;
//首先将当前 hashmap 中的 table(哈希表)赋值给当前的局部变量 tab,然后判断tab 是不是空或者长度是不是 0,实际上就是判断当前 hashmap 中的哈希表是不是空或者长度等于 0
if ((tab = table) == null || (n = tab.length) == 0)
//如果是空的或者长度等于0,代表现在还没哈希表,所以需要创建新的哈希表,默认就是创建了一个长度为 16 的哈希表
n = (tab = resize()).length;
//将当前哈希表中与要插入的数据位置对应的数据取出来,(n - 1) & hash])就是找当前要插入的数据应该在哈希表中的位置,如果没找到,代表哈希表中当前的位置是空的,否则就代表找到数据了, 并赋值给变量 p
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//创建一个新的数据,这个数据没有下一条,并将数据放到当前这个位置
else {//代表要插入的数据所在的位置是有内容的
//声明了一个节点 e, 一个 key k
Node<K,V> e; K k;
if (p.hash == hash && //如果当前位置上的那个数据的 hash 和我们要插入的 hash 是一样,代表没有放错位置
//如果当前这个数据的 key 和我们要放的 key 是一样的,实际操作应该是就替换值
((k = p.key) == key || (key != null && key.equals(k))))
//将当前的节点赋值给局部变量 e
e = p;
else if (p instanceof TreeNode)//如果当前节点的 key 和要插入的 key 不一样,然后要判断当前节点是不是一个红黑色类型的节点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);//如果是就创建一个新的树节点,并把数据放进去
else {
//如果不是树节点,代表当前是一个链表,那么就遍历链表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//如果当前节点的下一个是空的,就代表没有后面的数据了
p.next = newNode(hash, key, value, null);//创建一个新的节点数据并放到当前遍历的节点的后面
if (binCount >= TREEIFY_THRESHOLD - 1) // 重新计算当前链表的长度是不是超出了限制
treeifyBin(tab, hash);//超出了之后就将当前链表转换为树,注意转换树的时候,如果当前数组的长度小于MIN_TREEIFY_CAPACITY(默认 64),会触发扩容,我个人感觉可能是因为觉得一个节点下面的数据都超过8 了,说明 hash寻址重复的厉害(比如数组长度为 16 ,hash 值刚好是 0或者 16 的倍数,导致都去同一个位置),需要重新扩容重新 hash
break;
}
//如果当前遍历到的数据和要插入的数据的 key 是一样,和上面之前的一样,赋值给变量 e,下面替换内容
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { //如果当前的节点不等于空,
V oldValue = e.value;//将当前节点的值赋值给 oldvalue
if (!onlyIfAbsent || oldValue == null)
e.value = value; //将当前要插入的 value 替换当前的节点里面值
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//增加长度
if (++size > threshold)
resize();//如果当前的 hash表的长度已经超过了当前 hash 需要扩容的长度, 重新扩容,条件是 haspmap 中存放的数据超过了临界值(经过测试),而不是数组中被使用的下标
afterNodeInsertion(evict);
return null;
}
扩容的方法:
final Node<K,V>[] resize() {
// 创建一个临时变量,用来存储当前的table
Node<K,V>[] oldTab = table;
// 获取原来的table的长度(大小),判断当前的table是否为空,如果为空,则把0赋值给新定义的oldCap,否则以table的长度作为oldCap的大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 创建临时变量用来存储旧的阈值,把旧table的阈值赋值给oldThr变量
int oldThr = threshold;
// 定义变量newCap和newThr来存放新的table的容量和阈值,默认都是0
int newCap, newThr = 0;
// 判断旧容量是否大于0
if (oldCap > 0) {
// 判断旧容量是否大于等于 允许的最大值,2^30
if (oldCap >= MAXIMUM_CAPACITY) {
// 以int的最大值作为原来HashMap的阈值,这样永远达不到阈值就不会扩容了
threshold = Integer.MAX_VALUE;
// 因为旧容量已经达到了最大的HashMap容量,不可以再扩容了,将阈值变成最大值之后,将原table返回
return oldTab;
}
// 如果原table容量不超过HashMap的最大容量,将原容量*2 赋值给变量newCap,如果newCap不大于HashMap的最大容量,并且原容量大于HashMap的默认容量
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将newThr的值设置为原HashMap的阈值*2
newThr = oldThr << 1; // double threshold
}
// 如果原容量不大于0,即原table为null,则判断旧阈值是否大于0
else if (oldThr > 0) // 如果原table为Null且原阈值大于0,说明当前是使用了构造方法指定了容量大小,只是声明了HashMap但是还没有真正的初始化HashMap(创建table数组),只有在向里面插入数据才会触发扩容操作进而进行初始化
// 将原阈值作为容量赋值给newCap当做newCap的值。由之前的源码分析可知,此时原阈值存储的大小就是调用构造函数时指定的容量大小,所以直接将原阈值赋值给新容量
newCap = oldThr;
// 如果原容量不大于0,并且原阈值也不大于0。这种情况说明调用的是无参构造方法,还没有真正初始化HashMap,只有put()数据的时候才会触发扩容操作进而进行初始化
else { // zero initial threshold signifies using defaults
// 则以默认容量作为newCap的值
newCap = DEFAULT_INITIAL_CAPACITY;
// 以初始容量*默认负载因子的结果作为newThr值
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 经过上面的处理过程,如果newThr值为0,说明上面是进入到了原容量不大于0,旧阈值大于0的判断分支。需要单独给newThr进行赋值
if (newThr == 0) {
// 临时阈值 = 新容量 * 负载因子
float ft = (float)newCap * loadFactor;
// 设置新的阈值 保证新容量小于最大总量 阈值要小于最大容量,否则阈值就设置为int最大值
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// 将新的阈值newThr赋值给threshold,为新初始化的HashMap来使用
threshold = newThr;
// 初始化一个新的容量大小为newCap的Node数组
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 将新创建的数组赋值给table,完成扩容后的新数组创建
table = newTab;
// 如果旧table不为null,说明旧HashMap中有值
if (oldTab != null) {
// 如果原来的HashMap中有值,则遍历oldTab,取出每一个键值对,存入到新table
for (int j = 0; j < oldCap; ++j) {
// 创建一个临时变量e用来指向oldTab中的第j个键值对,
Node<K,V> e;
// 将oldTab[j]赋值给e并且判断原来table数组中第j个位置是否不为空
if ((e = oldTab[j]) != null) {
// 如果不为空,则将oldTab[j]置为null,释放内存,方便gc
oldTab[j] = null;
// 如果e.next = null,说明该位置的数组桶上没有连着额外的数组
if (e.next == null)
// 此时以e.hash&(newCap-1)的结果作为e在newTab中的位置,将e直接放置在新数组的新位置即可
newTab[e.hash & (newCap - 1)] = e;
// 否则说明e的后面连接着链表或者红黑树,判断e的类型是TreeNode还是Node,即链表和红黑树判断
else if (e instanceof TreeNode)
// 如果是红黑树,则进行红黑树的处理。将Node类型的e强制转为TreeNode,之所以能转换是因为TreeNode 是Node的子类
// 拆分树,具体源码解析会在后面的TreeNode章节中讲解
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 当前节不是红黑树,不是null,并且还有下一个元素。那么此时为链表
else { // preserve order
/*
这里定义了五个Node变量,其中lo和hi是,lower和higher的缩写,也就是高位和低位,
因为我们知道HashMap扩容时,容量会扩到原容量的2倍,
也就是放在链表中的Node的位置可能保持不变或位置变成 原位置+oldCap,在原位置基础上又加了一个数,位置变高了,
这里的高低位就是这个意思,低位指向的是保持原位置不变的节点,高位指向的是需要更新位置的节点
*/
// Head指向的是链表的头节点,Tail指向的是链表的尾节点
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
// 指向当前遍历到的节点的下一个节点
Node<K,V> next;
// 循环遍历链表中的Node
do {
next = e.next;
/*
如果e.hash & oldCap == 0,注意这里是oldCap,而不是oldCap-1。
我们知道oldCap是2的次幂,也就是1、2、4、8、16...转化为二进制之后,
都是最高位为1,其它位为0。所以oldCap & e.hash 也是只有e.hash值在oldCap二进制不为0的位对应的位也不为0时,
才会得到一个不为0的结果。举个例子,我们知道10010 和00010 与1111的&运算结果都是 0010 ,
但是110010和010010与10000的运算结果是不一样的,所以HashMap就是利用这一点,
来判断当前在链表中的数据,在扩容时位置是保持不变还是位置移动oldCap。
*/
// 如果结果为0,即位置保持不变
if ((e.hash & oldCap) == 0) {
// 如果是第一次遍历
if (loTail == null)
// 让loHead = e,设置头节点
loHead = e;
else
// 否则,让loTail的next = e
loTail.next = e;
// 最后让loTail = e
loTail = e;
}
/*
其实if 和else 中做的事情是一样的,本质上就是将不需要更新位置的节点加入到loHead为头节点的低位链表中,将需要更新位置的节点加入到hiHead为头结点的高位链表中。
我们看到有loHead和loTail两个Node,loHead为头节点,然后loTail是尾节点,在遍历的时候用来维护loHead,即每次循环,
更新loHead的next。我们来举个例子,比如原来的链表是A->B->C->D->E。
我们这里把->假设成next关系,这五个Node中,只有C的hash & oldCap != 0 ,
然后这个代码执行过程就是:
第一次循环: 先拿到A,把A赋给loHead,然后loTail也是A
第二次循环: 此时e的为B,而且loTail != null,也就是进入上面的else分支,把loTail.next =
B,此时loTail中即A->B,同样反应在loHead中也是A->B,然后把loTail = B
第三次循环: 此时e = C,由于C不满足 (e.hash & oldCap) == 0,进入到了我们下面的else分支,其
实做的事情和当前分支的意思一样,只不过维护的是hiHead和hiTail。
第四次循环: 此时e的为D,loTail != null,进入上面的else分支,把loTail.next =
D,此时loTail中即B->D,同样反应在loHead中也是A->B->D,然后把loTail = D
*/
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 遍历结束,即把table[j]中所有的Node处理完
// 如果loTail不为空,也保证了loHead不为空
if (loTail != null) {
// 此时把loTail的next置空,将低位链表构造完成
loTail.next = null;
// 把loHead放在newTab数组的第j个位置上,也就是这些节点保持在数组中的原位置不变
newTab[j] = loHead;
}
// 同理,只不过hiHead中节点放的位置是j+oldCap
if (hiTail != null) {
hiTail.next = null;
// hiHead链表中的节点都是需要更新位置的节点
newTab[j + oldCap] = hiHead;
}
}
}
}
}
// 最后返回newTab
return newTab;
}
remove:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
......
// 找到目标节点了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 如果目标节点是红黑树
if (node instanceof TreeNode){
// 调用红黑树的删除节点方法
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
}
......
}
......
}
get:
首先计算key的hash,根据hash&(length-1)定位到Node数组中的一个下标。如果该下标的元素(也就是链表/红黑树的第一个元素)中 key的hash的key本身 都和传入的key相同,则证明找到了元素,直接返回即可。
如果第一个元素不是要找的,如果第一个元素的类型是TreeNode,则按照红黑树的查找方法查找元素,如果不是则证明是链表,按照next指针找下去,直到找到或者到达队尾。
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
③,总结
HashMap结构比较复杂,由于涉及到hash计算以及红黑树,需要维护的元素比较多,不适合数据量小的场景,因为开销大。
2.2 知识点
位运算
- 位与(&):二元运算符,两个为1时结果为1,否则为0。
- 位或(|):二元运算符,两个其中有一个为1时结果就为1,否则为0。
- 位异或(^):二元运算符,两个数同时为1或0时结果为1,否则为0。
- 位取非(~):一元运算符,取反操作。
- 左移(<<):一元运算符,按位左移一定的位置。高位溢出,低位补符号位,符号位不变。
- 右移(>>):一元运算符,按位右移一定的位置。高位补符号位,符号位不变,低位溢出。
- 无符号右移(>>>):一元运算符,符号位(即最高位)保留,其它位置向右移动,高位补零,低位溢出。
红黑树
二叉树结构如下图:
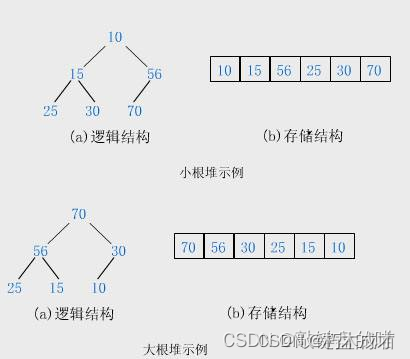
规定:对于任意一个结点,其左子树的值必定小于该结点,其右子树的值必定大于该结点。那么遍历的时候,就是有序的了。理论上来说,增加,删除,修改的时间复杂度都是O(log(N)) 。但是它存在一个致命的问题,存在退化成链表的情况,如下图:
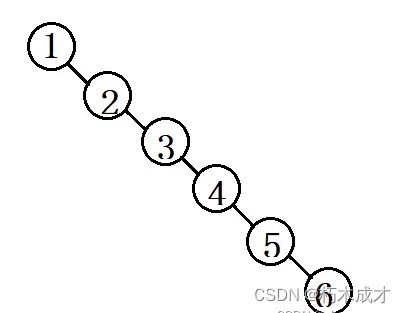
因此平衡二叉树(简称:AVL Tree)出现如下图:
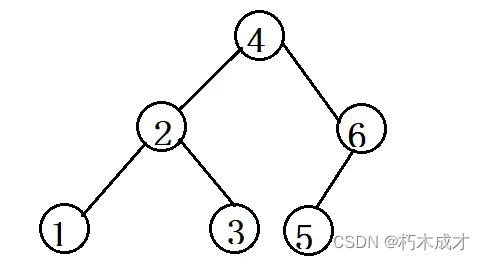
左右两个子树的高度差的绝对值不超过1。那么AVL Tree是如何保证平衡的呢,是通过旋转,可以看到,无论是插入还是删除元素,都要去通过旋转维护整个树的平衡。
- AVL查询元素:O(log(N))。
- AVL插入元素:最多一次旋转O(1),加上查询的时间O(log(N)),插入的复杂度O(log(N))。
- AVL删除元素:必须检查从删除结点开始到根结点路径上的所有结点的平衡因子。因此删除的代价比较大,删除最多需要log(N)次旋转,加上查询的时间,删除的复杂度O(2log(N))。
由于平衡二叉树定义太为严格,需要维持平衡需要的成本高。因此红黑树出现了。
红黑树的定义:
- 节点不是红色就是黑色,根节点是黑色。
- 红黑树的叶子节点并非传统的叶子节点,红黑树的叶子节点是null节点(空节点)且为黑色。
- 同一路径,不存在连续的红色节点。最长路径不会超过最短路径的2倍。
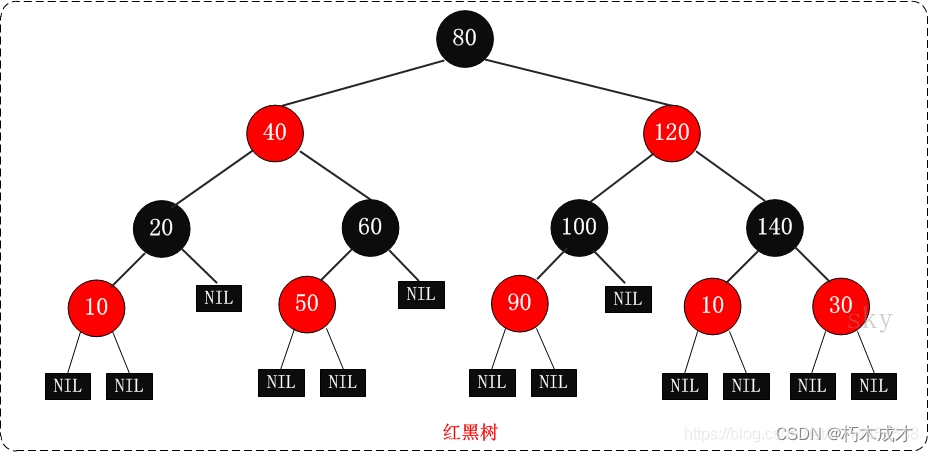 在添加和删除的时候为了维持树的平衡需要进行左旋或右旋操作。
在添加和删除的时候为了维持树的平衡需要进行左旋或右旋操作。
左旋

如上图所示,当在某个目标结点 E 上,做左旋操作时,我们假设它的右孩子 S 不是 NIL。
左旋以 S 到 E 之间的链为“支轴”进行,它使 S 成为该子树的新根,而 S 的左孩子则成为 E 的右孩子。
右旋

同左旋类似,当在某个目标结点 S 上,做右旋操作时,我们假设它的右孩子 S 不是 NIL。
左旋以 S 到 E 之间的链为“支轴”进行,它使 S 成为该子树的新根,而 S 的左孩子则成为 E 的右孩子。
2.3 LinkedHashMap
在了解完HashMap后,再看LinkedHashMap就比较容易了,因为内部也是基于HashMap实现的。
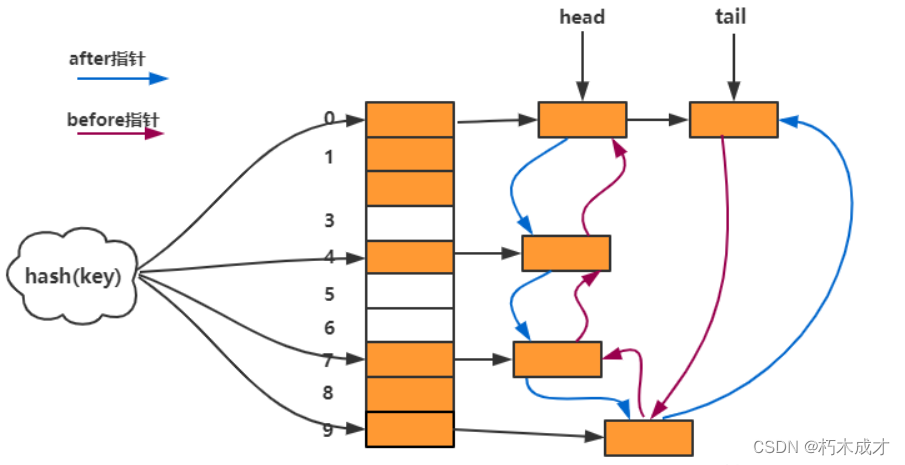
- 存储结构:HashMap+双向链表。有头结点head,尾结点tail。
- 有序数组,分为插入顺序和访问顺序。
成员变量
//集合的头部
transient LinkedHashMapEntry<K,V> head;
//集合的尾部
transient LinkedHashMapEntry<K,V> tail;
节点存储结构,before上个节点,after下个节点
static class LinkedHashMapEntry<K,V> extends HashMap.Node<K,V> {
LinkedHashMapEntry<K,V> before, after;
LinkedHashMapEntry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
2.4 ConcurrentHashMap
①,基本介绍
- 线程安全的,键值对不能为null,存储实现和HashMap基本一致。
- jdk1.7:数组+链表+分段锁。Segment包含HashEntry,Segment继承了ReentrantLock,默认有16个Segment。不同的线程通过hashcode找到对应的segment,多个线程操作同一个segment时通过加锁。
- jdk1.8:数组+链表+红黑树+乐观锁+synchronized。大量的使用CAS(compare and swap)操作,CAS是比较交换,是一种乐观锁。
②,核心原理
存储实现和HashMap基本一致,主要看线程安全部分。
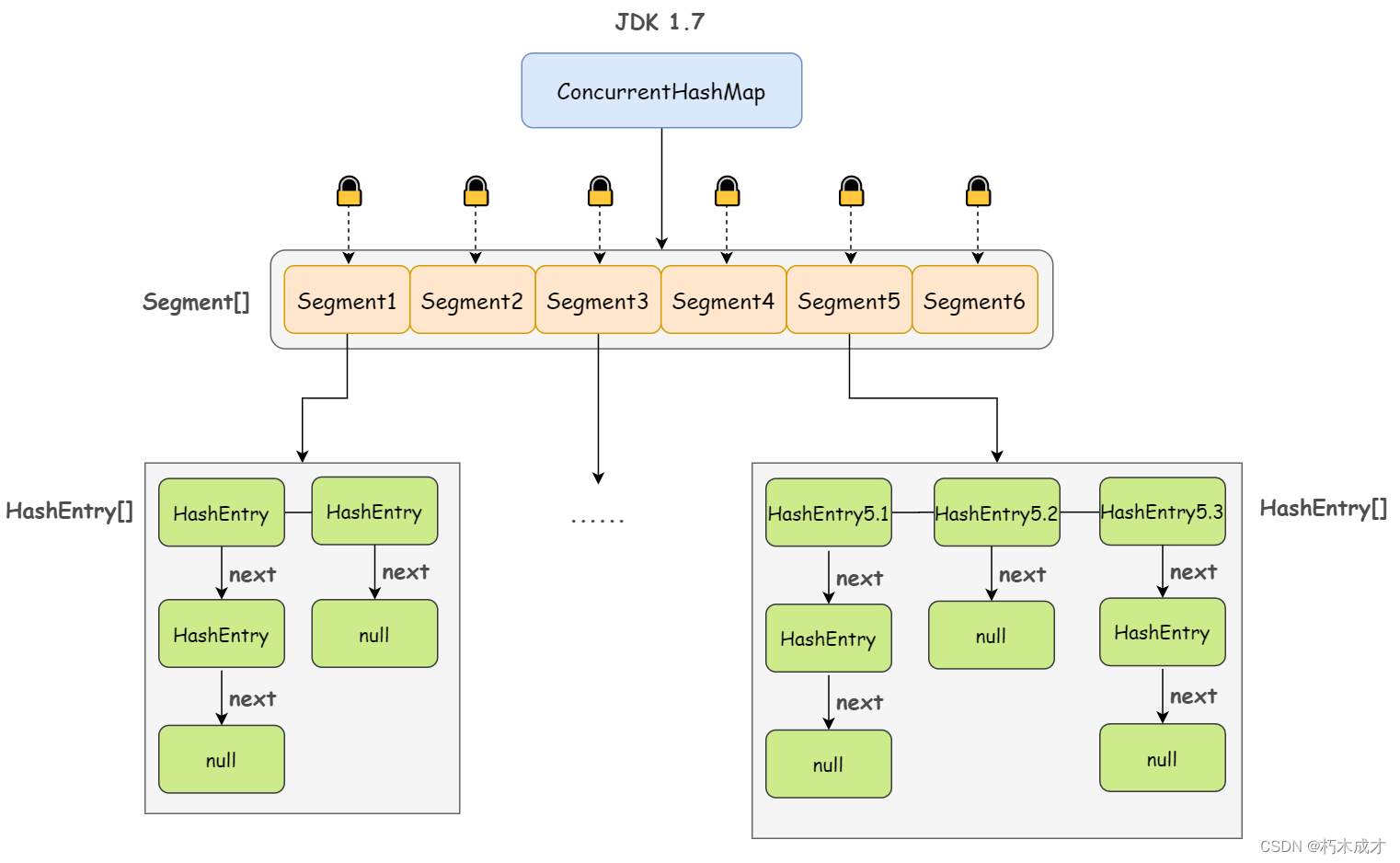
JDK1.7: 采用分段锁实现线程安全,基于Segment+HashEntry数组实现的,默认有16个区段 Segment。Segment是ReentrantLock的子类,而其内部也维护了一个Entry数组,这个Entry数组和HashMap中的Entry数组是一样的。所以说Segment其实是一个锁,可以锁住一段哈希表结构。在多线程操作时,首先通过hash计算找到对应的Segment,不同的线程操作不同的Segment;如果多个线程同时操作同一个Segment就进行加锁等待。
分段锁实现原理图
 JDK1.8: 两个线程给同一个区段Segment中添加元素,这种情况不可以并发, 这样JDK1.8进行了改进,没有区段了,数组+链表+红黑树 +乐观锁 + synchronized。
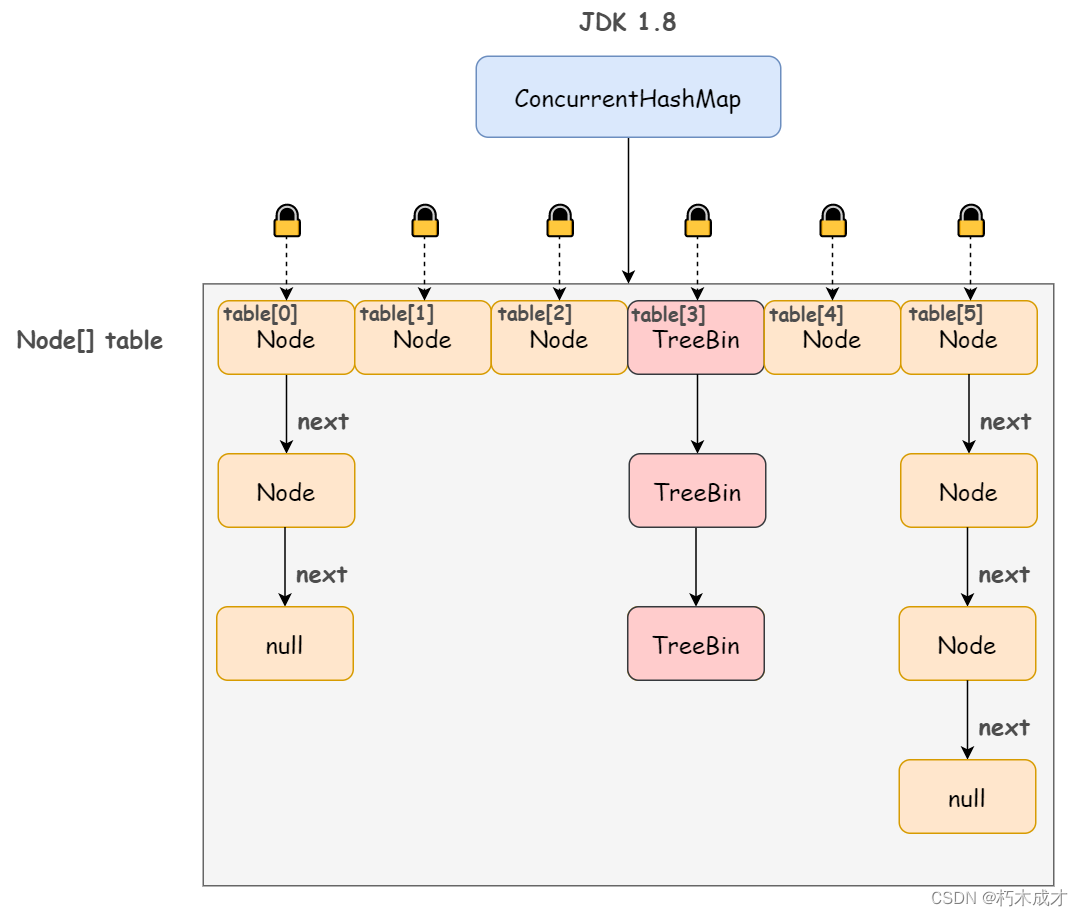
JDK1.8: 两个线程给同一个区段Segment中添加元素,这种情况不可以并发, 这样JDK1.8进行了改进,没有区段了,数组+链表+红黑树 +乐观锁 + synchronized。
Node 数组其实就是一个哈希桶数组,当多线程并发向同一个散列桶添加元素时。若散列桶为空,此时触发乐观锁机制,线程会获取到桶中的版本号,在添加节点之前,判断线程中获取的版本号与桶中实际存在的版本号是否一致,若一致,则添加成功,若不一致,则让线程自旋。若散列桶不为空,此时使用Synchronized来保证线程安全,先访问到的线程会给桶中的头节点加锁,从而保证线程安全。
put方法 :
*/
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//计算hash值,两次hash操作int binCount = 0;
int hash = spread(key.hashCode());
int binCount = 0;
//类似于while(true),死循环,直到插入成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//检查是否初始化了,如果没有,则初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//i=(n-1)&hash 等价于i=hash%n(前提是n为2的幂次方).即取出table中位置的节点用f表示。
//有如下两种情况:
//1.如果table[i]==null(即该位置的节点为空,没有发生碰撞),则利用CAS操作直接存储在该位置,如果CAS操作成功则退出死循环。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//检查table[i]的节点的hash是否等于MOVED,如果等于,则检测到正在扩容,
else if ((fh = f.hash) == MOVED)
//帮助其扩容
tab = helpTransfer(tab, f);
//运行到这里,说明table[i]的节点的hash值不等于MOVED
else {
V oldVal = null;
//锁定,(hash值相同的链表的头节点)
synchronized (f) {
//避免多线程,需要重新检查
if (tabAt(tab, i) == f) {
//链表节点
if (fh >= 0) {
binCount = 1;
//下面的代码就是先查找链表中是否出现了此key,如果出现,则更新value,并跳出循环,
//否则将节点加入到列表末尾并跳出循环
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
//仅putIfAbsent()方法中onlyIfAbsent为true
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//插入到链表末尾并跳出循环
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//如果是一个树节点,
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//插入到树中
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 插入成功后,如果插入的是链表节点,则要判断下该桶位是否要转化为树if (binCount != 0) {
// 实则是 > 8,执行else,说明该桶位本就有Node
if (binCount >= TREEIFY_THRESHOLD)
//若length<64,直接tryPresize,两倍table.length;不转树 if (oldVal != null)
//这里是为了避免table 过小的时候就进行转换成树的。
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
```
根据要 put 数据的 key 计算出 hashcode,遍历 table 数组,根据 hashcode 定位 Node:如果 Node 为空表示当前位置可以写入数据,利用 CAS 尝试写入(失败则自旋)如果当前位置的 hashcode == MOVED == -1,则需要对 Node 数组进行扩容
如果 Node 不为空并且也不需要进行扩容,则利用 synchronized 锁写入数据。
get方法:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
根据 key 对应 hashcode 找到对应的桶,如果正好是桶的头节点,则直接返回值。
如果不是桶的头节点,并且是红黑树结构,那就按照树的方式去查找值。
如果既不是桶的头节点,也不是红黑树结构,那就按照链表的方式去查找值(也就是遍历)。
知识点:
对于线程方面的知识点,会专门开个篇幅讲解。
乐观锁
ReentrantLock
最后形成思维导图方便记忆

三,Set系列
在了解完Map系列集合之后,Set系列就非常简单了。Set特点就是不重复,通过对比hashcode进行去重。不管是HashSet,LinkedHashSet,还是TreeSet,只需要把Map系列搞懂后再来看就比较容易了。
HashSet内部使用了HashMap;LinkedHashSet继承了HashSet;TreeSet内部使用了TreeMap。
以HashSet为例,部分源码如下:
// hashmap 中 put() 返回 null 时,表示操作成功
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// 返回值:如果插入位置没有元素则返回 null,否则返回上一个元素
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K, V>[] tab;
Node<K, V> p;
int n, i;
//如果哈希表为空,调用 resize() 创建一个哈希表,并用变量 n 记录哈希表长度
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
/**
* 如果指定参数 hash 在表中没有对应的桶,即为没有碰撞
* Hash函数,(n - 1) & hash 计算 key 将被放置的槽位
* (n - 1) & hash 本质上是 hash % n 位运算更快
*/
if ((p = tab[i = (n - 1) & hash]) == null)
// 直接将键值对插入到 map 中即可
tab[i] = newNode(hash, key, value, null);
else {// 桶中已经存在元素
Node<K, V> e;
K k;
// 比较桶中第一个元素(数组中的结点)的 hash 值相等,key 相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给 e,用 e 来记录
e = p;
// 当前桶中无该键值对,且桶是红黑树结构,按照红黑树结构插入
else if (p instanceof TreeNode)
e = ((TreeNode<K, V>) p).putTreeVal(this, tab, hash, key, value);
// 当前桶中无该键值对,且桶是链表结构,按照链表结构插入到尾部
else {
for (int binCount = 0; ; ++binCount) {
// 遍历到链表尾部
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 检查链表长度是否达到阈值,达到将该槽位节点组织形式转为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 链表节点的<key, value>与 put 操作<key, value>
// 相同时,不做重复操作,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 找到或新建一个 key 和 hashCode 与插入元素相等的键值对,进行 put 操作
if (e != null) { // existing mapping for key
// 记录 e 的 value
V oldValue = e.value;
/**
* onlyIfAbsent 为 false 或旧值为 null 时,允许替换旧值
* 否则无需替换
*/
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 更新结构化修改信息
++modCount;
// 键值对数目超过阈值时,进行 rehash
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
从上述源码可以看出,当将一个键值对放入 HashMap 时,首先根据 key 的 hashCode() 返回值决定该 Entry 的存储位置。如果有两个 key 的 hash 值相同,则会判断这两个元素 key 的 equals() 是否相同,如果相同就返回 true,说明是重复键值对,那么 HashSet 中 add() 方法的返回值会是 false,表示 HashSet 添加元素失败。因此,如果向 HashSet 中添加一个已经存在的元素,新添加的集合元素不会覆盖已有元素,从而保证了元素的不重复。如果不是重复元素,put 方法最终会返回 null,传递到 HashSet 的 add 方法就是添加成功。
总结:
HashSet 底层是由 HashMap 实现的,它可以实现重复元素的去重功能,如果存储的是自定义对象必须重写 hashCode 和 equals 方法。HashSet 保证元素不重复是利用 HashMap 的 put 方法实现的,在存储之前先根据 key 的 hashCode 和 equals 判断是否已存在,如果存在就不在重复插入了,这样就保证了元素的不重复。
四,队列系列
队列如果按功能进行分类,有一下几类。凡是带Blocking的,也可称为是阻塞队列。
- 普通队列(Queue):ArrayQueue,ArrayBlockingQueue,LinkedBlockingQueue;
- 双端队列(Deque):ArrayDeque,LinkedBlockingDeque,ConcurrentLinkedDeque;
- 优先队列:PriorityQueue;
- 延迟队列:DelayQueue;
- 其他:SynchronousQueue;
阻塞队列对比
ArrayBlockingQueue–数组实现的有界队列
会自动阻塞,根据调用api不同,有不同特性,当队列容量不足时,有阻塞能力。
boolean add(E e):在容量不足时,抛出异常。
void put(E e):在容量不足时,阻塞等待。
boolean offer(E e):不阻塞,容量不足时返回false,当前新增数据操作放弃。
boolean offer(E e, long timeout, TimeUnit unit):容量不足时,阻塞times时长(单位为timeunit),如果在阻塞时长内,有容量空闲,新增数据返回true。如果阻塞时长范围内,无容量空闲,放弃新增数据,返回false。
LinkedBlockingQueue–链式队列,队列容量不足或为0时自动阻塞
void put(E e):自动阻塞,队列容量满后,自动阻塞。
E take():自动阻塞,队列容量为0后,自动阻塞。
ConcurrentLinkedQueue–基础链表同步队列
boolean offer(E e):入队。
E peek():查看queue中的首数据。
E poll():取出queue中的首数据。
DelayQueue–延时队列
根据比较机制,实现自定义处理顺序的队列。常用于定时任务,如:定时关机。
int compareTo(Delayed o):比较大小,自动升序。
比较方法建议和getDelay方法配合完成。如果在DelayQueue是需要按时完成的计划任务,必须配合getDelay方法完成。
long getDelay(TimeUnit unit):获取计划时长的方法,根据参数TimeUnit来决定,如何返回结果值。
LinkedTransferQueue–转移队列
boolean add(E e):队列会保存数据,不做阻塞等待。
void transfer(E e):是TransferQueue的特有方法。必须有消费者(take()方法调用者)。如果没有任意线程消费数据,transfer方法阻塞。一般用于处理及时消息。
SynchronousQueue–同步队列,容量为0
是特殊的TransferQueue,必须先有消费线程等待,才能使用的队列。
boolean add(E e):父类方法,无阻塞,若没有消费线程阻塞等待数据,则抛出异常。
put(E e):有阻塞,若没有消费线程阻塞等待数据,则阻塞。
队列概念:
- 队列是一个有序列表,可用数组或链表进行实现。
- 遵循先入先出原则。即,先存入队列的数据先取出,后存入的数据要后取出。
数组模拟队列示意图

3.1 ArrayQueue
①,基本介绍
public class ArrayQueue<T> extends AbstractList<T> {
public ArrayQueue(int capacity) {
this.capacity = capacity + 1;
this.queue = newArray(capacity + 1);
this.head = 0;
this.tail = 0;
}
public void resize(int newcapacity) {
int size = size();
if (newcapacity < size)
throw new IndexOutOfBoundsException("Resizing would lose data");
newcapacity++;
if (newcapacity == this.capacity)
return;
T[] newqueue = newArray(newcapacity);
for (int i = 0; i < size; i++)
newqueue[i] = get(i);
this.capacity = newcapacity;
this.queue = newqueue;
this.head = 0;
this.tail = size;
}
@SuppressWarnings("unchecked")
private T[] newArray(int size) {
return (T[]) new Object[size];
}
public boolean add(T o) {
queue[tail] = o;
int newtail = (tail + 1) % capacity;
if (newtail == head)
throw new IndexOutOfBoundsException("Queue full");
tail = newtail;
return true; // we did add something
}
public T remove(int i) {
if (i != 0)
throw new IllegalArgumentException("Can only remove head of queue");
if (head == tail)
throw new IndexOutOfBoundsException("Queue empty");
T removed = queue[head];
queue[head] = null;
head = (head + 1) % capacity;
return removed;
}
public T get(int i) {
int size = size();
if (i < 0 || i >= size) {
final String msg = "Index " + i + ", queue size " + size;
throw new IndexOutOfBoundsException(msg);
}
int index = (head + i) % capacity;
return queue[index];
}
public int size() {
// Can't use % here because it's not mod: -3 % 2 is -1, not +1.
int diff = tail - head;
if (diff < 0)
diff += capacity;
return diff;
}
private int capacity;
private T[] queue;
private int head;
private int tail;
}
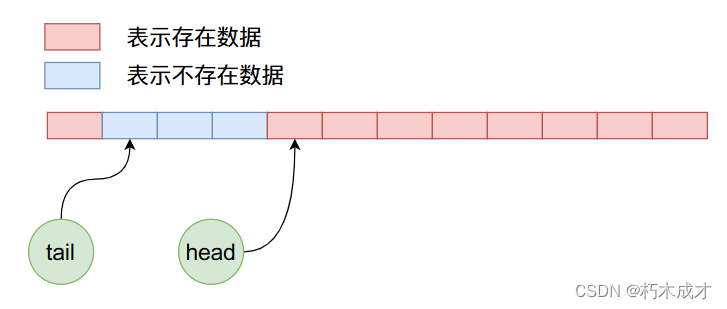
首先ArrayQueue内部是由循环数组实现的,在ArrayQueue内部有两个整型数据head和tail,这两个的作用主要是指向队列的头部和尾部,它的初始状态在内存当中的布局如下图所示:

因为是初始状态head和tail的值都等于0,指向数组当中第一个数据。现在我们向ArrayQueue内部加入5个数据,那么他的内存布局将如下图所示:
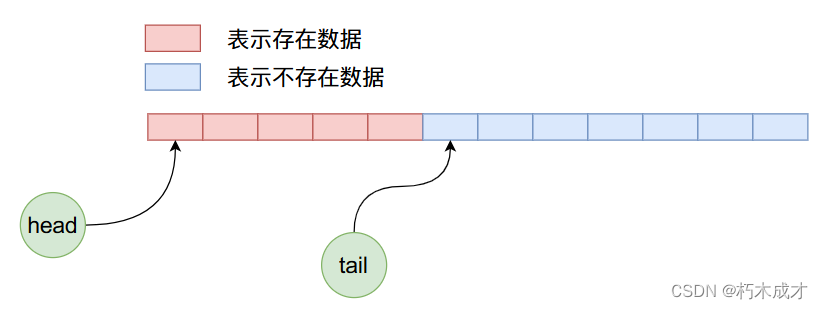
现在我们删除4个数据,那么上图经过4次删除操作之后,ArrayQueue内部数据布局如下:
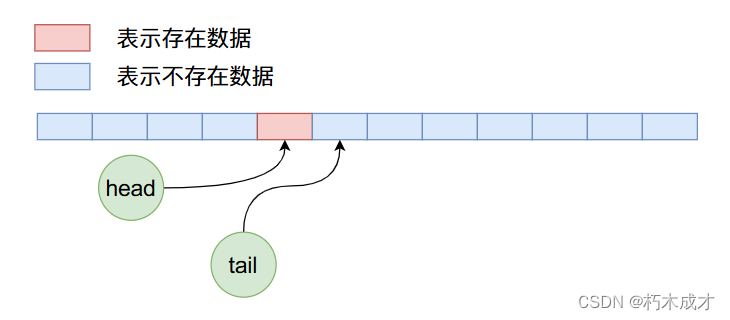
在上面的状态下,我们继续加入8个数据,那么布局情况如下:
我们知道上图在加入数据的时候不仅将数组后半部分的空间使用完了,而且可以继续使用前半部分没有使用过的空间,也就是说在ArrayQueue内部实现了一个循环使用的过程。
②,存储过程
add 可以循环将数据加入到数组当中去
public boolean add(T o) {
queue[tail] = o;
// 循环使用数组
int newtail = (tail + 1) % capacity;
if (newtail == head)
throw new IndexOutOfBoundsException("Queue full");
tail = newtail;
return true; // we did add something
}
remove
public T remove(int i) {
if (i != 0)
throw new IllegalArgumentException("Can only remove head of queue");
if (head == tail)
throw new IndexOutOfBoundsException("Queue empty");
T removed = queue[head];
queue[head] = null;
head = (head + 1) % capacity;
return removed;
}
在remove函数当中我们必须传递参数0,否则会抛出异常。而在这个函数当中我们只会删除当前head下标所在位置的数据,然后将head的值进行循环加1操作。
get
public T get(int i) {
int size = size();
if (i < 0 || i >= size) {
final String msg = "Index " + i + ", queue size " + size;
throw new IndexOutOfBoundsException(msg);
}
int index = (head + i) % capacity;
return queue[index];
}
get函数的参数表示得到第i个数据,这个第i个数据并不是数组位置的第i个数据,而是距离head位置为i的位置的数据。
resize
public void resize(int newcapacity) {
int size = size();
if (newcapacity < size)
throw new IndexOutOfBoundsException("Resizing would lose data");
newcapacity++;
if (newcapacity == this.capacity)
return;
T[] newqueue = newArray(newcapacity);
for (int i = 0; i < size; i++)
newqueue[i] = get(i);
this.capacity = newcapacity;
this.queue = newqueue;
this.head = 0;
this.tail = size;
}
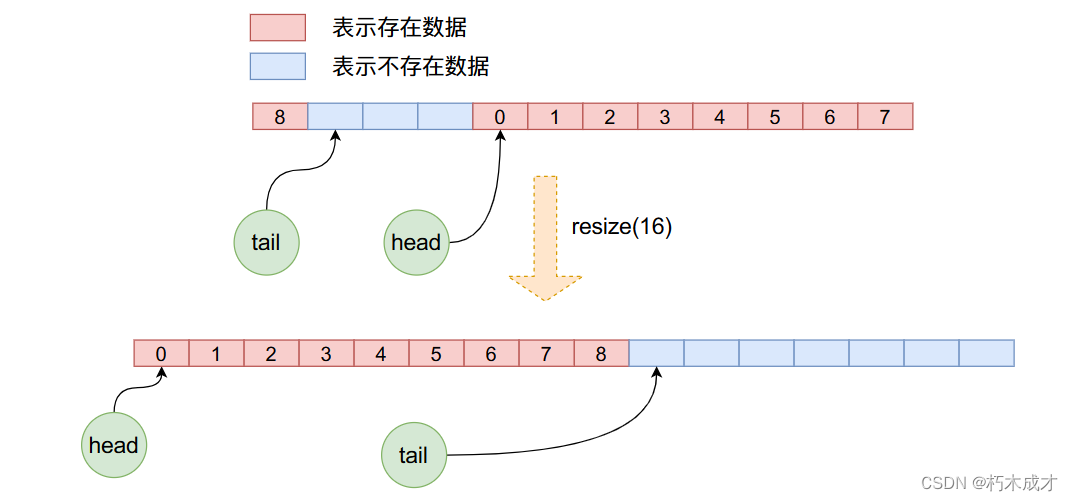
在resize函数当中首先申请新长度的数组空间,然后将原数组的数据一个一个的拷贝到新的数组当中,注意在这个拷贝的过程当中,重新更新了head与tail,而且并不是简单的数组拷贝,因为在之前的操作当中head可能已经不是0,因此新的拷贝需要我们一个一个的从就数组拿出来,然后放到新数组当中。下图可以很直观的看出这个过程:
3.2 ArrayBlockingQueue
①,基本介绍
ArrayBlockingQueue的内部是通过一个可重入锁ReentrantLock和两个Condition条件对象来实现阻塞。
public class ArrayBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable {
/** 存储数据的数组 */
final Object[] items;
/**获取数据的索引,主要用于take,poll,peek,remove方法 */
int takeIndex;
/**添加数据的索引,主要用于 put, offer, or add 方法*/
int putIndex;
/** 队列元素的个数 */
int count;
/** 控制并非访问的锁 */
final ReentrantLock lock;
/**notEmpty条件对象,用于通知take方法队列已有元素,可执行获取操作 */
private final Condition notEmpty;
/**notFull条件对象,用于通知put方法队列未满,可执行添加操作 */
private final Condition notFull;
/**
迭代器
*/
transient Itrs itrs = null;
}
ArrayBlockingQueue内部是通过数组对象items来存储所有的数据,通过ReentrantLock来同时控制添加线程与移除线程的并发访问,这点与LinkedBlockingQueue区别很大(稍后会分析)。而对于notEmpty条件对象则是用于存放等待或唤醒调用take方法的线程,告诉他们队列已有元素,可以执行获取操作。同理notFull条件对象是用于等待或唤醒调用put方法的线程,告诉它们,队列未满,可以执行添加元素的操作。takeIndex代表的是下一个方法(take,poll,peek,remove)被调用时获取数组元素的索引,putIndex则代表下一个方法(put, offer, or add)被调用时元素添加到数组中的索引。图示如下

②,存储过程
add
//add方法实现,间接调用了offer(e)
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
//offer方法
public boolean offer(E e) {
checkNotNull(e);//检查元素是否为null
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
if (count == items.length)//判断队列是否满
return false;
else {
enqueue(e);//添加元素到队列
return true;
}
} finally {
lock.unlock();
}
}
//入队操作
private void enqueue(E x) {
//获取当前数组
final Object[] items = this.items;
//通过putIndex索引对数组进行赋值
items[putIndex] = x;
//索引自增,如果已是最后一个位置,重新设置 putIndex = 0;
if (++putIndex == items.length)
putIndex = 0;
count++;//队列中元素数量加1
//唤醒调用take()方法的线程,执行元素获取操作。
notEmpty.signal();
}
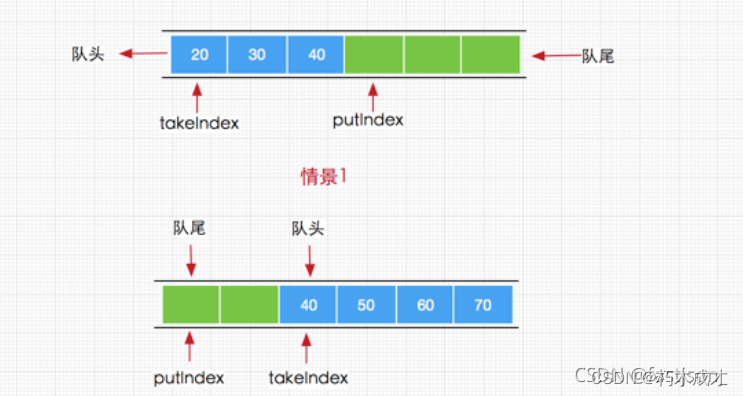
enqueue(E x)方法,其方法内部通过putIndex索引直接将元素添加到数组items中,这里可能会疑惑的是当putIndex索引大小等于数组长度时,需要将putIndex重新设置为0,这是因为队列执行元素获取时总是从队列头部获取,而添加元素从队列尾部获取所以当队列索引(从0开始)与数组长度相等时,下次我们就需要从数组头部开始添加了,如下图演示
put
//put方法,阻塞时可中断
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//该方法可中断
try {
//当队列元素个数与数组长度相等时,无法添加元素
while (count == items.length)
//将当前调用线程挂起,添加到notFull条件队列中等待唤醒
notFull.await();
enqueue(e);//如果队列没有满直接添加。。
} finally {
lock.unlock();
}
}
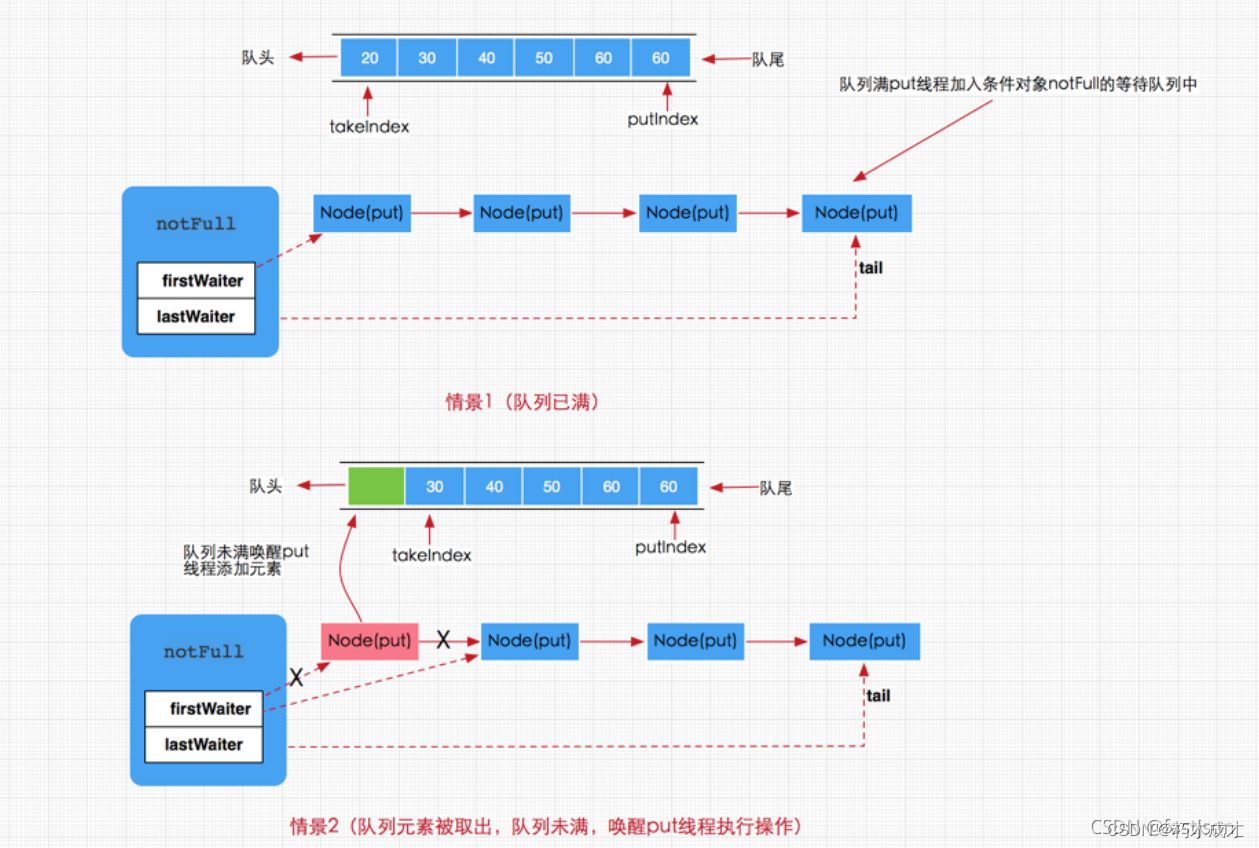
put方法是一个阻塞的方法,如果队列元素已满,那么当前线程将会被notFull条件对象挂起加到等待队列中,直到队列有空档才会唤醒执行添加操作。但如果队列没有满,那么就直接调用enqueue(e)方法将元素加入到数组队列中。到此我们对三个添加方法即put,offer,add都分析完毕,其中offer,add在正常情况下都是无阻塞的添加,而put方法是阻塞添加。这就是阻塞队列的添加过程。说白了就是当队列满时通过条件对象Condtion来阻塞当前调用put方法的线程,直到线程又再次被唤醒执行。总得来说添加线程的执行存在以下两种情况,一是,队列已满,那么新到来的put线程将添加到notFull的条件队列中等待,二是,有移除线程执行移除操作,移除成功同时唤醒put线程,如下图所示
 poll:移除
poll:移除
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//判断队列是否为null,不为null执行dequeue()方法,否则返回null
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
//删除队列头元素并返回
private E dequeue() {
//拿到当前数组的数据
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//获取要删除的对象
E x = (E) items[takeIndex];
将数组中takeIndex索引位置设置为null
items[takeIndex] = null;
//takeIndex索引加1并判断是否与数组长度相等,
//如果相等说明已到尽头,恢复为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列个数减1
if (itrs != null)
itrs.elementDequeued();//同时更新迭代器中的元素数据
//删除了元素说明队列有空位,唤醒notFull条件对象添加线程,执行添加操作
notFull.signal();
return x;
}
remove
public boolean remove(Object o) {
if (o == null) return false;
//获取数组数据
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();//加锁
try {
//如果此时队列不为null,这里是为了防止并发情况
if (count > 0) {
//获取下一个要添加元素时的索引
final int putIndex = this.putIndex;
//获取当前要被删除元素的索引
int i = takeIndex;
//执行循环查找要删除的元素
do {
//找到要删除的元素
if (o.equals(items[i])) {
removeAt(i);//执行删除
return true;//删除成功返回true
}
//当前删除索引执行加1后判断是否与数组长度相等
//若为true,说明索引已到数组尽头,将i设置为0
if (++i == items.length)
i = 0;
} while (i != putIndex);//继承查找
}
return false;
} finally {
lock.unlock();
}
}
//根据索引删除元素,实际上是把删除索引之后的元素往前移动一个位置
void removeAt(final int removeIndex) {
final Object[] items = this.items;
//先判断要删除的元素是否为当前队列头元素
if (removeIndex == takeIndex) {
//如果是直接删除
items[takeIndex] = null;
//当前队列头元素加1并判断是否与数组长度相等,若为true设置为0
if (++takeIndex == items.length)
takeIndex = 0;
count--;//队列元素减1
if (itrs != null)
itrs.elementDequeued();//更新迭代器中的数据
} else {
//如果要删除的元素不在队列头部,
//那么只需循环迭代把删除元素后面的所有元素往前移动一个位置
//获取下一个要被添加的元素的索引,作为循环判断结束条件
final int putIndex = this.putIndex;
//执行循环
for (int i = removeIndex;;) {
//获取要删除节点索引的下一个索引
int next = i + 1;
//判断是否已为数组长度,如果是从数组头部(索引为0)开始找
if (next == items.length)
next = 0;
//如果查找的索引不等于要添加元素的索引,说明元素可以再移动
if (next != putIndex) {
items[i] = items[next];//把后一个元素前移覆盖要删除的元
i = next;
} else {
//在removeIndex索引之后的元素都往前移动完毕后清空最后一个元素
items[i] = null;
this.putIndex = i;
break;//结束循环
}
}
count--;//队列元素减1
if (itrs != null)
itrs.removedAt(removeIndex);//更新迭代器数据
}
notFull.signal();//唤醒添加线程
}
remove删除时线程先获取锁,再一步判断队列count>0,这点是保证并发情况下删除操作安全执行。接着获取下一个要添加源的索引putIndex以及takeIndex索引 ,作为后续循环的结束判断,因为只要putIndex与takeIndex不相等就说明队列没有结束。然后通过while循环找到要删除的元素索引,执行removeAt(i)方法删除,在removeAt(i)方法中实际上做了两件事,一是首先判断队列头部元素是否为删除元素,如果是直接删除,并唤醒添加线程,二是如果要删除的元素并不是队列头元素,那么执行循环操作,从要删除元素的索引removeIndex之后的元素都往前移动一个位置,那么要删除的元素就被removeIndex之后的元素替换,从而也就完成了删除操作。
take
//从队列头部删除,队列没有元素就阻塞,可中断
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();//中断
try {
//如果队列没有元素
while (count == 0)
//执行阻塞操作
notEmpty.await();
return dequeue();//如果队列有元素执行删除操作
} finally {
lock.unlock();
}
}
3.3 LinkedBlockingQueue
LinkedBlockingQueue是一个阻塞队列,内部由两个ReentrantLock来实现出入队列的线程安全,由各自的Condition对象的await和signal来实现等待和唤醒功能。它和ArrayBlockingQueue的不同点在于:
- 队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
- 数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
- 由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
- 两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
/**
* 节点类,用于存储数据
*/
static class Node<E> {
E item;
Node<E> next;
Node(E x) { item = x; }
}
/** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity;
/** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger();
/**
* 阻塞队列的头结点
*/
transient Node<E> head;
/**
* 阻塞队列的尾节点
*/
private transient Node<E> last;
/** 获取并移除元素时使用的锁,如take, poll, etc */
private final ReentrantLock takeLock = new ReentrantLock();
/** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition();
/** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock();
/** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition();
从上面的属性我们知道,每个添加到LinkedBlockingQueue队列中的数据都将被封装成Node节点,添加的链表队列中,其中head和last分别指向队列的头结点和尾结点。与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)