
异常行为检测阅读笔记:Future Frame Prediction for Anomaly Detection – A New Baseline
前言之前写的博客,一直没放出来,今天亮出来晒晒太阳。深度学习时代的无监督异常行为检测,套路都非常单一,都是用生成式网络(包括自编码器,GAN等)来重构或简单地预测帧,然后通过比较重构误差和阈值来达到判断异常与否的目的。这一篇就是一个典型,不过工作做得蛮充足,效果也不错,值得学习。本文出自上科大(上海科技大学)高盛华老师团队。code已放,写的很不错:https://github.com/st...
前言
之前写的博客,一直没放出来,今天亮出来晒晒太阳。
深度学习时代的无监督异常行为检测,套路都非常单一,都是用生成式网络(包括自编码器,GAN等)来重构或简单地预测帧,然后通过比较重构误差和阈值来达到判断异常与否的目的。这一篇就是一个典型,不过工作做得蛮充足,效果也不错,值得学习。
本文出自上科大(上海科技大学)高盛华老师团队。code已放,写的很不错:https://github.com/stevenLiuWen/ano_pred_cvpr2018
Motivation
文章总有motivation,如果motivation不清晰,那么本文多半是个水文(狗头,狗头)。本文的Motivation很清晰,就是对于常见的AutoEncoder做异常行为检测,有个严重的潜在问题,就是AutoEncoder往往过完备(overcomplete),容易引起恒等映射,试想,在测试时候,正常样本本成功重构了,异常样本靠着恒等映射,也被成功“重构”(其实是成功复制)了,那还如何能把它们区分开呢?如果做一个很简单的改动,就是将重构当前帧改为预测后一帧或后几帧,是不是就能避免恒等映射的风险?这就是本文的出发点。那既然选择了预测,那GAN自然成了首选,作者为了保证GAN的生成质量,在优化函数上又下了一些功夫,下面来具体看看吧。
方法与网络框架:Future Frame Prediction Based Anomaly Detection Method

网络架构很清晰啦,输入是连续的 t t t帧(本文 t = 4 t=4 t=4),送入一个生成器,生成第 t + 1 t+1 t+1帧,为了保证生成质量,这里作者用了三个loss来约束,第一个loss就是简单的L2距离,保证对应像素之间尽可能相似:



既然是GAN,那该判别器登场了,作者这里使用的是Least Square GAN。套路都差不多,即为了进一步使生成图像更逼真,引入判别器。对于判别器D,这里使用一个patch discriminator,训练D时,固定G参数,优化如下loss function,直白来说就是对真实图像 I I I,让他分类为真,对生成图像 I ^ \hat{I} I^,让他分类为假,即通过训练,增加判别器的真假判别能力:


那最后的loss function就明晰了,即交替训练以下两个loss function:


到这里网络框架的训练部分就介绍完了,下面说下怎么测试。前文也说了,就是比较预测误差,计算预测误差无非是比较生成(预测)的图像和真实图像之间的差别,作者这里采用的是图像处理领域常见的PSNR( Peak Signal to Noise Ratio,峰值信噪比),关于这一点,笔者也没有过多思考在异常行为检测领域究竟用哪个会比较好,如果你有想法,欢迎留言或发邮件交流。PSNR的具体表达式是:


实验
作者在四个库上做了实验,CUHK Avenue,UCSD Ped1,UCSD Ped1以及ShanghaiTech。评价指标使用帧级别的AUC。
先比较SOTA,效果不错,如下表:

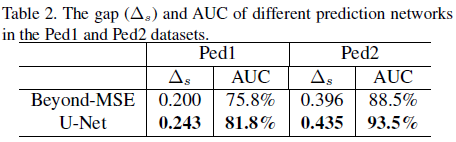
比较生成器部分,这里使用的gap指标指的是正常样本的平均得分(预测误差)和异常样本的平均得分之间的差,自然是越大越好,说明分的越开,如下表所示。
比较运动约束部分的效果,下表比较了有和没有之间的差异:

比较不同loss的效果,如下图所示,说明每个loss都起到了作用:

最后比较了和Autoencoder的效果提升,如下图所示,提升挺大:

最后的最后,呈现两个异常行为视频下的效果,感兴趣的话可以去作者GitHub上贴的那个youtube链接里看视频,这里我只贴图,不过多说明了,大家可以自己看。

总结
其实预测这个套路并不是本文第一个提出的,之前就有人这么做了,比如ACM MM里就有一篇:Spatio-Temporal AutoEncoder for Video Anomaly Detection,但时间间距特别短,作者在文中强调自己是第一篇,可能也是没问题的。但是深度学习下的异常行为检测这两年一直都停留在这种生成模型的套路中,小修小补,非常期待见到新的工作产生。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)