视觉SLAM中的数学——外点处理:鲁棒核函数 RANSAC方法
前言本博客主要为学习《视觉SLAM十四讲》、《计算机视觉-算法与应用》第6章基于特征的配准 《机器人学中的状态估计》第5章偏差、匹配和外点 等其他相关SLAM内容的总结与整理。外点传感器测量值可能会受多种因素干扰而不可靠,同时特征匹配也会存在误匹配的情况,如果不正确地检测并剔除他们,视觉SLAM中的很多算法(如计算本质矩阵、三角测量、PNP等)将会失败。我们将非常不可能的测量值(根据测量模...
前言
本博客主要为学习《视觉SLAM十四讲》、《计算机视觉-算法与应用》第6章基于特征的配准 《机器人学中的状态估计》第5章偏差、匹配和外点 等其他相关SLAM内容的总结与整理。
外点
传感器测量值可能会受多种因素干扰而不可靠,同时特征匹配也会存在误匹配的情况,如果不正确地检测并剔除他们,视觉SLAM中的很多算法(如计算本质矩阵、三角测量、PNP等)将会失败。
我们将非常不可能的测量值(根据测量模型)称为外点(outlier)。
对外点的一种常用判断标准是(一维数据中)将超出平均值三个标准差的测量值作为外点。
处理外点的两种最常用方案为:
1、随机采样一致性
2、M估计
RANSAC
随机采样一致性(random sample consensus,RANSAC)是一种对带有外点的数据拟合参数模型的迭代方法。
RANSAC基础版本的每次迭代包括5个步骤:
- 在原始数据中随机选取一个(最小)子集作为假设内点;
- 根据假设的内点拟合一个模型;
- 判断剩余的原始数据是否符合拟合的模型,将其分为内点和外点。如果内点过少则标记为无效迭代;
- 根据假设的内点和上一步划分的内点重新拟合模型;
- 计算所有内点的残差,根据残差和或者错误率重新评估模型。
迭代以上步骤,把具有最小残差和的或是最多内点数的模型作为最佳模型。
RANSAC是一种概率算法,为了能确保有更好的概率找到真正的内点集合,必须实验足够多的次数。以下为试验次数的计算过程:
1、假设每次选取测量点都是相互独立的,且每个测量点为内点的概率均为w,p为经过k次试验后成功的总体概率;
2、那么在某次实验中,n个随机样本都是内点的可能性是wn(这里n表示为拟合该模型需要的最少数据个数);
3、因此经过了p次试验,失败的概率是:
1
−
p
=
(
1
−
w
n
)
k
1-p=(1-w^n)^k
1−p=(1−wn)k
得到最少需要的试验次数为:
k
=
l
o
g
(
1
−
p
)
l
o
g
(
1
−
w
n
)
k=\frac {log(1-p)}{log(1-w^n)}
k=log(1−wn)log(1−p)
事实上,这个k值被看作是选取不重复点的上限,因为这个结果假设n个点都是独立选择的,也就是说,某个点被选定之后,它可能会被后续的迭代过程重复选定到。而数据点通常是顺序选择的。
RANSAC与最小二乘的区别:
最小二乘法尽量去适应包括外点在内的所有点。而RANSAC得出一个仅仅用内点计算出模型,并且概率还足够高。但是,RANSAC不能保证结果一定正确(只有一定的概率得到可信的模型),为了保证算法有足够高的合理概率,必须小心选择算法的参数。对于外点数量较多的数据集,RANSAC的效果远优于直接的最小二乘法。
M-估计
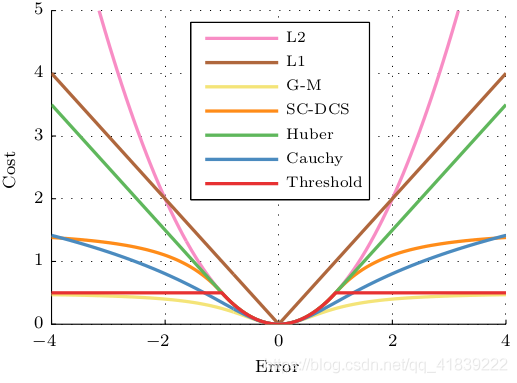
SLAM中的很多状态估计都是以最小化误差平方和作为代价函数,一个偏离较大的外点会对估计结果产生巨大的影响。而M估计的主要思想便是将原先误差的平方项替换为一个增长没那么快的函数,同时保证自己的光滑性质(能求导),获得更加鲁棒的最小二乘,这个函数又称为鲁棒核函数。
例如SLAM十四讲中提到的Huber核:
H
(
e
)
=
{
1
2
e
2
当
∣
e
∣
≤
δ
,
δ
(
∣
e
∣
−
1
2
δ
)
其
他
H(e)={\begin{cases} \frac{1}{2}e^2&当|e|\le\delta,\\ \delta(|e|-\frac{1}{2}\delta)&其他 \end{cases} }
H(e)={21e2δ(∣e∣−21δ)当∣e∣≤δ,其他
其具体过程其等价于迭代加权最小二乘估计,即根据前一次代价函数的残差大小来确定之后各样本的权重变化。
下图为集中常用的鲁棒核函数

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)