深度学习 -- SSD 算法流程详解
SSD同样是经典论文,后续很多论文以此为基础,所以搞懂流程比较重要,中间如果 有写的不对、有问题或者有看不懂的地方,还望指正。如果有了新的理解,我会持续更新。作为经典论文,SSD算法也同样产生了很多后续工作比如 DSSD、RefineDet等等,而且由于有速度优势,工程中使用SSD和YOLO的可能性会更大。一、网络结构:上图是SSD和...
SSD同样是经典论文,后续很多论文以此为基础,所以搞懂流程比较重要,中间如果 有写的不对、有问题或者有看不懂的地方,还望指正。如果有了新的理解,我会持续更新。
作为经典论文,SSD算法也同样产生了很多后续工作比如 DSSD、RefineDet等等,而且由于有速度优势,工程中使用SSD和YOLO的可能性会更大。
一、网络结构:

上图是SSD和YOLO的网络结构,通过对比可以发现,SSD的优点就是它生成的 default box 是多尺度的,这是因为SSD生成default box 的 feature map 不仅仅是CNN输出的最后一层,还有利用比较浅层的feature map 生成的default box。所以SSD对于小目标的检测一定会优于YOLO v1(小目标经过高层卷积后特征几乎都消失了)。同时,又因为SSD生成的多尺度default box一定有更高概率找到更加贴近于 Ground Truth 的候选框,所以模型的稳定性是肯定比YOLO强的(YOLO的bounding box很少,只有98个,如果距离GT比较远,那么修正 bounding box 的线性回归就不成立,训练时模型可能会跑飞)。但是SSD的候选框数量是三种经典网络中最多的,有8732个,所以训练时应该会比较慢。
二、算法流程:
首先来看一下SSD的基本步骤(比YOLO稍微复杂点,但是也很直接了):
- 输入一幅图片,让图片经过卷积神经网络(CNN)提取特征,并生成 feature map
- 抽取其中六层的feature map,然后再 feature map 的每个点上生成 default box(各层的个数不同,但每个点都有)
- 将生成的所有 default box 都集合起来,全部丢到 NMS(极大值抑制)中,输出筛选后的 default box,并输出
三、算法细节:
3.1 default box怎么生成的:

这是原文中的图,图(b)和 图(c)中的虚线框就是生成的 default box,总共的怎么算呢? 38x38x4、19x19x6、10x10x6、5x5x6、3x3x4、1x1x4,也就是 5773、2166、600、150、36、4,加起来一共有 8732 个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
3.2 default 的生成规则:
由于不同层的 feature map 对应到原图上的感受野不同,所以在不同层山生成的default box其实大小是不一样的(比例一样)。
生成 default box 时,在 feature map 上每个点上生成一系列同心的Defalut box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)使用m(这里m = 6,因为就选了6层)个不同大小的feature map 来做预测,最底层的 feature map 的 scale 值为 Smin=0.2,最高层的为Smax=0.9,其他层通过下面的公式计算得到:
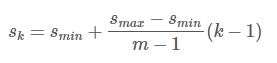
使用不同的ratio值,[1, 2, 3, 1/2, 1/3],通过下面的公式计算 default box 的宽度w和高度h
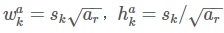
而对于ratio=1的情况,指定的scale如下所示,即总共有 6 中不同的 default box。
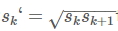
default box 的中心点坐标为: , fk时第k层的feature map 的大小。
3.3 Loss 函数:
后续的很多目标检测论文都是用这样的损失函数,SSD算法的损失函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的位置回归。

其中 N 是match到Ground Truth的default box数量;而alpha参数用于调整confidence loss和location loss之间的比例,默认alpha=1。
3.3.1 位置回归则是采用 Smooth L1 loss,目标函数为:

3.3.2 confidence loss是典型的softmax loss:
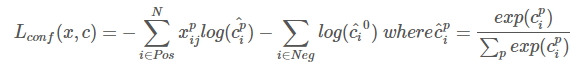
下图非常好的解释了SSD的Loss函数是怎么来的(用下别人的图,有时间自己画一个,方便理解):
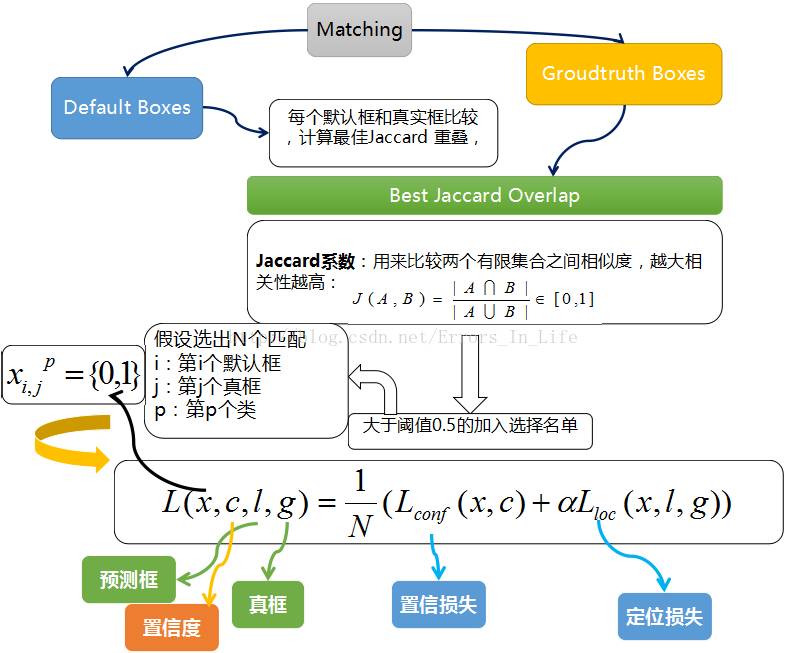
3.4 训练样本比例:
文中提到,由于有8000多个default box 那么matching之后会有大量的负样本,为了数据集更加干净,正负样本比例取到 1:3。
以上
参考:https://www.cnblogs.com/MY0213/p/9858383.html

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)