
论文略读 | Mem2Seq: Effectively Incorporating Knowledge Bases into End-to-End Task-Oriented Dialog Syste
代码(搬运工):https://github.com/HLTCHKUST/Mem2Seq
1. 概述
问题: 任务型端到端对话常常面临着和知识库结合的挑战,本文提出了一种新颖而简单的端到端可微分模型,称为Mem2Seq,它是第一个结合记忆网络的多跳注意机制和指针网络的思想。
2. 简介
查询知识库是必不可少的,因为响应不仅由对话历史引导,还由查询结果引导。
RNN端到端:
可以将纯文本对话历史映射到输出响应,并且对话状态是潜在的,不需要手工制作的状态标签。
基于注意力的复制机制:
直接从源复制单词到输出响应。这样,即使未知词出现在对话历史中,模型仍然能够生成正确且相关的实体。
仍存在两个问题:
1)它们努力尝试将外部知识库信息有效地纳入到RNN隐藏状态,因为已知RNN在长序列上是不稳定的。
2)处理长序列非常耗时,尤其是在使用注意力机制时。
MemNN分析:
- 另一方面,端到端记忆网络(MemNN)是在一个巨大外部memory上的recurrent attention模型。它们将外部记忆写入几个嵌入矩阵,并使用查询向量重复读取存储器。
a. 优势
- 此方法可以记忆外部KB信息并快速编码长对话历史记录。
- 此外,MemNN的多跳机制被证明在推理任务中能够实现很高的性能。
b. 不足
- 尽管如此,MemNN只是从预定义的候选池中选择其响应,而不是逐字生成。
- 此外,内存查询需要显式设计而不是通过模型学习,
- 并且不存在复制机制。
为了解决这些问题,我们提出了一种新颖的架构(Mem2Seq),该模型使用顺序生成架构扩充了现有的MemNN框架,使用全局多跳注意机制直接从对话历史或KB中复制单词。
主要贡献:
- Mem2Seq是第一个将多跳注意力机制和指针网络结合起来的模型,它允许我们有效的合并KB信息。
- Mem2Seq学习如何生成动态查询来控制内存访问,此外,我们可以对内存控制器和注意力的跳跃之间的模型动态进行可视化和解释。
- Mem2Seq可以更快地进行训练,并在几个面向任务的对话框数据集中实现最先进的结果。
3. 模型描述
Mem2Seq由两个组件来组成(MemNN encoder和memory decoder),其中MemNN encoder将对话历史编码成一个向量,之后memory decoder读取并复制memory产生一个响应。
(1) Encoder
Mem2Seq 用一个标准 MemNN+adjacent weighted tying作为encoder,输入是U中一个word-level 的信息,MemNN的记忆用一系列训练过的嵌入矩阵来表示,一个query 向量 qk用来表示reading head,这个模型循环K词,并在第k次为每个记忆i计算注意力权重
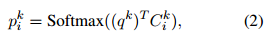
Cki是第k个loop中位置i处的记忆。pk是一个soft memory selector用来决定记忆和query vector qk的相关性,所以读出记忆如下所示(就是上一轮计算出来相关性,和下一轮的记忆做SUM求出下一轮的读出记忆)。
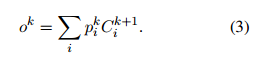
query vector的更新:
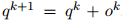
encoder的输出是记忆向量 oK,用它来作为decoder阶段的输入。
(2) Decoder
decoder用了RNN和MemNN,其中MemNN将X和B都load进来,因为我们在解码生成一个恰当的系统回复的时候既要用到对话历史,又要用到KB信息。GRU被用作MemNN的动态query generator。在每个解码时间步t,用原始的生成单词和query作为GRU输入,以此来生成新的查询向量。(即用上一步的隐藏层和上一步输出作为输入)
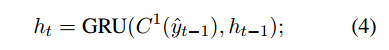
然后这个query ,即ht被送到产生token的MemNN,其中h0是encoder vector ,即oK。在每一步生成两个概率分布,一个是在词汇(vocabulary)中的所有词上,一个是在memory内容(即对话历史和KB信息)上的概率分布。
第一个概率分布Pvocab,是通过结合第一轮读出的attention和当前query vector生成的。

第二个概率分布用decoder最后一跳MemNN的attention weights来生成。即 decoder通过指向memory中的输入单词来生成。
这样做的原因是想要通过两个注意力权重来 looser和shaper概率 分布,即第一跳更多的是从memory中提取信息,最后一条更多的是通过指针监督来选择确切的token。
loss:联合训练两个标准的交叉熵,一个是 和
和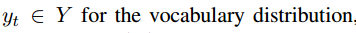 ,另一个是内存分布上的
,另一个是内存分布上的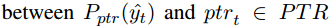 。
。
如果预期的单词没有出现在记忆中,则训练Pptr产生哨兵token $,如下图公式所示。如果是产生了哨兵,就从Pvoca中选择生成单词,否则就从记忆中获取,即哨兵是用来选择在该步应该选择哪种方式生成(和那个两个softmax的好像啊–Point to unknow words,不过这个是soft gate ,就是不用硬性的选择是0还是1)。

(3) Memory Content
-
将 word-level的内容X存到memory module中,将临时信息和X中每个token的speaker信息填进去来获得sequential dependencies。例如
“hello t1 $u”意味着“hello” at time step 1 spoken by a user.。 -
为了保存KB信息,用
(subject, relation, object)来表示。例如(The Westin, Distance, 5 miles)。因此我们将每个subject, relation, object的词嵌入求和来得到KB 的memory 表示。在解码阶段,object(宾语)被用作Pptr的生成词,比如当指向上面那个KB条目的时候,5miles就作为一个输出词。注意到,memory中只存储了KB的一部分。
4. 训练
(1)数据集
使用三个公共多回合任务型对话数据集来评估
bAbI(模拟数据),DSTC2)真实人机数据,噪声更大和In-Car Assistant(人对人数据,用户和系统行为更多样化,系统响应是变化的并且KB要复杂的多,需要更强的与KB交互的能力,而不是DST)
数据集信息:

(2) 评价标准:
Per-response/dialog Accuracy:
BLEU:
Entity F1:
(3)对比模型
查询减少网络(QRN,Seo等人(2017)),端到端存储网络(MemNN,Sukhbaatar等人(2015)) )和门控端到端内存网络(GMemNN,Liu和Perez(2017))。
我们还实现了以下基线模型:标准的序列到序列(Seq2Seq)模型,有或没有注意(Luong等,2015),指向未知(Ptr-Unk,Gulcehre等(2016))
参考
https://blog.csdn.net/weixin_40533355/article/details/83064795

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)