Advice for Applying Machine Learning
get more training examplestry smaller sets of featuretry getting additional featurestry adding polynomial featurestry increasing/decreasing λ\lambdaλEvaluating a hypothesis将数据集划分成训练集和测试集,大约按7:...
·
- get more training examples
- try smaller sets of feature
- try getting additional features
- try adding polynomial features
- try increasing/decreasing λ \lambda λ
Evaluating a hypothesis
将数据集划分成训练集和测试集,大约按7:3进行划分。划分的时候注意要随机划分。
Model Selection and training/validation/test sets

将假设的次幂d也看做是一个参数。然后模型选取的过程如下:
- 每个假设(d不相同)通过训练集来学习 θ \theta θ
- 对每个假设得到交叉验证集的误差 J ( θ ) c v J(\theta)_{cv} J(θ)cv,选择最小的 J ( θ o p t ) J(\theta_{opt}) J(θopt)。这一步实际是对交叉验证集的拟合,所以为了避免过拟合,需要进行第三部
- 在测试集上得到测试集误差 J ( θ o p t ) J(\theta_{opt}) J(θopt),即当前模型的评估。
训练集:交叉验证集:测试集 = 6:2 : 2
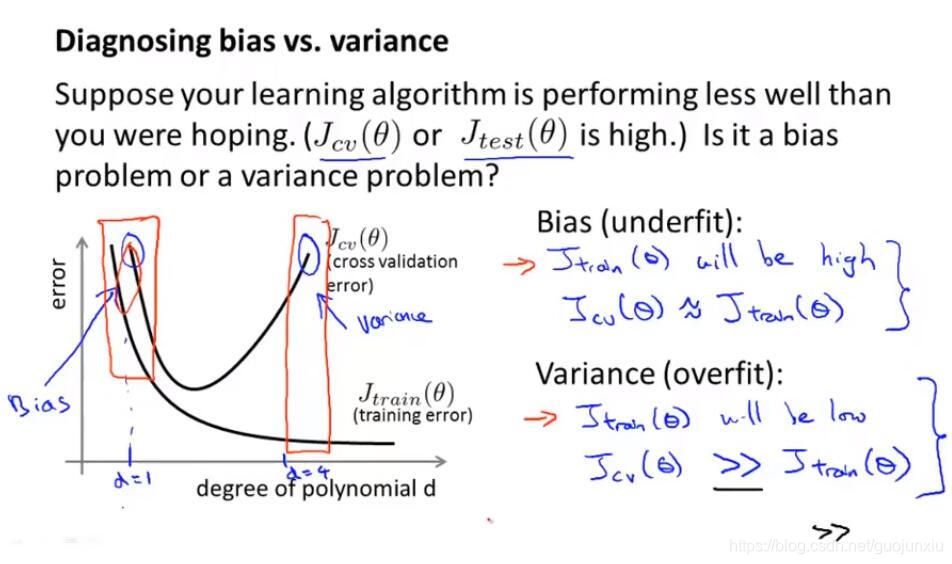
diagnosing bias vs. variance
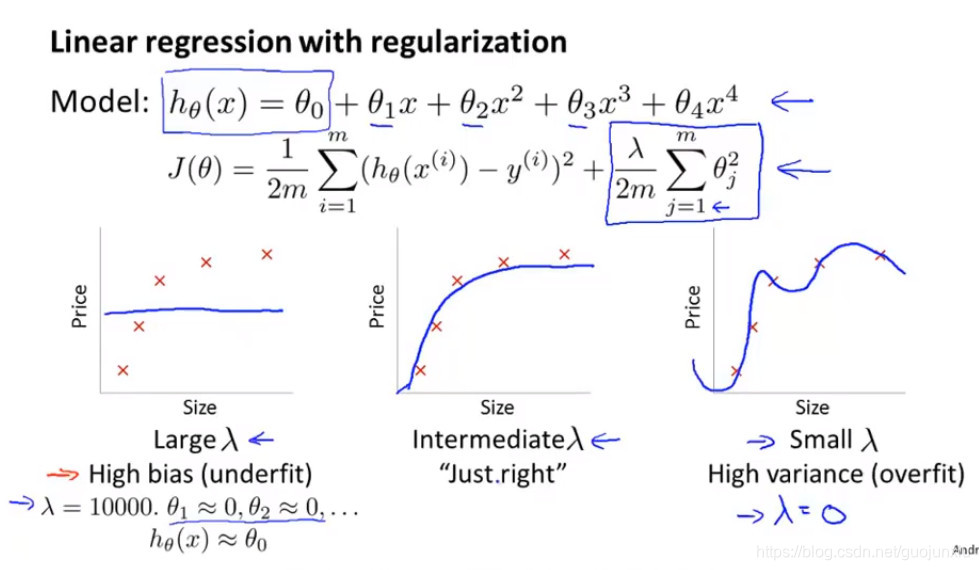
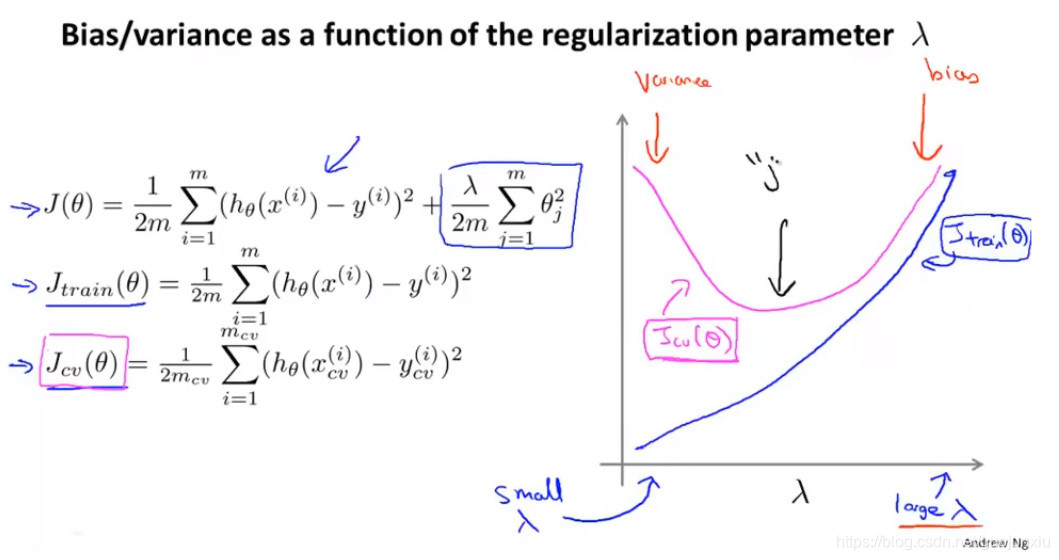
Regularization and bias/variance

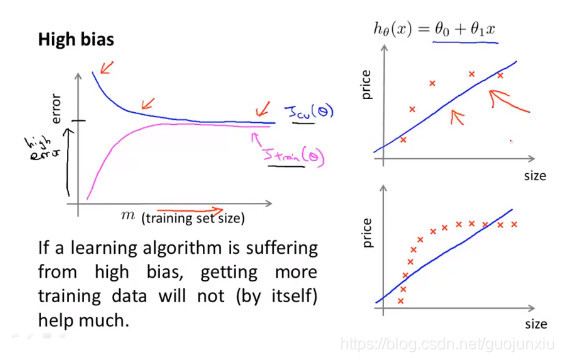
Learning Curves



CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)