
DirectX11 With Windows SDK--27 计算着色器:双调排序
前言上一章我们用一个比较简单的例子来尝试使用计算着色器,但是在看这一章内容之前,你还需要了解下面的内容:章节26 计算着色器:入门深入理解与使用缓冲区资源这一章我们继续用一个计算着色器的应用实例作为切入点,进一步了解相关知识。DirectX11 With Windows SDK完整目录Github项目源码欢迎加入QQ群: 727623616 可以一起探讨DX...
前言
上一章我们用一个比较简单的例子来尝试使用计算着色器,但是在看这一章内容之前,你还需要了解下面的内容:
| 章节 |
|---|
| 26 计算着色器:入门 |
| 深入理解与使用缓冲区资源 |
这一章我们继续用一个计算着色器的应用实例作为切入点,进一步了解相关知识。
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。
线程标识符
对于线程组(大小(ThreadDimX, ThreadDimY, ThreadDimZ))中的每一个线程,它们都有一个唯一的线程ID值。我们可以使用系统值SV_GroupThreadID来取得,它的索引范围为(0, 0, 0)到(ThreadDimX - 1, ThreadDimY - 1, ThreadDimZ - 1)。

而对于整个线程组来说,由于线程组集合也是在3D空间中排布,它们也有一个唯一的线程组ID值。我们可以使用系统值SV_GroupID来取得,线程组的索引范围取决于调用ID3D11DeviceContext::Dispatch时提供的线程组(大小(GroupDimX, GroupDimY, GroupDimZ)),范围为(0, 0, 0)到(GroupDimX - 1, GroupDimY - 1, GroupDimZ - 1)。

紧接着就是系统值SV_GroupIndex,它是单个线程组内的线程三维索引的一维展开。若已知线程组的大小为(ThreadDimX, ThreadDimY, ThreadDimZ),则可以确定SV_GroupIndex与SV_GroupThreadID满足下面关系:
SV_GroupIndex = SV_GroupThreadID.z * ThreadDimX * ThreadDimY + SV_GroupThreadID.y * ThreadDimX + SV_GroupThreadID.x;
最后就是系统值SV_DispatchThreadID,线程组中的每一个线程在ID3D11DeviceContext::Dispatch提供的线程组集合中都有其唯一的线程ID值。若已知线程组的大小为 (ThreadDimX, ThreadDimY, ThreadDimZ),则可以确定SV_DispatchThreadID,SV_GroupThreadID和SV_GroupID满足以下关系:
SV_DispatchThreadID.xyz = SV_GroupID.xyz * float3(ThreadDimX, ThreadDimY, ThreadDimZ) + SV_GroupThreadID.xyz;

共享内存和线程同步
在一个线程组内,允许设置一片共享内存区域,使得当前线程组内的所有线程都可以访问当前的共享内存。一旦设置,那么每个线程都会各自配备一份共享内存。共享内存的访问速度非常快,就像寄存器访问CPU缓存那样。
共享内存的声明方式如下:
groupshared float4 g_Cache[256];
对于每个线程组来说,它所允许分配的总空间最大为32kb(即8192个标量,或2048个向量)。内部线程通常应该使用SV_GroupThreadID来写入共享内存,这样以保证每个线程不会出现重复写入操作,而读取共享内存一般是线程安全的。
分配太多的共享内存会导致性能问题。假如一个多处理器支持32kb的共享内存,然后你的计算着色器需要20kb的共享内存,这意味着一个多处理器只适合处理一个线程组,因为剩余的共享内存不足以给新的线程组运行,这也会限制GPU的并行运算,当该线程组因为某些原因需要等待,会导致当前的多处理器处于闲置状态。因此保证一个多处理器至少能够处理两个或以上的线程组(比如每个线程组分配16kb以下的共享内存),以尽可能减少该多处理器的闲置时间。
现在来考虑下面的代码:
Texture2D g_Input : register(t0);
RWTexture2D<float4> g_Output : register(u0);
groupshared float4 g_Cache[256];
[numthreads(256, 1, 1)]
void CS(uint3 GTid : SV_GroupThreadID,
uint3 DTid : SV_DispatchThreadID)
{
// 将纹理像素值缓存到共享内存
g_Cache[GTid.x] = g_Input[DTid.xy];
// 取出共享内存的值进行计算
// 注意!!相邻的两个线程可能没有完成对纹理的采样
// 以及存储到共享内存的操作
float left = g_Cache[GTid.x - 1];
float right = g_Cache[GTid.x + 1];
// ...
}
因为多个线程同时运行,同一时间各个线程当前执行的指令有所偏差,有的线程可能已经完成了共享内存的赋值操作,有的线程可能还在进行纹理采样操作。如果当前线程正在读取相邻的共享内存片段,结果将是未定义的。为了解决这个问题,我们必须在读取共享内存之前让当前线程等待线程组内其它的所有线程完成写入操作。这里我们可以使用GroupMemoryBarrierWithGroupSync函数:
Texture2D g_Input : register(t0);
RWTexture2D<float4> g_Output : register(u0);
groupshared float4 g_Cache[256];
[numthreads(256, 1, 1)]
void CS(uint3 GTid : SV_GroupThreadID,
uint3 DTid : SV_DispatchThreadID)
{
// 将纹理像素值缓存到共享内存
g_Cache[GTid.x] = g_Input[DTid.xy];
// 等待所有线程完成写入
GroupMemoryBarrierWithGroupSync();
// 现在读取操作是线程安全的,可以开始进行计算
float left = g_Cache[GTid.x - 1];
float right = g_Cache[GTid.x + 1];
// ...
}
双调排序
双调序列
所谓双调序列(Bitonic Sequence),是指由一个非严格递增序列X(允许相邻两个数相等)和非严格递减序列Y构成的序列,比如序列 ( 5 , 3 , 2 , 1 , 4 , 6 , 6 , 12 ) (5, 3, 2, 1, 4, 6, 6, 12) (5,3,2,1,4,6,6,12)。
定义:一个序列 a 1 , a 2 , . . . , a n a_1 , a_2, ..., a_n a1,a2,...,an是双调序列,需要满足下面条件:
- 存在一个 a k ( 1 < = k < = n ) a_k(1 <= k <= n) ak(1<=k<=n),使得 a 1 > = . . . > = a k < = . . . < = a n a_1 >= ... >= a_k <= ... <= a_n a1>=...>=ak<=...<=an成立,或者 a 1 < = . . . < = a k > = . . . > = a n a_1 <= ... <= a_k >= ... >= a_n a1<=...<=ak>=...>=an成立;
- 序列循环移位后仍能够满足条件(1)
Batcher归并网络
Batcher归并网络是由一系列Batcher比较器组成的,Batcher比较器是指在两个输入端给定输入值x和y,再在两个输出端输出最大值 m a x ( x , y ) max(x, y) max(x,y)和最小值 m i n ( x , y ) min(x, y) min(x,y)。
双调归并网络
双调归并网络是基于Batch定理而构建的。该定理是说将任意一个长为2n的双调序列分为等长的两半X和Y,将X中的元素与Y中的元素按原序比较,即 a i a_i ai与 a i + n ( i < = n ) a_{i+n}(i <= n) ai+n(i<=n)比较,将较大者放入MAX序列,较小者放入MIN序列。则得到的MAX序列和MIN序列仍然是双调序列,并且MAX序列中的任意一个元素不小于MIN序列中的任意一个元素。
根据这个原理,我们可以将一个n元素的双调序列通过上述方式进行比较操作来得到一个MAX序列和一个MIN序列,然后对这两个序列进行递归处理,直到序列不可再分割为止。最终归并得到的为一个有序序列。
这里我们用一张图来描述双调排序的全过程:

其中箭头方向指的是两个数交换后,箭头段的数为较大值,圆点段的数为较小值。
我们可以总结出如下规律:
- 每一趟排序结束会产生连续的双调序列,除了最后一趟排序会产生我们所需要的单调序列
- 对于2^k个元素的任意序列,需要进行k趟排序才能产生单调序列
- 对于由 2 k − 1 2^{k-1} 2k−1个元素的单调递增序列和 2 k − 1 2^{k-1} 2k−1个元素的单调递减序列组成的双调序列,需要进行k趟交换才能产生2^k个元素的单调递增序列
- 在第n趟排序中的第m趟交换,若两个比较数中较小的索引值为i,那么与之进行交换的数索引为 i + 2 n − m i+2^{n-m} i+2n−m
双调排序的空间复杂度为 O ( n ) O(n) O(n),时间复杂度为 O ( n ( l g ( n ) ) 2 ) O(n{(lg(n))}^2) O(n(lg(n))2),看起来比 O ( n l g ( n ) ) O(nlg(n)) O(nlg(n))系列的排序算法慢上一截,但是得益于GPU的并行计算,可以看作同一时间内有n个线程在运行,使得最终的时间复杂度可以降为 O ( ( l g ( n ) ) 2 ) O({(lg(n))}^2) O((lg(n))2),效率又上了一个档次。
需要注意的是,双调排序要求排序元素的数目为 2 k , ( k > = 1 ) 2^k, (k>=1) 2k,(k>=1),如果元素个数为 2 k < n < 2 k + 1 2^k < n < 2^{k+1} 2k<n<2k+1,则需要填充数据到 2 k + 1 2^{k+1} 2k+1个。若需要进行升序排序,则需要填充足够的最大值;若需要进行降序排序,则需要填充足够的最小值。
排序核心代码实现
本HLSL实现参考了directx-sdk-samples,虽然里面的实现看起来比较简洁,但是理解它的算法实现费了我不少的时间。个人以自己能够理解的形式对它的实现进行了修改,因此这里以我这边的实现版本来讲解。
首先是排序需要用到的资源和常量缓冲区,定义在BitonicSort.hlsli:
// BitonicSort.hlsli
Buffer<uint> g_Input : register(t0);
RWBuffer<uint> g_Data : register(u0);
cbuffer CB : register(b0)
{
uint g_Level; // 2^需要排序趟数
uint g_DescendMask; // 下降序列掩码
uint g_MatrixWidth; // 矩阵宽度(要求宽度>=高度且都为2的倍数)
uint g_MatrixHeight; // 矩阵高度
}
然后是核心的排序算法:
// BitonicSort_CS.hlsl
#include "BitonicSort.hlsli"
#define BITONIC_BLOCK_SIZE 512
groupshared uint shared_data[BITONIC_BLOCK_SIZE];
[numthreads(BITONIC_BLOCK_SIZE, 1, 1)]
void CS(uint3 Gid : SV_GroupID,
uint3 DTid : SV_DispatchThreadID,
uint3 GTid : SV_GroupThreadID,
uint GI : SV_GroupIndex)
{
// 写入共享数据
shared_data[GI] = g_Data[DTid.x];
GroupMemoryBarrierWithGroupSync();
// 进行排序
for (uint j = g_Level >> 1; j > 0; j >>= 1)
{
uint smallerIndex = GI & ~j;
uint largerIndex = GI | j;
bool isDescending = (bool) (g_DescendMask & DTid.x);
bool isSmallerIndex = (GI == smallerIndex);
uint result = ((shared_data[smallerIndex] <= shared_data[largerIndex]) == (isDescending == isSmallerIndex)) ?
shared_data[largerIndex] : shared_data[smallerIndex];
GroupMemoryBarrierWithGroupSync();
shared_data[GI] = result;
GroupMemoryBarrierWithGroupSync();
}
// 保存结果
g_Data[DTid.x] = shared_data[GI];
}
可以看到,我们实际上可以将递归过程转化成迭代来实现。
现在我们先从核心排序算法讲起,由于受到线程组的线程数目、共享内存大小限制,这里定义一个线程组包含512个线程,即一个线程组最大允许排序的元素数目为512。共享内存在这是用于临时缓存中间排序的结果。
首先,我们需要将数据写入共享内存中:
// 写入共享数据
shared_data[GI] = g_Data[DTid.x];
GroupMemoryBarrierWithGroupSync();
接着就是要开始递归排序的过程,其中g_Level的含义为单个双调序列的长度,它也说明了需要对该序列进行
l
g
(
g
L
e
v
e
l
)
lg(g_Level)
lg(gLevel)趟递归交换。
在一个线程中,我们仅知道该线程对应的元素,但现在我们还需要做两件事情:
- 找到需要与该线程对应元素进行Batcher比较的另一个元素
- 判断当前线程对应元素与另一个待比较元素相比,是较小索引还是较大索引
这里用到了位运算的魔法。先举个例子,当前j为4,则待比较两个元素的索引分别为2和6,这两个索引值的区别在于索引2(二进制010)和索引6(二进制110),前者二进制第三位为0,后者二进制第三位为1.
但只要我们知道上述其中的一个索引,就可以求出另一个索引。较小索引值的索引可以通过屏蔽二进制的第三位得到,而较大索引值的索引可以通过按位或运算使得第三位为1来得到:
uint smallerIndex = GI & ~j;
uint largerIndex = GI | j;
bool isSmallerIndex = (GI == smallerIndex);
然后就是判断当前元素是位于当前趟排序完成后的递增序列还是递减序列,比如序列
(
4
,
6
,
4
,
3
,
5
,
7
,
2
,
1
)
(4, 6, 4, 3, 5, 7, 2, 1)
(4,6,4,3,5,7,2,1),现在要进行第二趟排序,那么前后4个数将分别生成递增序列和递减序列,我们可以设置g_DescendMask的值为4(二进制100),这样二进制索引范围在100到111的值(对应十进制4-7)处在递减序列,如果这个双调序列长度为16,那么索引4-7和12-15的两段序列都可以通过g_DescendMask来判断出处在递减序列:
bool isDescending = (bool) (g_DescendMask & DTid.x);
最后就是要确定当前线程对应的共享内存元素需要得到较小值,还是较大值了。这里又以一个双调序列
(
2
,
5
,
7
,
4
)
(2, 5, 7, 4)
(2,5,7,4)为例,待比较的两个元素为5和4,当前趟排序会将它变为单调递增序列,即所处的序列为递增序列,当前线程对应的元素为5,shared_data[smallerIndex] <= shared_data[largerIndex]的比较结果为>,那么它将拿到(较小值)较大索引的值。经过第一趟交换后将变成
(
2
,
4
,
7
,
5
)
(2, 4, 7, 5)
(2,4,7,5),第二趟交换就不讨论了。
根据对元素所处序列、元素当前索引和比较结果的讨论,可以产生出八种情况(代码注释没更新的,以本文为准):
| 所处序列 | 当前索引 | 比较结果 | 取值结果 |
|---|---|---|---|
| 递减 | 小索引 | <= | (较大值)较大索引的值 |
| 递减 | 大索引 | <= | (较小值)较小索引的值 |
| 递增 | 小索引 | <= | (较小值)较小索引的值 |
| 递增 | 大索引 | <= | (较大值)较大索引的值 |
| 递减 | 小索引 | > | (较大值)较小索引的值 |
| 递减 | 大索引 | > | (较小值)较大索引的值 |
| 递增 | 小索引 | > | (较小值)较大索引的值 |
| 递增 | 大索引 | > | (较大值)较小索引的值 |
显然现有的变量判断较大/较小索引值比判断较大值/较小值容易得多。上述结果表可以整理成下面的代码:
uint result = ((shared_data[smallerIndex] <= shared_data[largerIndex]) == (isDescending == isSmallerIndex)) ?
shared_data[largerIndex] : shared_data[smallerIndex];
GroupMemoryBarrierWithGroupSync();
shared_data[GI] = result;
GroupMemoryBarrierWithGroupSync();
在C++中,现在有如下资源和着色器:
ComPtr<ID3D11Buffer> m_pConstantBuffer; // 常量缓冲区
ComPtr<ID3D11Buffer> m_pTypedBuffer1; // 有类型缓冲区1
ComPtr<ID3D11Buffer> m_pTypedBuffer2; // 有类型缓冲区2
ComPtr<ID3D11Buffer> m_pTypedBufferCopy; // 用于拷贝的有类型缓冲区
ComPtr<ID3D11UnorderedAccessView> m_pDataUAV1; // 有类型缓冲区1对应的无序访问视图
ComPtr<ID3D11UnorderedAccessView> m_pDataUAV2; // 有类型缓冲区2对应的无序访问视图
ComPtr<ID3D11ShaderResourceView> m_pDataSRV1; // 有类型缓冲区1对应的着色器资源视图
ComPtr<ID3D11ShaderResourceView> m_pDataSRV2; // 有类型缓冲区2对应的着色器资源视图
然后就是对512个元素进行排序的部分代码(size为2的次幂):
void GameApp::SetConstants(UINT level, UINT descendMask, UINT matrixWidth, UINT matrixHeight);
//
// GameApp::GPUSort
//
m_pd3dImmediateContext->CSSetShader(m_pBitonicSort_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pDataUAV1.GetAddressOf(), nullptr);
// 按行数据进行排序,先排序level <= BLOCK_SIZE 的所有情况
for (UINT level = 2; level <= size && level <= BITONIC_BLOCK_SIZE; level *= 2)
{
SetConstants(level, level, 0, 0);
m_pd3dImmediateContext->Dispatch((size + BITONIC_BLOCK_SIZE - 1) / BITONIC_BLOCK_SIZE, 1, 1);
}
给更多的数据排序
上述代码允许我们对元素个数为2到512的序列进行排序,但缓冲区的元素数目必须为2的次幂。由于在CS4.0中,一个线程组最多允许一个线程组包含768个线程,这意味着双调排序仅允许在一个线程组中对最多512个元素进行排序。
接下来我们看一个例子,假如有一个16元素的序列,然而线程组仅允许包含最多4个线程,那我们将其放置在一个4x4的矩阵内:
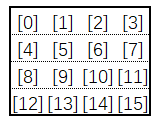
然后对矩阵转置:

可以看到,通过转置后,列数据变换到行数据的位置,这样我们就可以进行跨度更大的交换操作了。处理完大跨度的交换后,我们再转置回来,处理行数据即可。
现在假定我们已经对行数据排完序,下图演示了剩余的排序过程:

但是在线程组允许最大线程数为4的情况下,通过二维矩阵最多也只能排序16个数。。。。也许可以考虑三维矩阵转置法,这样就可以排序64个数了哈哈哈。。。
不过还有一个情况我们要考虑,就是元素数目不为(2x2)的倍数,无法构成一个方阵,但我们也可以把它变成对两个方阵转置。这时矩阵的宽是高的两倍:

由于元素个数为32,它的最大索引跨度为16,转置后的索引跨度为2,不会越界到另一个方阵进行比较。但是当g_Level到32时,此时进行的是单调排序,g_DescendMask也必须设为最大值32(而不是4),避免产生双调序列。
通过下面的转置算法,使得原本只能排序512个数的算法现在可以排序最大262144个数了。
负责转置的着色器实现如下:
// MatrixTranspose_CS.hlsl
#include "BitonicSort.hlsli"
#define TRANSPOSE_BLOCK_SIZE 16
groupshared uint shared_data[TRANSPOSE_BLOCK_SIZE * TRANSPOSE_BLOCK_SIZE];
[numthreads(TRANSPOSE_BLOCK_SIZE, TRANSPOSE_BLOCK_SIZE, 1)]
void CS(uint3 Gid : SV_GroupID,
uint3 DTid : SV_DispatchThreadID,
uint3 GTid : SV_GroupThreadID,
uint GI : SV_GroupIndex)
{
uint index = DTid.y * g_MatrixWidth + DTid.x;
shared_data[GI] = g_Input[index];
GroupMemoryBarrierWithGroupSync();
uint2 outPos = DTid.yx % g_MatrixHeight + DTid.xy / g_MatrixHeight * g_MatrixHeight;
g_Data[outPos.y * g_MatrixWidth + outPos.x] = shared_data[GI];
}
最后是GPU排序用的函数:
#define BITONIC_BLOCK_SIZE 512
#define TRANSPOSE_BLOCK_SIZE 16
void GameApp::GPUSort()
{
UINT size = (UINT)m_RandomNums.size();
m_pd3dImmediateContext->CSSetShader(m_pBitonicSort_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pDataUAV1.GetAddressOf(), nullptr);
// 按行数据进行排序,先排序level <= BLOCK_SIZE 的所有情况
for (UINT level = 2; level <= size && level <= BITONIC_BLOCK_SIZE; level *= 2)
{
SetConstants(level, level, 0, 0);
m_pd3dImmediateContext->Dispatch((size + BITONIC_BLOCK_SIZE - 1) / BITONIC_BLOCK_SIZE, 1, 1);
}
// 计算相近的矩阵宽高(宽>=高且需要都为2的次幂)
UINT matrixWidth = 2, matrixHeight = 2;
while (matrixWidth * matrixWidth < size)
{
matrixWidth *= 2;
}
matrixHeight = size / matrixWidth;
// 排序level > BLOCK_SIZE 的所有情况
ComPtr<ID3D11ShaderResourceView> pNullSRV;
for (UINT level = BITONIC_BLOCK_SIZE * 2; level <= size; level *= 2)
{
// 如果达到最高等级,则为全递增序列
if (level == size)
{
SetConstants(level / matrixWidth, level, matrixWidth, matrixHeight);
}
else
{
SetConstants(level / matrixWidth, level / matrixWidth, matrixWidth, matrixHeight);
}
// 先进行转置,并把数据输出到Buffer2
m_pd3dImmediateContext->CSSetShader(m_pMatrixTranspose_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetShaderResources(0, 1, pNullSRV.GetAddressOf());
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pDataUAV2.GetAddressOf(), nullptr);
m_pd3dImmediateContext->CSSetShaderResources(0, 1, m_pDataSRV1.GetAddressOf());
m_pd3dImmediateContext->Dispatch(matrixWidth / TRANSPOSE_BLOCK_SIZE,
matrixHeight / TRANSPOSE_BLOCK_SIZE, 1);
// 对Buffer2排序列数据
m_pd3dImmediateContext->CSSetShader(m_pBitonicSort_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->Dispatch(size / BITONIC_BLOCK_SIZE, 1, 1);
// 接着转置回来,并把数据输出到Buffer1
SetConstants(matrixWidth, level, matrixWidth, matrixHeight);
m_pd3dImmediateContext->CSSetShader(m_pMatrixTranspose_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->CSSetShaderResources(0, 1, pNullSRV.GetAddressOf());
m_pd3dImmediateContext->CSSetUnorderedAccessViews(0, 1, m_pDataUAV1.GetAddressOf(), nullptr);
m_pd3dImmediateContext->CSSetShaderResources(0, 1, m_pDataSRV2.GetAddressOf());
m_pd3dImmediateContext->Dispatch(matrixWidth / TRANSPOSE_BLOCK_SIZE,
matrixHeight / TRANSPOSE_BLOCK_SIZE, 1);
// 对Buffer1排序剩余行数据
m_pd3dImmediateContext->CSSetShader(m_pBitonicSort_CS.Get(), nullptr, 0);
m_pd3dImmediateContext->Dispatch(size / BITONIC_BLOCK_SIZE, 1, 1);
}
}
最后是std::sort和双调排序(使用NVIDIA GTX 850M)的比较结果:
| 元素数目 | CPU****排序(s) | GPU****排序(s) | GPU****排序+写回内存总时(s) |
|---|---|---|---|
| 512 | 0.000020 | 0.000003 | 0.000186 |
| 1024 | 0.000043 | 0.000007 | 0.000226 |
| 2048 | 0.000102 | 0.000009 | 0.000310 |
| 4096 | 0.000245 | 0.000009 | 0.000452 |
| 8192 | 0.000512 | 0.000010 | 0.000771 |
| 16384 | 0.001054 | 0.000012 | 0.000869 |
| 32768 | 0.002114 | 0.000012 | 0.001819 |
| 65536 | 0.004448 | 0.000014 | 0.002625 |
| 131072 | 0.009600 | 0.000015 | 0.005130 |
| 262144 | 0.021555 | 0.000021 | 0.008983 |
| 524288 | 0.048621 | 0.000030 | 0.015652 |
| 1048576 | 0.111219 | 0.000044 | 0.040927 |
| 2097152 | 0.257118 | 0.000072 | 0.188662 |
| 4194304 | 0.444995 | 0.000083 | 0.300240 |
| 8388608 | 0.959173 | 0.000124 | 0.465746 |
| 16777216 | 2.178453 | 0.000177 | 0.915898 |
| 33554432 | 5.869439 | 0.000361 | 2.269989 |
可以初步看到双调排序的排序用时比较稳定,而快速排序明显随元素数目增长而变慢。当然,如果GPU排序的数据量再更大一些的话,可以看到时间的明显增长。
但是!如果你用GPU排序后需要取回到CPU,因为GPU->CPU的速度比较慢,并且需要等待资源结束占用才能开始取出,故需要排较大数目的数据(约10000以上)才有明显效益
DirectX11 With Windows SDK完整目录
欢迎加入QQ群: 727623616 可以一起探讨DX11,以及有什么问题也可以在这里汇报。

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)