
Ubuntu 下 PySpark 安装
目录1、什么是 Apache Spark?2、spark安装(python版本)3、在jupyter notebook中使用PySpark 1、什么是 Apache Spark?Apache Spark 是一种用于处理、查询和分析大数据的快速集群计算框架。Apache Spark 是基于内存计算,这是他与其他几种大数据框架相比的一大优势。Apache Spark 是开源的,...
目录
1、什么是 Apache Spark?
2、spark安装(python版本)
3、在jupyter notebook中使用PySpark
1、什么是 Apache Spark?
Apache Spark 是一种用于处理、查询和分析大数据的快速集群计算框架。Apache Spark 是基于内存计算,这是他与其他几种大数据框架相比的一大优势。Apache Spark 是开源的,也是最著名的大数据框架之一。当它使用内存计算时,它比传统map-reduce任务快100倍;当它使用磁盘时比传统的map-reduce 任务快10倍。
Apache Spark的历史
Apache Spark 最初于2009年在加州大学伯克利分校的AMPLab创建。Spark 代码库后来被捐赠给Apache Software Foundation。 随后,他在2010年开源,spark 主要是用Scala语言编写的,也有一部分代码是用Java,Python和R编写的。 Apache Spark也为程序员提供了几个API,包括 Java,Scala,Python和R。
Apache Spark 如何比传统的大数据框架更好?
内存计算: Apache Spark的最大优势在于它可以将数据保存在RAM中或从RAM中加载数据,而不是从磁盘(硬盘驱动器)中加载数据。如果我们谈论内存层次结构,RAM具有比硬盘驱动器高得多的处理速度(如下图所示)。由于内存价格在过去几年中显着下降,因此内存计算已经获得了很大的发展势头。Spark使用内存计算加速比Hadoop框架快100倍。
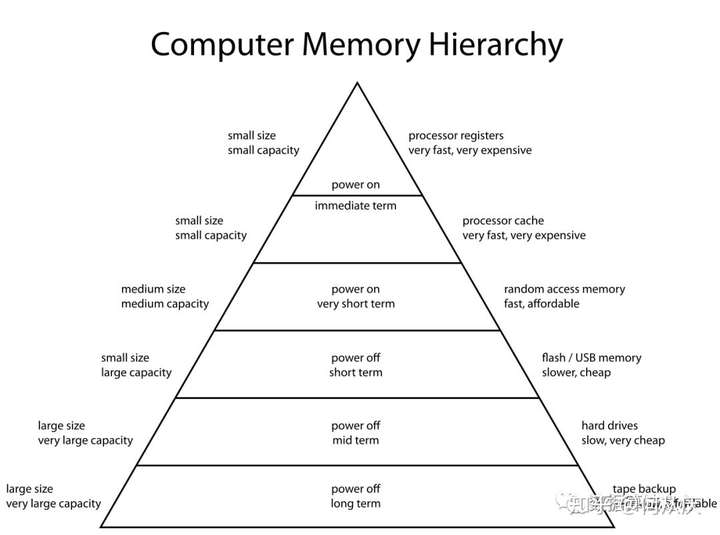
在Hadoop中,任务分布在集群的节点之间,从而将数据保存在磁盘上。当需要处理该数据时,每个节点必须从磁盘加载数据并在执行操作后将数据保存到磁盘中。此过程最终会增加速度和时间方面的成本,因为磁盘操作比RAM操作慢得多。在将数据从RAM写入磁盘时,还需要时间来转换特定格式的数据。此转换称为序列化,反向称为反序列化。
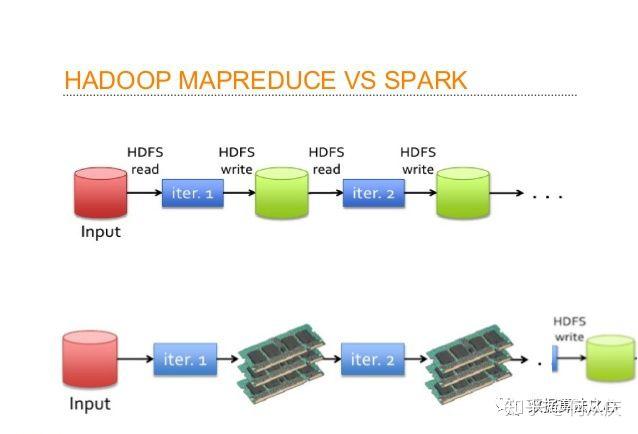
让我们看一下MapReduce过程,以更好地理解内存计算的优势。假设,有几个map-reduce任务一个接一个地发生。在计算开始时,两种技术(Hadoop和Spark)都从磁盘读取数据以进行映射。Hadoop执行映射操作并将结果保存回硬盘驱动器。但是,在Apache Spark的情况下,结果存储在RAM中。
在下一步(Reduce操作)中,Hadoop从硬盘中读取保存的数据,Apache Spark从RAM中读取数据。这会在单个MapReduce操作中产生差异。现在想象一下,如果有多个map-reduce操作,那么在任务完成结束时你会看到多少时差。
语言支持: Apache Spark为流行的数据科学语言提供API支持,如Python,R,Scala和Java。
支持实时和批处理: Apache Spark支持“批量数据”处理,其中在一段时间内收集一组事务。它还支持实时数据处理,其中数据从源连续流动。例如,Apache Spark可以直接处理来自传感器的天气信息。
延迟操作: 延迟操作用于优化Apache Spark中的解决方案。我将在本文后面部分讨论延迟评估。现在,我们可以认为有些操作在我们需要结果之前不会执行。
支持多种转换和操作: Apache Spark相对于Hadoop的另一个优点是Hadoop仅支持MapReduce,但Apache Spark支持许多转换和操作,包括MapReduce。
与Hadoop相比,Apache Spark还有其他优点。例如,Apache Spark在执行Map side shuffling 和 Reduce side shuffling 时要快得多。然而,shuffling 本身就是一个复杂的话题,需要整篇文章本身。因此,我在这里不再详细讨论它。
2、使用pyspark 安装Apache Spark
我们可以通过许多不同的方式安装Apache Spark。安装Apache Spark的最简单方法是从单台机器上安装开始。要在一台机器上安装,我们需要满足某些要求。下面我分享下在Ubuntu(16.04)中安装PySpark 2.4.0版本的步骤。
操作系统:Ubuntu 16.04,64位。
所需软件: Java 8 +,Python 3.5 +, Scala 2.11.12+
安装步骤:
Step 1: Java 8安装
sudo apt-get update
sudo apt-get install openjdk-8-jdk
java -version
安装成功后,会显示如下画面:

Step 2: 如果Java安装完成后,我们安装Scala。
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.deb
sudo dpkg -i scala-2.12.8.deb
scala -version
安装成功后,会显示如下画面:

Step 3: 安装 py4j
Py4J在驱动程序上用于Python和Java SparkContext对象之间的本地通信;大型数据传输是通过不同的机制执行的。
sudo pip install py4j
Step 4: 安装 Spark
到目前为止,我们已经安装了安装Apache Spark所需的依赖项。接下来,我们需要下载并提取spark-2.4.0-bin-hadoop2.7.tgz 。
wget http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
tar xvf spark-2.4.0-bin-hadoop2.7.tgz
在通过编辑bashrc文件将其添加到路径中:
vim ~/.bashrc
在bashrc文件中添加环境变量(具体SPARK_HOME路径自己设定)
export SPARK_HOME=/home/ubuntu/spark-2.4.0-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:$PATH
最后激活环境变量
source ~/.bashrc
Step 5: 到目前为止,我们的spark基本安装成功,下面我们来启动pyspark
启动pyspark的命令如下:
pyspark
退出命令如下:
exit()
Step 6: 另外,安装完成后,我们可以通过输入来检查Spark是否正常运行。
./bin/run-example SparkPi 10
会发现如下图所示:
咦!!! 咋不能运行呢?
如果想查看上述运行的结果,我们还需要配置个环境。需要降低
log4j.properties中 log4j记录器的详细级别。
cp conf/log4j.properties.template conf/log4j.properties
vim conf/log4j.properties
打开文件 'log4j.properties' 后,我们需要替换以下行:
将
log4j.rootCategory=INFO, console
替换为
log4j.rootCategory=ERROR, console
然后我们再次运行
./bin/run-example SparkPi 10
会发现结果如下图所示:

最后我们来写一段pyspark的代码来测试下,打开我们的pyspark环境,输入:
from pyspark import SparkContext
from pyspark import SparkConf
data = list(range(1,1000))
rdd = sc.parallelize(data)
rdd.collect()
会发现完美运行!!!整个pyspark的单机版就安装好了!
3、在jupyter notebook中使用pyspark
在命令行中写pyspark好像有点麻烦,我们是不是也能像python一样在jupyter中写pyspark呢,答案是可以的。
有两种方法可以配置我们的环境:
第一种:更新PySpark驱动程序环境变量:将下面这些行添加到~/.bashrc文件中。
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
重新启动终端并再次启动PySpark:
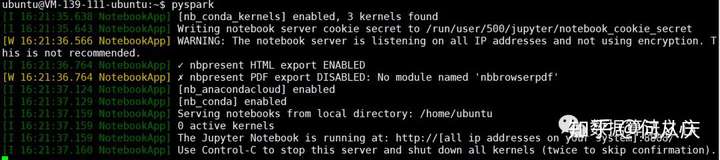
好像变成了我们的jupyter界面了呢!然后其他的操作就是和使用jupyter 一样了。
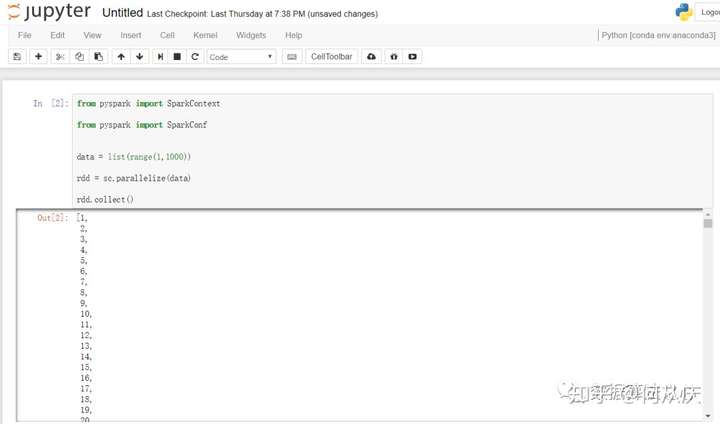
完美运行!
第二种:在Jupyter Notebook中使用PySpark还有另一种更通用的方法:使用findSpark包在代码中提供Spark Context。 findSpark包不是特定于Jupyter Notebook,你也可以在你喜欢的IDE中使用这个技巧。 要安装findspark:
pip install findspark
然后打开jupyter notebook:
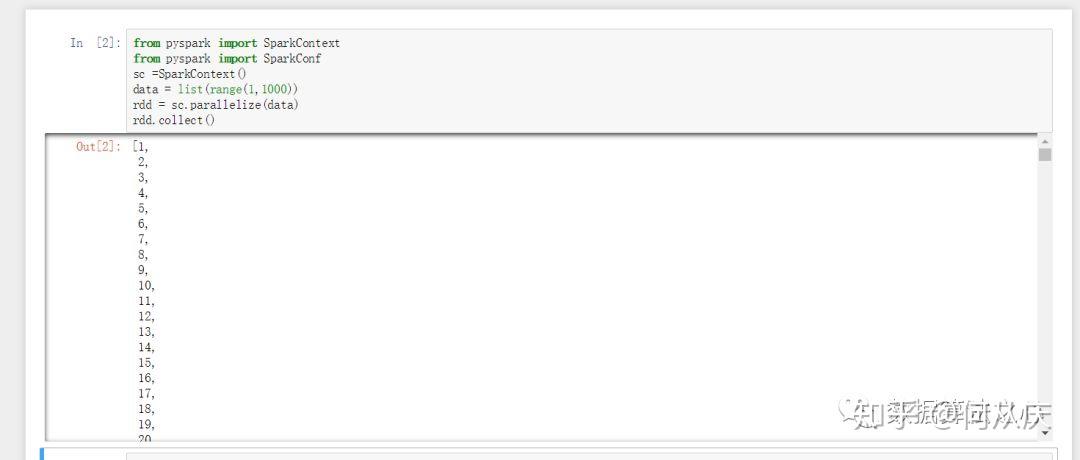
本次pyspark的安装就介绍到这里了,如果哪里有问题,欢迎指出!谢谢!
更多个人笔记欢迎关注:
公众号:AI_TIMO(数据算法之心)
知乎专栏:https://www.zhihu.com/people/yuquanle/columns
参考:

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)