
#Python3中tornado高并发框架
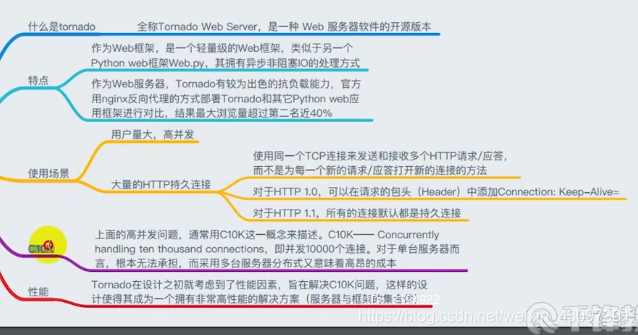
Python3中tornado高并发框架简介:Tornado是一种 Web 服务器软件的开源版本。Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。得利于其非阻塞的方式和对epoll的运用,Tornado 每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个 理想框架。torna...
Python3中tornado高并发框架
简介:
Tornado是一种 Web 服务器软件的开源版本。Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快。
得利于其非阻塞的方式和对epoll的运用,Tornado 每秒可以处理数以千计的连接,因此 Tornado 是实时 Web 服务的一个 理想框架。
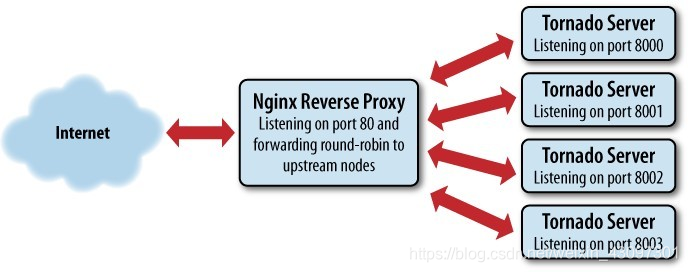
反向代理服务器后端的Tornado实例:
1.单线程
tornado.web:基础web框架模块
tornado.ioloop:核心IO循环模块,高效的基础。封装了:
1.asyncio 协程,异步处理
2. epoll模型:水平触发(状态改变就询问,select(),poll()), 边缘触发(一直询问,epoll())
3.poll 模型:I/O多路复用技术
4.BSD(UNIX操作系统中的一个分支的总称)的kqueue(kueue是在UNIX上比较高效的IO复用技术)
epoll和kqueue的区别如下:
'epoll'仅适用于文件描述符,在Unix中,一切都是文件”。
这大多是正确的,但并非总是如此。例如,计时器不是文件。
信号不是文件。信号量不是文件。进程不是文件。
(在Linux中)网络设备不是文件。类UNIX操作系统中有许多不是文件的东西
。您不能使用select()/ poll()/ epoll来复制那些“事物”。
Linux支持许多补充系统调用,signalfd(),eventfd()和timerfd_create()
它们将非文件资源转换为文件描述符,以便您可以将它们与epoll()复用。
epoll甚至不支持所有类型的文件描述符;
select()/ poll()/ epoll不适用于常规(磁盘)文件。
因为epoll 对准备模型有很强的假设; 监视套接字的准备情况,
以便套接字上的后续IO调用不会阻塞。但是,磁盘文件不适合此模型,因为它们总是准备就绪。
kqueue 中,通用的(struct kevent)系统结构支持各种非文件事件
import tornado.web #tornado.web:基础web框架模块
import tornado.ioloop #tornado.ioloop:核心IO循环模块,高效的基础。
class IndexHandler(tornado.web.RequestHandler):
#类比Django中的视图,相当于业务逻辑处理的类
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
"""
实例化一个app对象
Application:他是tornado.web框架的核心应用类,是与服务器对应的一个接口
里面保存了路由映射表,还有一个listen方法,可以认为用来创建一个http的实例
并绑定了端口
"""
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
app.listen(8888) #绑定监听端口,但此时的服务器并没有开启监听
tornado.ioloop.IOLoop.current().start()
#Application([(r"/" ,IndexHandler),])传入的第一个参数是
#路由路由映射列表,但是在此同时Application还能定义更多参数
#IOLoop.current():返回当前线程的IOLoop实例
#例如实例化对象 ss=run() ,ss.start()
#start():启动了IOloop实例的循环,连接客服端后,同时开启了监听
原理如下:
linux-epoll进行管理多个客服端socket
tornado-IoLoop不断进行询问epoll:小老弟,有没有我需要做的事吗?
当epoll返回说:老哥,有活了
tornado-IoLoop将活上传给tornado.web.Application
tornado.web.Application中有 路由映射表
就会将socket进行一个路由匹配
把socket匹配给相对应的Handler(处理者)
Handler(处理者)处理后将数据返回给对应的socket,
(这里因为可能会延时响应,所以这里进行异步处理)
socket然后再传给了客服端浏览器。
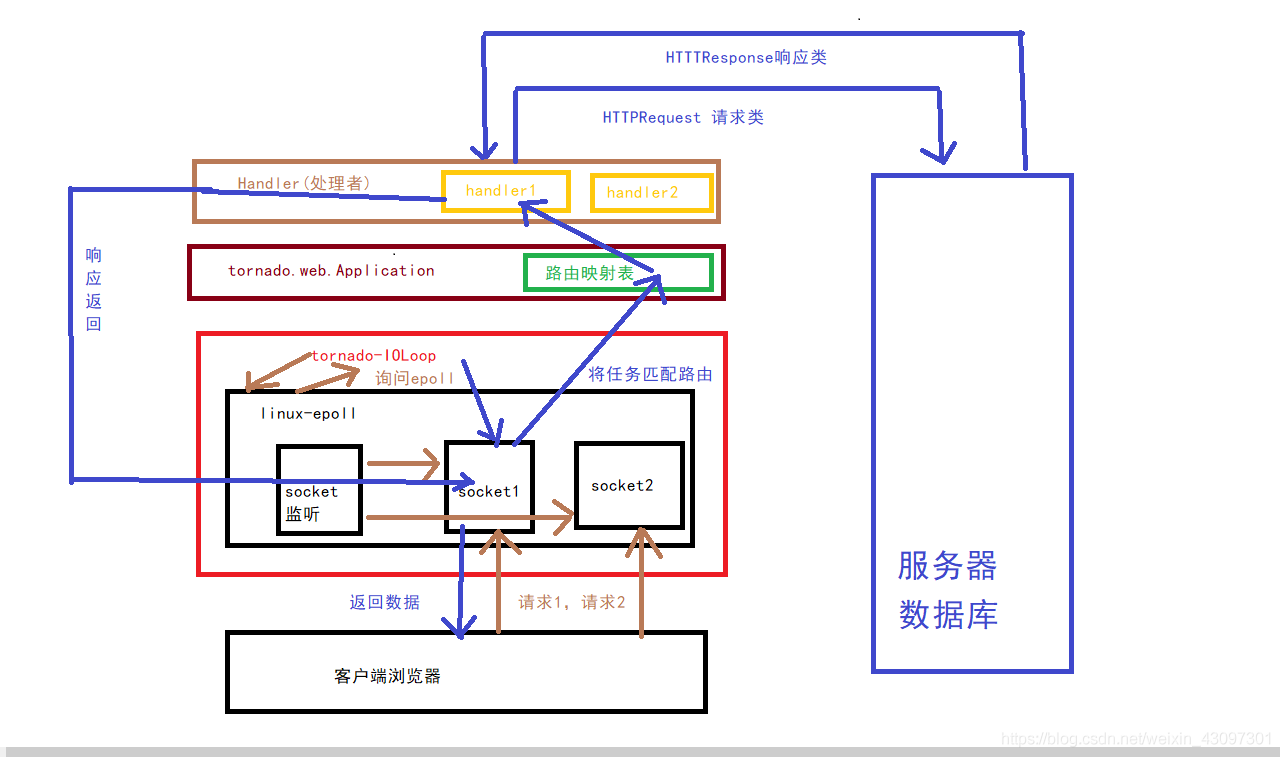
图片将就看啊,手残党。。
2.多线程
新加模块如下:
tornado.httpserver #tornado的HTTP服务器实现
注意:
在windows中运行多进程会报错:
AttributeError: module ‘os’ has no attribute 'fork’
这是因为fork这个系统命令,只在linux中才有用,
如果你是在windows, win7、winxp中运行的话就会出错。
所以把上面的python文件,拷贝到linux的系统中再运行就没问题了.
这个错误我暂时没有解决,后续补上。
import tornado.web
import tornado.ioloop
import tornado.httpserver #tornado的HTTP服务器实现
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(8888) #绑定在指定端口
httpServer.start(2)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
#app.listen(),只能在单进程中使用
#多进程中,虽然torna给我们提供了一次性启动多个进程的方式,但是由于一些问题,不建议使用上面打的方式启动多进程,而是手动启动多个进程,并且我们还能绑定不同的端口
问题如下:
#1.每个子进程都会从父进程中复制一份IOLoop的实例,
如果在创建子进程前修改了IOLoop,会影响所有的子进程
#2.所有的进程都是由一个命令启动的,无法做到不停止服务的情况下修改代码。
修改单个进程是需要关掉所有进程,影响客服服务使用。
#3.所有进程共享一个端口,向要分别监控很困难。
所以:我们手动启动多个进程,并且我们还能绑定不同的端口,进行单个进程操作。
3.options模块
新运用模块如下:
tornado.options模块:提供了全局参数的定义,储存和转换
属性和方法
tornado.options.define()
原型tornado.options.define(name, default=None, type=None, help=None, metavar=None,multiple=False, group=None, callback=None)
常用参数:
# name(选项变量名),必须保证其唯一性,
否则报错"options 'xxx' already define in '....'"
#default(设置选项变量的默认值),默认为None
#type(设置选项变量的类型),str,int,float,datetime(时间日期),等,
从命令行或配置文件导入参数时,会根据类型转换输入的值。
如果不能转化则报错,如果没有设置type的值,
会根据default的值的类型进行转换,比如default的值 8000,
而传给type的为‘8080’字符串,
则会转换成int类型。如果default也没有设置,则不转化
#multipe(设置选项变量是否为多个值),默认False 比如传递为列表,
列表包括了多个值,就要改为Ture。
#help 选项变量的提示信息。自主添加,比如 help="描述变量"
#方法
#tornado.options.options
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#获取参数的方法(命令行传入)
#1. tornado.options.parse_command_line()
#作用:转化命令行参数,接收转换并保存
#获取参数的方法(从配置文件导入参数)
#tornado.options.parse_config_file(path=)
1获取参数的方法(命令行传入)
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options #提供了全局参数的定义,储存和转换
from tornado.options import options #全局的options对象,所有定义的选项变量都会作为该对象的属性
#定义两个参数
tornado.options.define('port', default=8000, type=int)
tornado.options.define('list', default=[], type=str,multiple=True) #multiple=True接收多个值
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
tornado.options.parse_command_line()
#转化命令行参数,接收转换并保存在tornado.options.options里面
print('list',options.list)
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(options.port) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
#注意这里不能直接启动,应为没有进行传值,那要在怎么启动,用命令行cmd进行
#cmd进行当前py文件目录 python server.py --port=9000 --list=good,nice,cool
#启动
#> python server.py --port=9000 --list=good,nice,cool
#启动的时候就指定了端口号,就会启动指定端口号的服务器,也就是说我们不用每次用都去修改我们的代码的端口
#(输出)list ['good', 'nice', 'cool']
2.获取参数的方法(从配置文件导入参数)
将上面的代码中的tornado.options.parse_command_line()进行更改为
tornado.options.parse_config_file(“config”)
#"config"为配置文件,这里因为是在同一级目录下,所以直接写文件名,如果不在则需要进行书写路径。
#需要创建名为config的普通文件,作为配置文件
在里面进行书写配置。
config配置文件 例如:
port=7000
list=["job","good","nice"]
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options #提供了全局参数的定义,储存和转换
from tornado.options import options #全局的options对象,所有定义的选项变量都会作为该对象的属性
#定义两个参数
tornado.options.define('port', default=8000, type=int)
tornado.options.define('list', default=[], type=str,multiple=True) #multiple=True接收多个值
class IndexHandler(tornado.web.RequestHandler):
def get(self): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
tornado.options.parse_config_file("config")
#需要创建名为config的普通文件
print('list',options.list)
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
#httpServer.listen(8000) #多进程改动原来的这一句
httpServer.bind(options.port) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
说明:这两种方法以后都不常用,常用的是文件配置,但是是.py文件进行配置。
因为书写格式人需要按照Python的语法要求,并且普通的文件不支持字典类型
4.最终的py配置文件
创建config.py文件编写配置文件
#定义字典
#新建文件config.py文件,配置模型:
options = {
‘port’:8080,
‘list’:[‘good’,‘nicd’,‘job’]
}
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
import tornado1.config #直接导入配置的py文件
class IndexHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
if __name__=="__main__":
print('list=',tornado1.config.options["list"])
app = tornado.web.Application([
(r"/" ,IndexHandler),
])
httpServer = tornado.httpserver.HTTPServer(app)
httpServer.bind(tornado1.config.options["port"]) #绑定在指定端口
#全局的options对象,所有定义的选项变量都会作为该对象的属性
#这里就可以使用tornado.options.parse_command_line()保存的变量的值
httpServer.start(1)
#默认(0)开启一个进程,否则对面开启数值(大于零)进程
#值为None,或者小于0,则开启对应硬件机器的cpu核心数个子进程
#例如 四核八核,就四个进程或者八个进程
tornado.ioloop.IOLoop.current().start()
##其他的获取参数方式,
http://127.0.0.1:9000/error?flag=0
向error页面传递flag=0这个值,其中?表示传值
页面中接收flag
def get(self, *args, **kwargs):
flag = self.get_query_argument("flag")
get_query_argument()/get_query_arguments()/get_body_argument()/get_body_arguments()
上述四个获取值方法统一参数:(name, default=_ARG_DEFAULT, strip=True)
# name:获取name属性的值
default:设置默认值,如果没有参数传递过来,那么就是用默认值
strip: 去除左右空格
复制代码
# 使用get方式传递参数
def get(self):
# 获取单个键值
get_a = self.get_query_argument('a') # 如果同时传递多个a的参数,那么会采用后面覆盖前面的原则
self.write(get_a)
# 其中获取多个使用:get_query_arguments()
# 使用post传递参数
def post(self):
# 接收单个参数
post_a = self.get_body_argument('a')
self.write(post_a)
# 其中获取多个参数传递使用get_body_arguments()
复制代码
使用get_argument()/get_arguments()可以不区分post/get传递方式
def post(self):
# 接收单个参数
post_a = self.get_argument('a')
self.write(post_a)
# 其中获取多个参数传递使用get_arguments()
值得注意的是:使用上述方法获取参数只能够获取headers报头为"application/x-www-form-urlencoded"或者"multipart/form-data"的数据,如果想获取json或者xml方式传递的数据需要使用self.request方式获取
def post(self):
self.write(self.request.headers.get('Content-Type')) # 获取“application/json”类型传递
# 如果想获取内容,可以使用self.request.body
5.关闭日志logging=none
当我们使用命令行传递参数parse_command_line()或者配置文件parse_config_file(path)传递参数是,tornado会默认开启日志,向终端打印信息。
比如在传递参数parse_command_line()类型中。
python server.py --port=9000 --list=good,job,nice 启动py文件后
在进行网页登录本地地址(ipconfig可查看)192.168.22.33:7000进入后
cmd终端就会打印[I 181215 19:13:39 web:2162] 304 GET / (192.168.22.33) 1.00ms #I为信息(information) 或者 [W 181215 19:18:10 web:2162] 404 GET /index (192.168.43.145) 0.50ms #W为错误(wrong)
如果不想让终端打印
在tornado.options.parse_command_line()之前加上tornado.options.options.logging=None
或者在cmd中
python server.py --port=9000 --list=good,job,nice --logging=none
6.基本框架样式
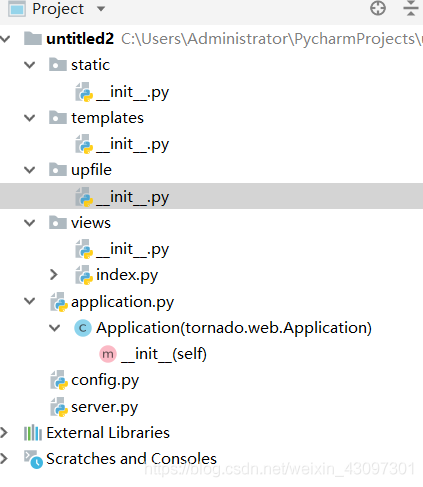
1.static文件夹-----------------静态页面存放
2.templates文件夹-----------模板存放
3.upfile文件夹----------------上传文件存放
4.views文件夹----------------视屏存放
5.application文件-------------视屏编写
6.config文件 ------------------配置文件编写
7.server文件------------------服务编写
1.server文件基本样式
import tornado.web #web框架模块
import tornado.ioloop #核心IO循环模块
import tornado.httpserver #tornado的HTTP服务
import tornado.options #全局参数定义,存储和转化模块
import config #导入自定义配置的py文件
import application #导入自定义的应用程序模块
"""
#server
服务设置
"""
if __name__=="__main__":
app = application.Application #处理请求服务类
httpServer = tornado.httpserver.HTTPServer(app) #设置HTTP服务器
httpServer.bind(config.options["port"]) #绑定在指定端口
httpServer.start(1) #线程数
tornado.ioloop.IOLoop.current().start() #启动
2.congif文件
"""
#config
存放参数
"""
options ={
"port" : 8000,
}
"""
#config
配置文件,相当于django里面的setting
配置application应用程序路由,即文件地址路径
##BASE_DIRS = os.path.dirname(__file__)
当前file文件路径
##os.path.join(BASE_DIRS,"static")
拼接路径:如(BASE_DIRS/static),当然BASE_DIRS=当前文件的父类的文件路径
"""
import os
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转义
"cookie_secret":"OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks", #混淆加密
"xsrf_cookies":True, #开启xsrf保护
"login_url":"/login",
}
3.application文件夹中Application
import tornado.web
from views import index
from config import setting #导入配置文件setting
"""
#application中设置一个函数子类Application
存放路由
"""
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
(r"/",index.IndexHandler)
#(r"/(.*)$",tornado.web.StaticFileHandler{"path":os.path.join(config.BASE_DIRS,"static/html"),"default_filename":"index.html"}),
#StaticFileHandler应用静态文件,注意要放在所有路由的下面。用来放静态主页
(r"/(.*)$", index.Static_FileHandler,{"path": os.path.join(config.BASE_DIRS, "static/html"), "default_filename": "index.html"}),
#由于我们想让用户进入主页即自动设置xsrf_cookie,所以我们用到继承 的方式,让index.StaticFileHandler继承父类tornado.web.StaticFileHandler,再向里面添加设置xsrf设置
]
super().__init__(handlers,**setting)
#super()函数是用于调用父类(超类)的一个方法。
#Python3可以使用直接使用super().xxx代替super(Class, self).xxx:
#执行的是tornado.web.Application的init,再将handlers传参
#添加配置文件,参数里面加入**setting,(即**kwargs)
4.views中的index基本样式
import tornado.web
from tornado.web import RequestHandler
"""
#views中的index
存放视图
"""
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
7.config文件,配置解析
import os
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"),
"template_path":os.path.join(BASE_DIRS,"templates"),
"debug":True
}
1.debug
debug:
设置tornado是否工作在调试模式下,默认为debug:False即工作在生产模式下(上线后)。
设置为True即在开发模式(开发中调试)。
debug:True特性如下:
##1.自动重启:
tornado应用会监控源代码文件,当有保存改动时重新启动服务器,会减少手动重启的时间和次数,提高开发效率。
但是:如果保存后代码有错误导致重启失败后,将会变为手动重启,再次重启可能由于之前的端口不是正常关闭,
而导致端口没有被释放,这时候重新切换端口,或者等待端口释放,即可。
如果只想引用这一个特性:通过编写 autoreload = True 进行设置,在config配置文件中字典模式"autoreload" : True
##2.取消缓存编译的模板
用于开放阶段:
修改代码后,并没有发生改变,是因为缓存的存在,并没有应该用达到实际文件上。
通过参数compiled.template_cache=False设置,但在配置文件中用字典形式"compiled.template_cache":False设置
##3.取消缓存静态文件的hash值
用于开发阶段:
加载css文件的时候,tornado中在css文件后面还有hash值(比如a.css?hash=jsajdjafahafasddasdfasdadsasd)
而取消后,相当于为新文件加载,后面得hash值就会变,这样我们就能看到每一次更改后的效果
可以通过参数设置static_hash_cache=False单独设置,配置文件中字典形式"static_hash_cache":False设置
##4.提供追踪信息(不常用)
没有捕获异常时,会生成一个追中页面的信息
可以通过参数serve_traceback=True设置 , 配置文件中字典形式"serve_traceback":True设置
2.static_path
设置静态文件目录
3.static_path
设置模板目录
8.application文件夹,路由解析
import tornado.web
from views import index
from config import setting #导入配置文件中的setting
"""
#application中设置一个函数子类Application
存放路由
##简单的形式(r"/",index.IndexHandler)
## 传参形式(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),这里是服务器自己传参,如果要进行用户传参,则对应修改编辑方法
"""
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
(r"/",index.IndexHandler),
(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),
(r"/write",index.WriteHandler),
(r"/json1",index.Json1Handler), #测试json1
(r"/json2", index.Json2Handler), #测试json2
(r"/header",index.HanderHander) , #响应头字段(Respose Headers)
(r"/status",index.StatuscodeHander), #状态码
tornado.web.url(r"/boy",index.BoyHandler,{"word3":"who","word4":"are you"},name="boy"), #反向解析
]
super().__init__(handlers,**setting)
#super()函数是用于调用父类(超类)的一个方法。
#Python3可以使用直接使用super().xxx代替super(Class, self).xxx:
#执行的是tornado.web.Application的init,再将handlers传参
#添加配置文件,参数里面加入**setting,(即**kwargs)
application中设置一个函数子类Application
存放路由
##简单的形式(r"/",index.IndexHandler)
##传参的形式(r"/good",index.GoodHandler,{"str1":"入门小白","str2":"高阶大神"}),
对应的在index里面建立对应GoodHandler类后,
定义接收函数def initialize(self,str1,str2),然后在调用str1,str2
这里是服务器自己传参,如果要进行用户传参,则对应修改编辑方法
9.views中的index,解析
#views中的index
存放视图
##def initialize
接收传递过来的参数,并以 self.参数=参数 形式进行绑定
##self.write
将chunk(数据块)数据写到缓冲区
##刷新缓冲区
self.finish
刷新缓冲区,并关闭当前请求通道,即后面的数据不在传输
##缓冲区的内容输出到浏览器不用等待请求处理完成
self. flush()
self.write()会先把内容放在缓冲区,正常情况下,当请求处理完成的时候会自动把缓冲区的内容输出到浏览器,但是可以调用 self.flush()方法,这样可以直接把缓冲区的内容输出到浏览器,不用等待请求处理完成.
##序列化
json,jsonStr = json.dumps()
需要导入json库,对应的Handler中编写字典, jsonStr = json.dumps(per) 将字典转化为json的字符串
#(浏览器输出){"name": "nick", "age": 18, "height:": 170, "weight": 70}
但是你会发现,其实我们不需要这样写,直接用write也能转化。json还要进行下文的设置响应头
但是前者json转化的在谷歌浏览器F12中Network中json1文本中的Respose Headers里面,
Content Type 为 text/heml,而后者write转换后为appliction/json。
text/heml浏览器会将这个当成页面进行渲染,所以应为json类型
###在线解析json数据结构 ,https://c.runoob.com/front-end/53
##设置响应头
self.set_header(name,value)
self.set_header("Content-Type","applictions/json;charset=UTF-8")
self.set_header("good","boy") #自定义设置
作用:手动设置一个名为name值为value的响应头字段(Respose Headers)
参数:name:字段名称
value:字段值
###text/html和text/plain的区别
1、text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
2、text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理
##默认的headers
set_default_headers()
作用:
def set_default_headers(self):
在进入http响应方法之前被调用,可以重写该方法来预先设置默认的headers
这样类下面的各种方法都不用再去设置header了,默认为set_default_headers里面的
以后规范都在set_default_headers里面进行设置header
注意:
在http处理方法中(这里暂为get方法)使用set_header设置的子弹会覆盖set_default_headers里的默认设置字段
##设置状态码
self.set_status(status_code,reason=None)
作用:为响应设置状态码
self.set_status(404,"bad boy")
参数:status_code (状态码的值,int类型)
如果reason=None,则状态码必须为正常值,列如999
reason (描述状态码的词组,sting字符串类型)
##重定向
self.redirect()
重定向跳转到其他页面,比如self.redirect("/write")跳转到http://127.0.0.1:9000/wtite
##抛出HTTP错误状态码,默认为500, tornado会调用write_error()方法并处理
self.send_error(status_code=500,**kwargs)
抛出错误
##接收错误,并处理。所以说上面这两个必须连用。
self.write_error(status_code,**kwargs)
接收返回来的错误并处理错误
import tornado.web
from tornado.web import RequestHandler
import json
#------------------------------------------------
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
self.write("good boy") #响应http的请求
#-------------------------------
class WriteHandler(tornado.web.RequestHandler):
def get(self,*args,**kwargs):
self.write("good boy1")
self.write("good boy2")
self.write("good boy3")
self.finish() #刷新缓存区,并关闭请求通道,导致后面的good boy4无法传输
self.write("good boy4")
#---------------------------------------------------
class Json1Handler(RequestHandler):
def get(self, *args, **kwargs):
per = {
"name":"小白",
"gae":"22",
"height":170,
"weight":60,
}
jsonStr = json.dumps(per) #导入json库,将字典转化为json字符串
self.set_header("Content-Type", "applictions/json;charset=UTF-8")
self.write(jsonStr)
#----------------------------------------------------------------------
class Json2Handler(RequestHandler):
def get(self, *args, **kwargs):
per = {
"name":"小白",
"gae":"22",
"height":170,
"weight":60,
}
self.write(per)
#----------------------------------------------------------#------------
#预先设置报文头
class Headerhandler(RequestHandler):
def set_default_headers(self):
self.set_header("Content-Type", "applictions/json;charset=UTF-8") #预先设置报文头
def post(self, *args, **kwargs): #下面的就不必再次书写了
pass
def get(self, *args, **kwargs):
pass
#------------------------------------------------------
#设置状态码
class StatusHandler(RequestHandler):
def get(self, *args, **kwargs):
self.set_status(404,reason="Dont find!")
self.write("*****") #返回Status Code:404 Dont find!
#------------------------------------------------
#重定向
class RedirectHandler(RequestHandler):
def get(self,*args,**kwargs):
self.redirect("/write") #self.redirect重定向
#------------------------------------------------------
#自定义错误页面
访问http://127.0.0.1:9000/error?flag=0 进行测试
class ErrorHandler(RequestHandler):
def write_error(self, status_code, **kwargs):
if status_code==500:
code = 500
#返回500界面
self.write("服务器内部错误")
elif status_code==400:
code = 400
#返回404界面
self.write("预先设置错误")
self.set_status(code)
def get(self, *args, **kwargs):
flag = self.get_query_argument("flag")# 获取单个键值
#self.get_query_argument('a') # 如果同时传递多个a的参数,那么会采用后面覆盖前面的原则
if flag == "0":
self.send_error(500)
#注意在self.send_error(500)以下同级的内容不会继续执行,
self.write("right")
#-------------------------------------
#反向解析
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
# self.write("good boy") #响应http的请求
url = self.reverse_url("boy") #找到别名为boy的url
self.write("<a href='%s'>跳转到另一个页面</a>"%(url)) #点击a标签跳转到页面/boy
class BoyHandler(RequestHandler):
def initialize(self,word3,word4): #该方法会在http方法(这里为get方法)之前调用
self.word3=word3
self.word4= word4
def get(self, *args, **kwargs):
print(self.word3,self.word4)
self.write("good boy")
11. tornado.web.RequestHandler传参
11.1 利用HTTP协议向服务器传递参数
- 提取URI的特定部分
- get方式传递参数
- post方式传递参数
- 既可以获取get请求,也可以获取post请求
- 在http报文中增加自定义的字段
1提取URI的特定部分
(r"/movies/(\w+)/(\w+)/(\w+)",index.MoviesHandler) # \w匹配包括下划线的任何单词字符 +只有一个 *零到多个
(r"/movies1/(?P\w+)/(?P\w+)/(?P\w+)",index.movies1Handler)
class MoviesHandler(RequestHandler):
def get(self, h1,h2,h3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
#application中
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
#(省略部分url)
(r"/movies/(\w+)/(\w+)/(\w+)",index.MoviesHandler)
#//127.0.0.1:9000/movies/good/boy/job
# \w匹配包括下划线的任何单词字符 +只有一个 *零到多个
(r"/movies1/(?P<p1>\w+)/(?P<p2>\w+)/(?P<p3>\w+)",index.movies1Handler)
#//127.0.0.1:9000/movies/good/boy/job
]
#views/index中
from tornado.web import RequestHandler
class MoviesHandler(RequestHandler):
def get(self, h1,h2,h3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
print(h1 + "-"+h2+"_"+h3)
self.write("move go !")
#----------------------------------
class movies1Handler(RequestHandler):
def get(self, p1,p2,p3,*args, **kwargs): #要接收几个就加几个在,而用字典{}传参的用initializ
print(p1 + "-"+p2+"_"+p3)
self.write("move go to !")
访问http://127.0.0.1:9000/movies/good/boy/job
#(浏览器输出):move go!
#(pycharm输出):good-boy_job
#--------------------------------------------------
访问http://127.0.0.1:9000/movies1/good/boy/job 、
#(浏览器输出):move go to !
#(pycharm输出):good-boy_job
2get方式传递参数
路由比如(r"/movies2",index.Movies2Handler)
self.get_query_argument(name,default=ARG_DEFAULT(参数默认值),strip=True)#原型,这样去拿到参数a,b,c的值
self.get_query_arguments(name,strip=True)有重复的参数,参数原型
#127.0.0.1:8000/movies2?a=1&b=2&c=3第一种情况
#127.0.0.1:8000/movies2?a=1%20%20&b=2%20%20%20&c=3第二种情况
#127.0.0.1:8000/movies2?a=1&a=2&c=3第三种情况
#views/index中比如接收参数
class Movies2Handler(RequestHandler): #127.0.0.1:8000/movies2?a=1&b=2&c=3
def get(self, *args, **kwargs):
self.get_query_argument(name,default=ARG_DEFAULT(参数默认值),strip=True)#原型,这样去拿到参数a,b,c的值
#self.get_query_arguments(name, strip=True)有重复的参数,参数原型
参数:
name:
从get请求参数字符传中返回指定参数的值,如果出现多个同名参数,则返回最后一个的值
default:
设置未传的参数时),返回默认的值 ,比如这里传过来一个a(存在127.0.0.1:8000/movies2?a=1&b=2&c=3)没有任何赋值,而default=100,则默认a=100。
如果传过来没有的值,default也没有设置,比如d没有这样的值,会跑出一个错误:tornado.web.MissingArgumentError异常 即缺少参数
strip:
表示是否过滤掉左右两边的空白字符,默认为True,即127.0.0.1:8000/movies2?a= 1&b= 2 &c=3 值得前后出现空格,自动的过滤掉空格,即为127.0.0.1:8000/movies2?a=1&b=2&c=3
#application中
class Application(tornado.web.Application): #tornado.web.Application的子类
def __init__(self):
handlers=[
#(省略部分url)
(r"/movies2",index.Movies2Handler)
]
#ciews/index中
class Movies2Handler(RequestHandler):
def get(self, *args, **kwargs):
# self.get_query_argument(name,default=ARG_DEFAULT(参数默认值),strip=True)#原型,这样去拿到参数a,b,c的值
a = self.get_query_argument("a") #获取参数
b = self.get_query_argument("b")
c = self.get_query_argument("c")
print(a,b,c) #pycharm中打印一下
self.write("movies2Handler") #浏览器中打印
访问http://127.0.0.1:9000/movies2?a=1&b=2&c=3
#(浏览器输出):movies2Handler
#(pycharm输出):1 2 3
#如果有空格http://127.0.0.1:8000/movies2?a=1%20%20&b=2%20%20%20&c=3
a = self.get_query_argument("a",strip=False) #相应的修改
b = self.get_query_argument("b",strip=False)
c = self.get_query_argument("c",strip=False)
#(浏览器输出):movies2Handler
#(pycharm输出):1 2 3 #就会打印出空格来,百度的搜索中,搜索英语句子空格就有作用
#如果http://127.0.0.1:9000/movies2?a=1&a=2&c=3
#(浏览器输出):movies2Handler
#(pycharm输出):2 3 #就会打印出后面一个a的值
#如果http://127.0.0.1:9000/movies2?a=1&a=2&c=3,但是我们也要获取两个相同的a的值
alist = self.get_query_arguments("a",) #这样进行接收,但是接收回来时一个列表
c = self.get_query_argument("c",)
print(alist[0],alist[1],c)
self.write("movies2Handler")
#(浏览器输出):movies2Handler
#(pycharm输出):1 2 3
3. post方式传递参数
self.get_body_argument(name, default=ARG_DEFAULT(参数默认值), strip = True)
self.get_body_arguments(name, strip = True)
参数:
name:
从get请求参数字符传中返回指定参数的值,如果出现多个同名参数,则返回最后一个的值
default:
设置未传的参数时),返回默认的值 ,比如这里传过来一个a(存在127.0.0.1:8000/movies2?a=1&b=2&c=3)没有任何赋值,而default=100,则默认a=100。
如果传过来没有的值,default也没有设置,比如d没有这样的值,会跑出一个错误:tornado.web.MissingArgumentError异常 即缺少参数
strip:
表示是否过滤掉左右两边的空白字符,默认为True,即127.0.0.1:8000/movies2?a= 1&b= 2 &c=3 值得前后出现空格,自动的过滤掉空格,即为127.0.0.1:8000/movies2?a=1&b=2&c=3
#templates/postfile中,简单的一个注册页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<form action="/postfile" method="post">
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login">登录<br/>
</form>
</div>
</body>
</html>
#config中配置
import os
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"),
"template_path":os.path.join(BASE_DIRS,"templates"), #这里配置html模板
"debug":True #修改完文件后服务自动启动
}
#application中配置路由
(r"/postfile",index.PostfileHandler),
#views/index中
class PostfileHandler(RequestHandler): #post请求处理
def get(self, *args, **kwargs):
self.render("postfile.html") #注册页面跳转
def post(self, *args, **kwargs): #接收post请求
name= self.get_body_argument("username") #接收post请求的参数
passwd=self.get_body_argument("passwd")
hobbylist=self.get_body_arguments("hobby")
print(name,passwd,hobbylist[0:]) #将多选框的内容打印出来
self.write(name)
#注册登录页面提交后
#(浏览器输出)postfile
#(pycharm输出)postfile 123456 ['权利', '金钱', '书籍']
#post原型接收参数:self.get_body_argument(name, default=ARG_DEFAULT(参数默认值), strip = True)
# self.get_body_arguments(name, strip = True) #一样的有多个重复的值时
4. 既可以获取get请求,也可以获取post请求
#self.get_body_argument(name, default=ARG_DEFAULT(参数默认值), strip = True)
#self.get_arguments(name, strip=True)有重复的参数,参数原型
#直接替换之前的get请求的原型或者post的原型,虽然post和get都能用,但是不容易区分,所以一般不用。
12 request对象
- request对象作用:
储存了关于请求的相关信息 - 属性:
method:HTTP请求的方式
host:被请求的主机名
uri:请求的完整资源地址,包括路径和get查询参数部分
path:请求的路径部分
query:请求参数部分
version:使用的HTTP版本
headers:请求的协议头,字典类型
body:请求体数据
remote_ip:客户端的ip
files:用户上传的文件,字典类型
#views/index
class RequestHandler(RequestHandler):
def get(self,*args,**kwargs):
print(self.request.method) #将属性都打印出来
print(self.request.host)
print(self.request.uri)
print(self.request.query)
print(self.request.version)
print(self.request.headers)
print(self.request.body)
print(self.request.remote_ip)
print(self.request.files)
application中配置url
(r"/request",index.RequestHandler)
浏览器访问http://127.0.0.1:8000/request
#(pycharm输出)
GET #HTTP请求的方式
127.0.0.1:8000 #host
/request?a=1&b=1 #uri
/request #path
a=1&b=1 #query
HTTP/1.1 #version .http1.1特点长链接
Host: 127.0.0.1:8000 #headers
Connection: keep-alive
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
b'' #body
127.0.0.1 #remote_ip
{} #files
13. tornado.httputil.HTTPFile对象
- tornado.httputil.HTTPFile对象作用:
它是接收到的文件的对象 - 属性
filename:文件的实际名字
body: 文件的数据实体
content_type:文件的类型
在templates中新建upload.py
#templates/upload.html中简单的上传页面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件</title>
</head>
<body>
<form action="/upfiles" method="post" enctype="multipart/form-data">
<input type="file" name="file"/>
<input type="file" name="file"/>
<input type="file" name="img"/>
<input type="submit" value="上传">
</form>
</body>
</html>
#tornado.httputil.HTTPFile对象
class UpfileHandler(RequestHandler): #上传文件
def get(self, *args, **kwargs):
self.render("upfiles.html") #访问页面upfiles.html
def post(self, *args, **kwargs):
files = self.request.files #从request这种拿到files
print(files)
self.write("上传成功")
新建text文本,写上who are you ,上传后
#(浏览器输出)上传成功
#(pychar输出){'file': [{'filename': '新建文本文档.txt', 'body': b'who are you!', 'content_type': 'text/plain'}]}
#上传两个相同类型的文件
#(pychar输出){'file': [{'filename': '新建文本文档.txt', 'body': b'who are you!', 'content_type': 'text/plain'},{'filename': '新建文本文档2.txt', 'body': b'who are you!', 'content_type': 'text/plain'}]}
#"file"就是<input type="file" name="file"/> 中的name
#"filename"就是上传的文件的名字
#“body”就是文件的内容
#而相对于<input type="file" name="img"/>,上传为文件时
#"filename"就是上传的图片的名字
#"body"内容就会变成字节码b"......"
#“content_type”就是图片的类型
{"img":[{'filename': 'tupian.png', 'body': b'.......................', 'content_type': 'image/png'}]}
#如果上传多个不同类型的文件,request拿到files结构:
{
'file': [
{
'filename': '新建文本文档.txt', 'body': b'who are you!', 'content_type': 'text/plain'
},
{
'filename': '新建文本文档2.txt', 'body': b'who are you!', 'content_type': 'text/plain'
}
],
"img":[
{
'filename': 'tupian.png', 'body': b'.......................', 'content_type': 'image/png'
}
]
}
完整版上传:
import os
import upfile
import config
class UpfileHandler(RequestHandler): #上传文件
"""
self.request.files结构:
{'file': [{'filename': '新建文本文档.txt', 'body': b'who are you!', 'content_type': 'text/plain'},{'filename': '新建文本文档2.txt', 'body': b'who are you!', 'content_type': 'text/plain'}],"img":[{'filename': 'tupian.png', 'body': b'.......................', 'content_type': 'image/png'}]}
"""
def get(self, *args, **kwargs):
self.render("upload.html")
def post(self, *args, **kwargs):
filesDict = self.request.files
for inputname in filesDict:
fileArr = filesDict[inputname] #拿到对应key的value
for filesObj in fileArr: #又拿到key
#存储路径
filePath=os.path.join(config.BASE_DIRS,"upfile/"+filesObj.filename)
#filesObj.filename新建file。字典取到上传文件的名字,并新建
with open(filePath,"wb") as f: #打开新建的文件 ( w+用在纯文本上,wb+可以用在Exe文件)
f.write(filesObj.body) #一样的字典形式拿到value,写入 文本的body字段的内容,即value
self.write("上传成功")
#成功后,就会在upfile文件下出现对应的文件
14.响应输出
- write
原型:self.write(chunk) # chunk是响应浏览器的数据
作用:
1. 将chunk数据写到输出缓冲区。
-----------缓冲区刷新:1.程序结束;2.手动刷新;3缓冲区满;4.遇到\n
2.利用write方法写json数据
##刷新缓冲区
self.finish
刷新缓冲区,并关闭当前请求通道,即后面的数据不在传输
##缓冲区的内容输出到浏览器不用等待请求处理完成
self. flush()
self.write()会先把内容放在缓冲区,正常情况下,当请求处理完成的时候会自动把缓冲区的内容输出到浏览器,但是可以调用 self.flush()方法,这样可以直接把缓冲区的内容输出到浏览器,不用等待请求处理完成.
class WriteHandler(RequestHandler): #相应的在application中配上url即可实验
def get(self, *args, **kwargs):
self.write("where are you")
self.write("who are you")
self.finish() #刷新缓冲区,关闭当次请求
self.write("how old are you") #这里就不会打印了,因为已经关闭了通道
#配置application中的url
(r"/write", index.WriteHandler), #响应输出
(r"/json1", index.Json1Handler), # 测试json1
(r"/json2", index.Json2Handler), # 测试json2
##序列化
json,jsonStr = json.dumps()
需要导入json库,对应的Handler中编写字典, jsonStr = json.dumps(per) 将字典转化为json的字符串
#(浏览器输出){"name": "nick", "age": 18, "height:": 170, "weight": 70}
但是你会发现,其实我们不需要这样写,直接用write也能转化。json还要进行下文的设置响应头
但是前者json转化的在谷歌浏览器F12中Network中json1文本中的Respose Headers里面,
Content Type 为 text/heml,而后者write转换后为appliction/json。
text/heml浏览器会将这个当成页面进行渲染,所以应为json类型
###在线解析json数据结构 ,https://c.runoob.com/front-end/53
#views/index中
class Json1Handler(RequestHandler): #手动json转化测试,需要导入json库
def get(self, *args, **kwargs):
per1 = {
"name":"nick",
"age":18,
"height:":170,
"weight":70,
}
jsonStr = json.dumps(per1) #将字典转化为json的字符串
self.set_header("Content-Type","applictions/json;charset=UTF-8")
self.set_header("good","boy") #响应头自定义修改
self.write(jsonStr) #(输出){"name": "nick", "age": 18, "height:": 170, "weight": 70}
class Json2Handler(RequestHandler): # 自动转化字典
def get(self, *args, **kwargs):
per2 = {
"name2": "nick",
"age2": 18,
"height2:": 170,
"weight2": 70,
}
self.write(per2)
##设置响应头
self.set_header(name,value)
self.set_header("Content-Type","applictions/json;charset=UTF-8")
self.set_header("good","boy") #自定义设置
作用:手动设置一个名为name值为value的响应头字段(Respose Headers)
参数:name:字段名称
value:字段值
###text/html和text/plain的区别
1、text/html的意思是将文件的content-type设置为text/html的形式,浏览器在获取到这种文件时会自动调用html的解析器对文件进行相应的处理。
2、text/plain的意思是将文件设置为纯文本的形式,浏览器在获取到这种文件时并不会对其进行处理
##默认的headers
set_default_headers()
作用:
def set_default_headers(self):
在进入http响应方法之前被调用,可以重写该方法来预先设置默认的headers
这样类下面的各种方法都不用再去设置header了,默认为set_default_headers里面的
以后规范都在set_default_headers里面进行设置header
注意:
在http处理方法中(这里暂为get方法)使用set_header设置的子弹会覆盖set_default_headers里的默认设置字段
#预先设置报文头
class Headerhandler(RequestHandler):
def set_default_headers(self):
self.set_header("Content-Type", "applictions/json;charset=UTF-8") #预先设置报文头
def post(self, *args, **kwargs): #下面的就不必再次书写了
pass
def get(self, *args, **kwargs):
pass
##设置状态码
self.set_status(status_code,reason=None)
作用:为响应设置状态码
self.set_status(404,"bad boy")
参数:status_code (状态码的值,int类型)
如果reason=None,则状态码必须为正常值,列如999
reason (描述状态码的词组,sting字符串类型)
#设置状态码
class StatusHandler(RequestHandler):
def get(self, *args, **kwargs):
self.set_status(404,reason="Dont find!")
self.write("*****") #返回Status Code:404 Dont find!
##重定向
self.redirect()
重定向跳转到其他页面,比如self.redirect("/write")跳转到http://127.0.0.1:9000/wtite
#重定向
class RedirectHandler(RequestHandler):
def get(self,*args,**kwargs):
self.redirect("/write") #self.redirect重定向
##抛出HTTP错误状态码,默认为500, tornado会调用write_error()方法并处理
self.send_error(status_code=500,**kwargs)
抛出错误
##接收错误,并处理。所以说上面这两个必须连用。
self.write_error(status_code,**kwargs)
接收返回来的错误并处理错误
#自定义错误页面
访问http://127.0.0.1:9000/error?flag=0 进行测试
class ErrorHandler(RequestHandler):
def write_error(self, status_code, **kwargs):
if status_code==500:
code = 500
#返回500界面
self.write("服务器内部错误")
elif status_code==400:
code = 400
#返回404界面
self.write("预先设置错误")
self.set_status(code)
def get(self, *args, **kwargs):
flag = self.get_query_argument("flag")# 获取单个键值
#self.get_query_argument('a') # 如果同时传递多个a的参数,那么会采用后面覆盖前面的原则
if flag == "0":
self.send_error(500)
#注意在self.send_error(500)以下同级的内容不会继续执行,
self.write("right")
#反向解析
class IndexHandler(RequestHandler):
def get(self,*args,**kwargs): #处理get请求的,并不能处理post请求
# self.write("good boy") #响应http的请求
url = self.reverse_url("boy") #找到别名为boy的url
self.write("<a href='%s'>跳转到另一个页面</a>"%(url)) #点击a标签跳转到页面/boy
15.接口调用顺序
方法:
1.def initialize(),
作用:初始化
2.def preare()方法
作用:预处理方法,在执行对应的请求方法之前调用
注意:任何一种http请求都会执行prepare方法
所以可以在这里进行反爬虫,验证用户是否符合条件。
3.HTTP方法
get:在传参的时候会将参数拼接到UTL的后面;速度快,效率高,不安全,传输数据量小
post:在传参时则是单独打包并发送;传输慢,效率低,传输数据量大,安全;(一般修改服务器的数据时就用post,其他时候就用get)
head :类似get请求,只是相应中没有具体的内容,用户获取报文头
delete:请求服务器到删除指定的资源
put :从客户端向服务器传送指定内容
patch:请求修改局部内容
options:返回URL支持的所有HTTP方法
4.def set_default_headers()
作用:设置响应头
5.def write_error()
作用:出现异常就提醒(如邮件提醒)机制并跳转到错误页面
6.def on_finish()
作用:在请求处理结束后执行,在该方法中进行一个资源的清理释放(各种方法调用中开启的空间释放–内存),或者是日志处理(当请求完成后的访问信息记录)
注意:尽量不要在该方法中进行响应输出
比如进行get请求完成后调用on_finish(),进行资源的清理释放
class IndexHandler(RequestHandler):
def get(self, *args, **kwargs):
pass
def post(self, *args, **kwargs):
pass
def on_finish(self):
pass
顺序:
- 在正常情况未抛出错误时的顺序:
set_default
initialize
prepare
get/post
on_finish
测试如下:
views/index中
class TextHandler(RequestHandler):
def initialize(self):
print("initialize")
def prepare(self):
print("prepare")
def get(self,*args,**kwargs): #或者post
print("get")
def set_default_headers(self):
print("set_default_hearders")
def write_error(self,status_code,**kwargs):
print("write_error")
def on_finish(self):
print("on_finish")
#application中配置路由
(r"/test",index.TextHandler) , #测试接口调用顺序
#浏览拿起访问后
#(pycharm输出):
set_default_hearders
initialize
prepare
get
on_finish
- 在抛出错误的情况下的顺序
set_default_headers
initialize
prepare
get
set_default_headers
write_error
on_finish
测试如下:
views/index中
class TextHandler(RequestHandler):
def initialize(self):
print("initialize")
def prepare(self):
print("prepare")
def get(self,*args,**kwargs):
print("get")
self.send_error(500)
self.write("抛出错误500")
def set_default_headers(self):
print("set_default_headers")
def write_error(self,status_code,**kwargs):
print("write_error")
self.write("500服务器错误")
def on_finish(self):
print("on_finish")
浏览器访问后
#(pycharm输出):
set_default_headers
initialize
prepare
get
set_default_headers #抛出出错误后要修改报文头,所有又执行了一次
write_error
on_finish
ERROR:tornado.access:500 GET /test (127.0.0.1) 0.00ms
ERROR:tornado.application:Uncaught exception GET /test (127.0.0.1)
HTTPServerRequest(protocol='http', host='127.0.0.1:9999', method='GET', uri='/test', version='HTTP/1.1', remote_ip='127.0.0.1')
。。。。。。。.。。。。。。。。。
16.模板
- 配置模板的路径
"template_path":os.path.join(BASE_DIRS,"templates"),
- 渲染并返回给客户端
返回页面给客户端
使用render()方法
class HomeHandler(RequestHandler):
def get(self,*args,**kwargs):
self.render("postfile.html")
- 变量和表达式
语法:{{var}} 放变量
{{expression}} 放表达式
class HomeHandler(RequestHandler): #渲染
def get(self,*args,**kwargs):
temp = 100
per={
"name":"good",
"age":10
}
self.render('upload.html',num=temp,per=per) #对应用{{per["name"]}}取值,这里不能用点语法per.name
# self.render('upload.html', num=temp, **per) #也可以这样传递,只是在页面中就{{name}},形式取值。
# 但是为了避免和变量名冲突,一般不用,比如说变量名也为age=20,和字典中的age=10冲突,页面中{{age}}也就发生冲突
upload.html页面如下
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>上传文件</title>
</head>
<body>
<span>{{num}}</span>#传值<br/>
<span>num+10:{{num+10}}</span>#运算<br/>
<span>num*10:{{num*10}}</span> #运算<br/>
<span>num==100:{{num==100}}</span>#判断<br/>
<span>num==1000:{{num==1000}}</span>#判断<br/>
<span>{{per["name"]}}</span>#字典<br/>
<span>{{per["age"]}}</span>#字典<br/>
</body>
</html>
#对应输出
100#传值
num + 10:110#运算
num * 10:1000#运算
num == 100:True#判断
num == 1000:False#判断
good#字典
10#字典
17.流程控制
1. if
2. for
3. while
1. if用法
满足if-else-end ; if-elif-elif-else-end语句
和django基本类似,少数不一样
格式:
#html页面中应用:
{% if 表达式 %}
语句1
{% elif 表达式 %}
语句2
{% elif 表达式 %}
语句3
......
{% else %}
语句n
{% end %}
2.for用法
格式:
{% for 变量 in 集合 %}
语句
{% end %}
class HomeHandler(RequestHandler): #渲染
def get(self,*args,**kwargs):
stus = [
{
"name":"laowang",
"age":18
},
{
"name":"xiaobai",
"age":20
}
]
self.render('upload.html',stus=stus)
#templates/upload.html中应用,其他的html此处省略
<ul>
{% for stu in stus %}
<li>{{stu["name"]}} : {{stu["age"]}}</li>
{% end %}
</ul>
#(浏览器输出)
laowang : 18
xiaobai : 20
18.函数
1. static_url()
2. 自定义函数
1. static_url()
作用:获取配置的静态目录,并肩参数拼接到金泰目录后面并返回新的路径
用于:引入文件css,js等
优点:修改目录不需要再修改html中的配置文件路径,只需要修改config配置文件中的即可。
--------而且创建了一个基于文件内容的hash值,并将其添加到URl末尾,这个hash值总能保证加载的都是最新的文件,而不是缓存的版本。不论是开发还是上线阶段都是很有必要的。
#stmplates/postfile中
<link rel="stylesheet" href="{{static_url('css/postfile.css')}
新建文件 如图:存放对应文件
#需要配置好静态文件的路径"static_path"
setting = {
"static_path":os.path.join(BASE_DIRS,"static"),
"template_path":os.path.join(BASE_DIRS,"templates"),
"debug":True #修改完文件后服务自动启动
}
#static/css/posfile.css中
div{
width: 700px;
height: 100px;
background-color: aqua;
font-size: 20px;
}
引入文件成功:

2. 自定义函数
作用:自定义函数后,可以再html页面模板中应用 ;{{mySum(100,89)}}形式应用
tornado在末班中可以引用函数并且能进行传参
#views/index中配置后,对应添加路由
class FunctionHandler(RequestHandler): #自定义函数
def get(self,*args,**kwargs):
def mySum(n1,n2):
return n1 + n2
self.render("upload.html",mySum=mySum) #传递函数
#路由添加
(r"/function",index.FunctionHandler),
#对应的template/upload.html中
<p>{{mySum(100,89)}}</p>
#(浏览器输出)
189
19.转义
1.tornado默认开启了自动转义功能,能防止网站受到恶意攻击
#views/index中配置,
class TransferredHandler(RequestHandler):
def get(self,*args,**kwargs):
strm="<h1>good job!</h1>"
self.render("transferred.html",strm=strm)
相应的
application中配置路由:
(r"/transferred",index.TransferredHandler) #转义
对应的transferred.html中接收:
<body>
{{strm}}
</body>
浏览器输出:并不是一个h1标签,而是个字符串:
<h1>good job!</h1>
2.关闭自动转义
- 方法一 :关闭一行
raw :{% raw strm %}
<body>
{{strm}}
{% raw strm %}
{{strm}}
</body>

这样的话上面实例:
good job!
就会变成h1标签,但是只能关闭一行2. 方法二:关闭当前文档中的自动转移
{% autoescape None %}
<body>
{{strm}}
{% autoescape None %}
{{strm}}
</body>
浏览器输出:

- 在配置文件中修改
“autoescape”:None, #关闭项目的自动转移
setting = {
"static_path":os.path.join(BASE_DIRS,"static"),
"template_path":os.path.join(BASE_DIRS,"templates"),
"debug":True , #修改完文件后服务自动启动
"autoescape":None, #关闭自动转移
}
<body>
{{strm}}
{{strm}}
</body>

- escape()
{{escape(strm)}}
作用:在关闭自动转义后,可以用这个方法开启特定的内容的自动转义
<body>
{{strm}}
{% autoescape None %}
{{strm}}
{{escape(strm)}}
</body>

20.继承
子模板继承父模板的内容,即实例cart.html继承与父模板base.html 模板
#父模板挖坑,等着子模板来填坑
{% block main %}
{% end %}
#子模板,填坑的
{% extends "base.html" %}
{% block main %}
<h1>页面展示</h1>
{% end %}
templates/base.html父模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{% block main %}
{% end %}
</body>
</html>
templates/cart.html中子模板,继承父模板
{% extends "base.html" %}
{% block main %}
<h1>页面展示</h1>
{% end %}
views/index中
class CartHandler(RequestHandler): #继承测试
def get(self,*args,**kwargs):
self.render("cart.html",title="cart")
application中配置路由:
(r"/cart",index.CartHandler), #继承
访问路由后,浏览器:

21.静态文件
1. static_path
2. StaticFileHandler
1. static_path
**作用:**告诉tornado从文件系统中的莫一个特定的位置提供静态文件
示列: “static_path”:os.path.join(BASE_DIRS,“static”), #静态文件
#config中配置
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转移
}
#static/html/index.html中
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>主页</title>
</head>
<body>
<p>静态页面 </p>
</body>
</html>
请求方式
直接访问静态文件,不需要配置路由:
http://127.0.0.1:9999/static/html/index.html

引入其他文件
css文件
<link rel="stylesheet" href="{{static_url('css/postfile.css')}}">
js文件
<script type="text/javascript" charset="utf-8" src="{{static_url('js/test1.js')}}"></script>
2. StaticFileHandler
使用原因:http://127.0.0.1:9999/static/html/index.html过于的繁琐,
本质:是tornado预制的,用来提供静态资源文件的一个Handler
作用:可以通过 tornado.web.StaticFileHandler 来映射静态文件
参数:
path:同来指定提供静态文件的根路径
default_filename:同来指定访问路由中未指定的文件,
使用:
application中配置路由
import config #为了使用config中的BASE_DIRS
import os #拼接路径
(r"/(.*)$",tornado.web.StaticFileHandler{"path":os.path.join(config.BASE_DIRS,"static/html"),"default_filename":"index.html"}),
#StaticFileHandler应用静态文件,注意要放在所有路由的下面。
- StaticFileHandler应用静态文件,注意要放在所有路由的下面。
- 参数 “path”:os.path.join(config.BASE_DIRS,“static/html”)传参,拼接以下静态文件的路径, 这样所有在html文件下的静态文件都可以简单的访问了
- 参数"default_filename":“index.html” 这里是设置了一个默认值,即http://127.0.0.1:8888情况下访问index.html页面(主页)。有点像 (r"/",index.IndexHandler),这样的路由。
*这样,直接访问http://127.0.0.1:9999/index.html即可,设置默认值后http://127.0.0.1:9999就能直接访问默认值页面
**注意:**在设置默认值后, (r"/",index.IndexHandler),这样的路由要注释掉,不然他不会访问我们设置的默认值,出现冲突
tornado与数据库mysql交互
概述:tornado 没有自带的ORM,对于数据库需要自己去适配,并且目前python3.6 +tornado还没有比较完善的驱动,PyMySQL支持python3.x,而MySQLdb不支持python3.x
22.建立连接
-
用Navicat连接数据库后,简单的创建一个表,
注意:设置主键为id,和自动递增

注意:新建连接时可能出现:
1130-host … is not allowed to connect to this MySql server错误
解决:https://blog.csdn.net/weixin_43097301/article/details/85892582
1251 Client does not support authenticasider upgrading Mysotocol requested by ser错误
解决:https://blog.csdn.net/weixin_43097301/article/details/85892142 -
在config中配置数据库
相应的修改为自己的信息
#数据库配置
mysql ={
"host":"192.168.1.1",
"user":"root",
"passwd":"mima",
"dbname":"tornado_mysql"
}
- 新建zjMuSQL.py在根目录,即和config同级
import pymysql #导入pymysql,因为PyMySQL支持python3.x,而MySQLdb不支持python3.x
class zjMySQL():
def __init__(self,host,user,passwd,dbName):
self.host = host #登录主机
self.user = user #用户
self.passwd = passwd #密码
self.dbName = dbName #数据库的名,新建的数据库名
def connet(self): #用于连接数据库
self.db=pymysql.connect(self.host,self.user,self.passwd,self.dbName)
self.cursor=self.db.cursor()
def close(self): #用于断开连接
self.cursor.close()
self.db.close()
def get_one(self,sql): #查询一条数据;类型为元组
res=None #sql参数为查询mysql语句
try:
self.connet()
self.cursor.execute(sql) #执行查询
res=self.cursor.fetchone() #获取数据
self.close() #关闭
except:
print("查询失败")
return res
def get_all(self,sql): #获取所有;类型为元组
res = () #sql参数为查询mysql语句
try:
self.connet() #连接数据库
self.cursor.execute(sql) #执行查询语句
res=self.cursor.fetchall() #接收全部的返回结果行
self.close()
except:
print("查询失败")
return res
def get_all_obj(self,sql,tableName,*args): #获取所有;类型为列表
resList = [] #sql:sql查询语句
fieldsList=[]
if(len(args)>0):
for item in args: #遍历字典key
fieldsList.append(item) #添加kry
else:
fieldsSql="select COLUMN_NAME from information_schema.COLUMNS where table_name ='%s'and table_schema = '%s'"%(tableName,self.dbName)
#column name列名 information sheet: 信息表
fields=self.get_all(fieldsSql) #执行语句,获取所有表信息(("id,"),("name",),("age,"))
for item in fields: #遍历key
fieldsList.append(item[0]) #添加
res=self.get_all(sql) #获取传参的查询语句的数据,元组类型tuple
for item in res:
items= item
obj = {}
count = 0
for x in item:
obj[fieldsList[count]]=x
count += 1
resList.append(obj)
return resList
def insert(self,sql): #插入
return self.__edit(sql)
def update(self,sql): #修改
return self.__edit(sql)
def delete(self,sql): #删除
return self.__edit(sql)
def __edit(self,sql):
count = 0
try:
self.connet()
count = self.cursor.execute(sql)
self.db.commit()
self.close()
except:
print("事务提交失败")
self.db.rollback()
return count
- 在application中最后配置url
省略了路由的handlers=[ ]中的部分代码
注意,路由要放在静态路由((r"/(.*)$",tornado.web.StaticFileHandler,{“path”:os.path.join(config.BASE_DIRS,“static/html”),“default_filename”:“index.html”}),)之前,不然访问路由会报错
from zjMysql import zjMySQL
handlers=[
r"/students",index.StudentsHandler),
]
self.db = zjMySQL(config.mysql["host"],config.mysql["user"],config.mysql["passwd"],config.mysql["dbname"]) #实例化一个ziMySQL的对象db设置连接,访问数据库,方便调用
- 获取数据
stus=self.application.db.get_all_obj("select * from students","students")
views/index中
class StudentsHandler(RequestHandler): #数据库中获取信息,并展示
def get(self, *args, **kwargs):
# stus = self.application.db.get_all_obj("select name,age from students", "students", "name", "age") #查询指定字段
stus=self.application.db.get_all_obj("select * from students","students") #查询获取数据
print(stus)
self.write("ok")
# self.render("students.html",stus=stus)
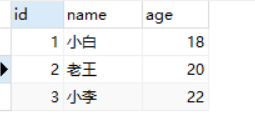
#(pycharm输出):
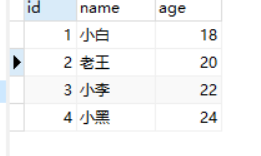
[{'id': 1, 'name': '小白', 'age': 18}, {'id': 2, 'name': '老王', 'age': 20}]
#表明拿到了数据库的数据

- 插入数据
self.application.db.insert("insert into students (name,age) values('小陈',22);")
views/index中
class StudentsHandler(RequestHandler): #数据库中获取信息,并展示
def get(self, *args, **kwargs):
self.application.db.insert("insert into students (name,age) values('小李',22);") #插入语句
self.write("ok")
23. 简单的封装一下ORM
- 如图新建ORM文件夹
- 文件zjMySQL进行了修改
import pymysql #导入pymysql,因为PyMySQL支持python3.x,而MySQLdb不支持python3.x
import config
def singleton(cls,*args,**kwargs): #单列类,没有做线程安全,多线程的时候,对象可能创建多个,所以为不安全,应该加线程锁
instances={}
def _singleton():
if cls not in instances:
instances[cls]=cls(*args,**kwargs)
return instances[cls]
return _singleton
@singleton #装饰为单列类,在程序运行期间,zjMySQL创建的对象永远只有一个
class zjMySQL():
host = config.mysql["host"] #登录主机 直接定义为属性
user = config.mysql["user"] #用户
passwd = config.mysql["passwd"] #密码
dbName = config.mysql["dbname"] #数据库的名,新建的数据库名
def connet(self): #用于连接数据库
self.db=pymysql.connect(self.host,self.user,self.passwd,self.dbName)
self.cursor=self.db.cursor()
def close(self): #用于断开连接
self.cursor.close()
self.db.close()
def get_one(self,sql): #查询一条数据;类型为元组
res=None #sql参数为查询mysql语句
try:
self.connet()
self.cursor.execute(sql) #执行查询
res=self.cursor.fetchone() #获取数据
self.close() #关闭
except:
print("查询失败")
return res
def get_all(self,sql): #获取所有;类型为元组
res = () #sql参数为查询mysql语句
try:
self.connet() #连接数据库
self.cursor.execute(sql) #执行查询语句
res=self.cursor.fetchall() #接收全部的返回结果行
self.close()
except:
print("查询失败")
return res
def get_all_obj(self,sql,tableName,*args): #获取所有;类型为列表
resList = [] #sql:sql查询语句
fieldsList=[]
if(len(args)>0):
for item in args: #遍历字典key
fieldsList.append(item) #添加kry
else:
fieldsSql="select COLUMN_NAME from information_schema.COLUMNS where table_name ='%s'and table_schema = '%s'"%(tableName,self.dbName)
#column name列名 information sheet: 信息表
fields=self.get_all(fieldsSql) #执行语句,获取所有表信息(("id,"),("name",),("age,"))
for item in fields: #遍历key
fieldsList.append(item[0]) #添加
res=self.get_all(sql) #获取传参的查询语句的数据,元组类型tuple
for item in res:
items= item
obj = {}
count = 0
for x in item:
obj[fieldsList[count]]=x
count += 1
resList.append(obj)
return resList
def insert(self,sql): #插入
return self.__edit(sql)
def update(self,sql): #修改
return self.__edit(sql)
def delete(self,sql): #删除
return self.__edit(sql)
def __edit(self,sql):
count = 0
try:
self.connet()
count = self.cursor.execute(sql)
self.db.commit() #提交
self.close()
except:
print("事务提交失败")
self.db.rollback()
return count
- 文件orm中:只先封装insert和all功能
from .zjMysql import zjMySQL
class ORM():
def save(self):
#insert into students(name,age) values ("小李",22)
tableName = (self.__class__.__name__).lower() #表名
#self.__class__获取当前的类;__name__获取当前调用的对象的类名;lower()转小写
fieldsStr =valuesStr="(" #fieldsStr代表(name,age);valuesStr代表("小李",22)
for field in self.__dict__: #self.__dict__得到字典的键值对{"小李":22,"小白":23}中的属性名
fieldsStr += (field + ",") #循环1(name, ;循环2 (name,age,
if isinstance(self.__dict__[field],str): #判断key-valuede中value值是否是字符串
valuesStr += ("'"+self.__dict__[field]+"',")
else: #不是则为数字
valuesStr +=(str(self.__dict__[field])+",") #转为字符串
fieldsStr = fieldsStr[:len(fieldsStr)-1]+")" #截取name (name,age,之前,就把逗号去掉,拼接“)”变成(name,age)
valuesStr = valuesStr[:len(valuesStr)-1]+")" #一样的截取掉后面的逗号,("小李",22)
sql = "insert into " +tableName +" "+ fieldsStr+"values "+valuesStr
db = zjMySQL()
db.insert(sql)
def delete(self):
pass
def update(self):
pass
@classmethod #装饰为类方法,类名来调用
def all(cls):
#select * from students
tableName = (cls.__name__).lower()
sql = "select * from " +tableName
db = zjMySQL()
return db.get_all_obj(sql,tableName)
@classmethod
def filter(cls):
pass
- 新建了models,表的属性
from ORM.orm import ORM
class Students(ORM): #继承与ORM
def __init__(self,name,age):
self.name = name
self.age =age
- views/index中
如果没有路由,相应的配置一下路由
注意,路由要放在静态路由((r"/(.*)$",tornado.web.StaticFileHandler,{“path”:os.path.join(config.BASE_DIRS,“static/html”),“default_filename”:“index.html”}),)之前,不然访问路由会报错
class StudentsHandler(RequestHandler): #数据库中获取信息,并展示
def get(self, *args, **kwargs):
stu = Students("小黑",24)
stu.save() #存入数据
运行访问http://127.0.0.1:8989/students
进入数据库刷新
24.应用安全
1. cookie
1. 普通cookie
设置:原型self.set_cookie(name,value,domain=None,expires=None,path="/",expires_days=None,**kwargs)
原理:设置header/Set_Cookie来实现; self.set_header("Set-Cookie","happy=happyeveryday;path=/")
获取:原型cookie=self.get_cookie("sunck","未登录") #如果取不到cookie,则返回“未登录”
清除1:原型 self.clear_cookie(name,path="/",domain=None),#真正删除是浏览器删除的,我们只是让它失效。
清除2:self.clear_all_cookies() #清除所有cookie
2. 安全cookie
概述:Cookie是存储在客户端浏览器中的Cookie,很容易被篡改。Tornado提供了一种简易的加密方式来防止Cookie被恶意的篡改
设置:需要为应用配置一个用来给cookie进行混淆加密的秘钥。生成秘钥:应用base64 和 uuid
设置_原型:self.set_secure_cookie(name,value,expires_days=30,version=None,**kwargs)
获取:原型:self.get_secure_cookie(name,value=None,max_age_days=31,min_version=None)
注意:它也不是完全安全的。一定程度上增加了破解cookie的难度,以后cookie中不要存储一些敏感性的数据 。
3. XSRF
4. 用户验证
1. 普通cookie
- 设置:原型
self.set_cookie(name,value,domain=None,expires=None,path="/",expires_days=None,**kwargs)
- 参数
name:设置cookie的名字
value:cookie的值
domain:提交cookie时匹配的域名,那个ip提交的
path:提交cookie时匹配的路径
expires:设置cookie的有效期,可以为时间戳整数,时间元祖,datetime类型,UTC时间
expires_days:设置cookie有效期的天数,优先级低于expires
- 示列
- 配置路由:
注意,路由要放在静态路由((r"/(.*)$",tornado.web.StaticFileHandler,{“path”:os.path.join(config.BASE_DIRS,“static/html”),“default_filename”:“index.html”}),)之前,不然访问路由会报错
- 配置路由:
(r"/pcookie", index.PcookieHandler), # cookie设置
2.views/index中
class PcookieHandler(RequestHandler):
def get(self, *args, **kwargs):
# self.set_cookie(name,value,domain=None,expires=None,path="/",expires_days=None,**kwargs) #原型
self.set_header("Set-Cookie","happy=happyeveryday;path=/")#原理
self.set_cookie("good","boy")
self.write("ok")
- chrom浏览器访问后F12打开开发工具,Network/pcookie/Headers信息如下,就有我们设置的cookie
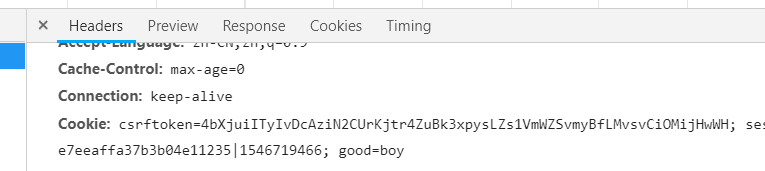
同样的两个cookie都设置成功了,但是我们建议用Set-cookie,而不是Set_hearder

-
获取cookie
- 原型cookie=self.get_cookie(“good”,“未登录”) #如果取不到cookie,则返回“未登录”
- 参数:name,要获取的cookie的名称
default: #如果取不到cookie,则返回default的值 - 示列:
相应的配置一下路由,这里就不再写了
class GetpcookieHandler(RequestHandler): #获取cookie
def get(self, *args, **kwargs):
cookie=self.get_cookie("good","未登录")#如果取不到cookie,则返回“未登录”
print(cookie)
#(pycharm输出)
boy
- 清除cookie
self.clear_cookie(name,path="/",domain=None)#原型
作用:删除名为name,并且同时匹配domain和path的cookie
注意:执行清除cookie操作后,并不是立即删除浏览器端的cookie,而是给cookie的值设置为空,并改变有效期限为失效,真正删除cookie是浏览器进行的删除。
示列:
views/index中
class ClearpcookieHandler(RequestHandler):
def get(self, *args, **kwargs):
# self.clear_cookie(name,path="/",domain=None)#原型
self.clear_cookie("good")
self.write("ok")
别忘了配置url,
(r"/clearpcookie",index.ClearpcookieHandler) ,
浏览器中F12查看,Network/pcookie/Headers如下:
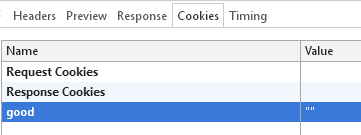
注意:执行清除cookie操作后,并不是立即删除浏览器端的cookie,而是给cookie的值设置为空,并改变有效期限为失效。真正删除cookie是浏览器进行的删除
所以我们调用之前的方面就行实验:
class ClearpcookieHandler(RequestHandler):
def get(self, *args, **kwargs):
# self.clear_cookie(name,path="/",domain=None)#原型
self.clear_cookie("good") #清除单条cookie
# self.clear_all_cookies() #清除所有cookie
self.write("ok")
http://127.0.0.1:9999/getpcookie
访问后:
#(pycharm输出)
未登录
2. 安全cookie
概述:Cookie是存储在客户端浏览器中的Cookie,很容易被篡改。Tornado提供了一种简易的加密方式来防止Cookie被恶意的篡改
设置:需要为应用配置一个用来给cookie进行混淆加密的秘钥。
生成秘钥:需要 base64 uuid
base64
Base64是网络上最常见的用于传输8Bit字节码的编码方式之一,Base64就是一种基于64个可打印字符来表示二进制数据的方法。
在ASCII码中规定,0~31、127这33个字符属于控制字符,32~126这95个字符属于可打印字符,也就是说网络传输只能传输这95个字符,不在这个范围内的字符无法传输。那么该怎么才能传输其他字符呢?其中一种方式就是使用Base64。
Base64,就是使用64个可打印字符来表示二进制数据的方法
uuid
UUID,通用唯一识别码,由以下几部分的组合:当前日期和时间(UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同),时钟序列,全局唯一的IEEE机器识别号(如果有网卡,从网卡获得,没有网卡以其他方式获得),UUID的唯一缺陷在于生成的结果串会比较长。
UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为16^32=2^128,约等于3.4 x 10^38。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
Python直带了base64,不需要安装,uuid如果没有,自行安装一下即可
-
首先,生成一个加密秘钥,如图输出:
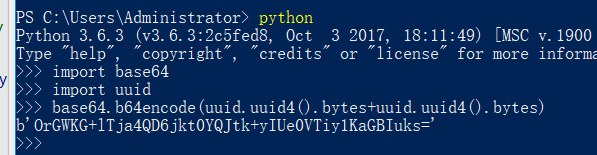
-
config中配置一下
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转义
"cookie_secret":"OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks", #配置加密秘钥
}
- 配置路由
(r"/scookie",index.ScookieHandler), #安全cookie
-
设置原型
原型:self.set_secure_cookie(name,value,expires_days=30,version=None,**kwargs)
views/indes -
参数
- name:cookie的名字
- value:cookie的值
- expires_days:过期天数
- version:版本号
-
作用
设置一个带有签名和时间戳的cookie,防止cookie被伪造 -
示列
class ScookieHandler(RequestHandler): #安全cookie
def get(self,*args,**kwargs):
# self.set_secure_cookie(name,value,expires_days=30,version=None,**kwargs)原型
self.set_secure_cookie("study","up")
self.write("ok")

“2|1:0|10:1546863765|5:study|4:dXA=|cb8238a8688c27445b7cc4cc22586f1842cbb9f0ff4bd62a21bd04900bcae46a”
说明:从左到右依次:
2|-------------------安全cookie的版本,默认使用的是版本2
1:0|------------------默认为0
10:1546863765|----时间戳
5:study|------------cookie名
4:dXA=|------------base64编码的cookie值
|cb8238a8688c27445b7cc4cc22586f1842cbb9f0ff4bd62a21bd04900bcae46a :-------签名值
- 获取
- 原型:self.get_secure_cookie(name,value=None,max_age_days=31,min_version=None)
- 说明:
如果cookie存在,且验证通过,返回cookie值,反之返回None如果cookie存在,且验证通过,返回cookie值,反之返回None
max_age_days不同于expires_days设置浏览器中cookie的有效时间。而max_age_days是过滤安全cookie的时间戳,即获取数值之前时间的cookie
示列:
1.设置views/index
class GetscookieHandler(RequestHandler):
def get(self, *args, **kwargs):
#self.get_secure_cookie(name,value=None,max_age_days=31,min_version=None)原型
soockie=self.get_secure_cookie("study")
print(soockie)
self.write("ok")
- 配置url
(r"/getscookie", index.GetscookieHandler), # 获取cookie
-
输出:
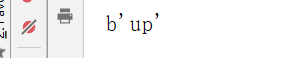
-
注意
他也不是完全安全的。一定程度上增加了破解cookie的难度,以后cookie中不要存储一些敏感性的数据 。
3. XSRF——跨域请求
- cookie计数
作用:记录浏览器访问次数
示列:
1.新建templates/cookienum.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>cookie计数</title>
</head>
<body>
<p>第{{count}}}次访问</p>
</body>
</html>
2.views/index中配置
class CookienumHandler(RequestHandler):
def prepare(self): #这可设置限值访问次数
pass
def get(self, *args, **kwargs):
count = self.get_cookie("count", None)
if not count: #如count不存在,即为第一次访问
count = 1
else:
count=int(count)
count += 1
self.set_cookie("count",str(count)) #将count写到cookie属性中
self.render("cookienum.html", count=count)
3.配置url
(r"/cookienum",index.CookienumHandler), #cookie计数

-
伪造请求
1 我们新建一个pushcookie.html
填写自己的本机地址 http://192.168.3.12:9999/cookienum 此处随意乱写的地址,
放到图片连接里面
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>跨域测试</title>
</head>
<body>
<img src="http://192.168.3.12:9999/cookienum" alt="">
<h1>多刷新几次,然后用 本机地址/cookienum访问</h1>
</body>
</html>
2 访问 http://192.168.3.12:9999/cookienum

3.直接双击新建的pushcookie.html访问,多刷新几次
4.再次访问 http://192.168.3.12:9999/cookienum。你会发现

**总结:**在我们不知情并且没有授权的情况下,访问“pushcookie” 网站,"cookie计数器"网站里面的cookie就被使用,以至于"cookie计数器"认为是他自己调用了CookienumHandler的逻辑。
所以:为了防止这种攻击,一般相对于安全的操作是不放在GET请求中,常常使用的是post请求
- XSRF保护-使用同源策略
同源策略:
指域名、协议与端口相同,不同源的客户端脚本(JavaScript、ActionScript)在没明确授权的情况下,不能读写对方的资源

原理测试
1.首先新建templates/postcookie.html
以前用过的一个简单提交表单
密码:
爱好:权利 金钱 书籍
``` 2.views/index中配置一下 需要配置一下相应的url路由
(r"/cookieprotect",index.Cookie_protectHandeler),#防止xsrf
class CookienumHandler(RequestHandler): #之前的计数handler,修改了一下
def prepare(self): #这可设置限值访问次数,
pass
def get(self, *args, **kwargs): #不在让他进行修改cookie
count = self.get_cookie("count", "未登录")
self.render("cookienum.html", count=count)
class Cookie_protectHandeler(RequestHandler):
def get(self, *args, **kwargs):
self.render("postcookie.html")
def post(self, *args, **kwargs):
count = self.get_cookie("count", None)
if not count: # 如count不存在,即为第一次访问
count = 1
else:
count=int(count)
count += 1
self.set_cookie("count",str(count)) #将count写到cookie属性中
self.redirect("/cookienum") #重定向到/cookienum
http://本机地址:9999/cookieprotect
什么都不用填写,直接点解login登录后:

直接访问双击之前的pushcookie.html访问浏览器,并且多次刷新

然后进入http://本机地址:9999/cookienum,还是23次访问,并没有进行改变

发现 get请求并不能进行修改了,但是如果我们修改pushcookie.html为post请求,如下面,
<form action="http://192.168.3.23:9999/cookieprotect" method="post">
自己修改为本机地址进行测试
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{{static_url('css/postfile.css')}}">
<script type="text/javascript" charset="utf-8" src="{{static_url('js/test1.js')}}"></script>
</head>
<body>
<div>
<form action="http://192.168.2.13:9999/cookieprotect" method="post">
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login"><br/>
</form>
</div>
</body>
</html>
发现还是能进行修改,这是应为我们还没有开启xsrf保护,只需要设置一下即可
开启xsrf保护
1.在config配置文件中setting中 添加 “xscf_cookie”:True,
“cookie_secret”:“OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks”, 这个自定义的加密值是要用到的。
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转义
"cookie_secret":"OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks", #混淆加密
"xscf_cookie":True, #开启xsrf保护
}
现在是开启了保护,但是你会发现,http://192.168.5.12:9999(本机地址)/cookieprotect
我们同源的也不能进行访问,还要进行一个应用才行

xsrf应用
1.模板中应用
表单 <form action="/cookieprotect" method="post">后面加上 {% module xsrf_form_html() %}
注意: {% module xsrf_form_html() %}帮我们做了两件事
====为浏览器设置了——xsrf的安全cookie,这个cookie在关闭浏览器后会失效,所以说之前我们自定义的混淆加密是要应用到的;

====为模板表单添加了一个隐藏的域,名为_xsrf,值为——xsrfcookie这个的值
示列:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>开启保护</title>
</head>
<body>
<form action="/cookieprotect" method="post">
{% module xsrf_form_html() %}
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login"><br/>
</form>
</body>
</html>
这样在点提交后,就成功了

但是的但是,他还不是绝对安全的
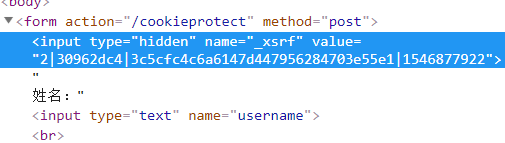
<input type="hidden" name="_xsrf" value="2|30962dc4|3c5cfc4c6a6147d447956284703e55e1|1546877922">
我们将这样的隐藏的域,名为_xsrf,值为——xsrfcookie这个的值,添加到html伪造请求,
测试时(修改一下对应的自己的主机地址)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="{{static_url('css/postfile.css')}}">
<script type="text/javascript" charset="utf-8" src="{{static_url('js/test1.js')}}"></script>
</head>
<body>
<div>
<form action="http://192.168.6.33:9999/cookieprotect" method="post">
<input type="hidden" name="_xsrf" value="2|30962dc4|3c5cfc4c6a6147d447956284703e55e1|1546877922">
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login"><br/>
</form>
</div>
</body>
</html>

结果发现,还是可以的,所以不是绝对的安全
2.非模板中的应用
-------------------------------------第一种----------------------------
为{% module xsrf_form_html() %}方式的原理
新建templates/postcookie2.html
手动设置input输入框,
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>开启保护</title>
</head>
<body>
<form action="/cookieprotect2" method="post">
<input id="xsrf_cookie" type="hidden" name="_xsrf" value="">
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login"><br/>
</form>
<script>
function Getcookie(name) {
// 查找cookie
var cook = document.cookie.match("\\b"+name+"=([^:]*)\\b")
// 存在则返回cook,不存在则返回undefined
return cook ? cook[1]:undefined
}
//在控制台Console打印 获取的cookie
console.log(Getcookie("_xsrf"))
}
</script>
</body>
</html>
views/index配置
class Cookie_protect2Handeler(RequestHandler):
def get(self, *args, **kwargs):
self.render("postcookie2.html")
def post(self, *args, **kwargs):
count = self.get_cookie("count", None)
if not count: # 如count不存在,即为第一次访问
count = 1
else:
count = int(count)
count += 1
self.set_cookie("count", str(count)) # 将count写到cookie属性中
self.redirect("/cookienum") # 重定向到/cookienum
class Set_xsrfcookieHandeler(RequestHandler): # 手动设置xsrf_cookie
def get(self, *args, **kwargs):
self.xsrf_token #设置一个_xsrf的cookie
self.finish("ok")
配置url路由
(r"/cookieprotect2", index.Cookie_protect2Handeler), #防止xsrf,非模板中应用
(r"/setxsrfcookie",index.Set_xsrfcookieHandeler), #手动设置
设置xsrf_cookie
打印获得的cookie
最后将获取的cookie放到手动设置的input输入框中
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>开启保护</title>
</head>
<body>
<form action="/cookieprotect2" method="post">
<input id="xsrf_cookie" type="hidden" name="_xsrf" value="">
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
爱好:<input type="checkbox" value="权利" name="hobby">权利
<input type="checkbox" value="金钱" name="hobby">金钱
<input type="checkbox" value="书籍" name="hobby">书籍<br/>
<input type="submit" value="login"><br/>
</form>
<script>
function Getcookie(name) {
// 查找cookie
var cook = document.cookie.match("\\b"+name+"=([^:]*)\\b")
// 存在则返回cook,不存在则返回undefined
return cook ? cook[1]:undefined
}
// 将拿到的cookie放到之前的input输入框,通过getElementById("xsrf_cookie")查找id="xsrf_cookie"的输入框,放进value属性中
document.getElementById("xsrf_cookie").value=Getcookie("_xsrf")
</script>
</body>
</html>
完成,可以自行测试,这里就不再说了,但是这种方式一般不用,因为太麻烦了
-------------------------------------第二种----------------------------
发起Ajax请求
1.新建templates/postcookie3.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>开启保护</title>
<!--<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>-->
<script type="text/javascript" charset="utf-8" src="{{static_url('js/jquery-3.3.1.min.js')}}"></script>
</head>
<body>
<input id="xsrf_cookie" type="hidden" name="_xsrf" value="">
姓名:<input id="id_username" type="text" name="username"><br/>
密码:<input id="id_password" type="password" name="passwd"><br/>
<button onclick="login()">登录</button>
<script>
function Getcookie(name) {
// 查找cookie
var cook = document.cookie.match("\\b" + name + "=([^:]*)\\b")
// 存在则返回cook,不存在则返回undefined
return cook ? cook[1] : undefined
}
function login() {
var name = document.getElementById("id_username")
var passwd = document.getElementById("id_password")
// 将信息表单传递过去,然后回调打印ok
$.post("/cookieprotect2","_xsrf=" + Getcookie('_xsrf') + "&usernname=" + name + "&passwd=" + passwd , function (data) {
alert("ok")
})
}
</script>
</body>
</html>
在views/index中配置
和之前差不多,主要是是为了展示,不混淆
class Cookie_protect3Handeler(RequestHandler):
def get(self, *args, **kwargs):
self.render("postcookie3.html")
def post(self, *args, **kwargs):
count = self.get_cookie("count", None)
if not count: # 如count不存在,即为第一次访问
count = 1
else:
count = int(count)
count += 1
self.set_cookie("count", str(count)) # 将count写到cookie属性中
self.redirect("/cookienum") # 重定向到/cookienum
class Set_xsrfcookieHandeler(RequestHandler): # 手动设置xsrf_cookie
def get(self, *args, **kwargs):
self.xsrf_token # 设置一个_xsrf的cookie
self.finish("ok")
url配置一下:
(r"/cookieprotect3", index.Cookie_protect3Handeler), # 防止xsrf,非模板中应用,方法二
(r"/setxsrfcookie",index.Set_xsrfcookieHandeler), #手动设置
一样的,我们先访问/setxsrfcookie路由来设置一个cookie
在进行/cookieprotect3路由访问,直接点击登录,弹处窗口ok,

这里多次刷新/cookieprotect3页面,再访问计数页面,

成功:这一种也类似表单数据,jquery中
.
p
o
s
t
(
)
仅
仅
只
能
发
起
p
o
s
t
请
求
,
所
携
带
的
参
数
是
比
较
少
了
我
们
最
常
用
的
是
j
q
u
e
r
y
中
.post()仅仅只能发起post请求,所携带的参数是比较少了 我们最常用的是jquery中
.post()仅仅只能发起post请求,所携带的参数是比较少了我们最常用的是jquery中.ajax(),即第三种方法
-------------------------------------第三种----------------------------
这里注意:每一次测试时,都需要清除一下cookie。会导致原来测试的cookie和现在获取验证的cookie不一致。
WARNING:tornado.general:403 POST /cookieprotect4 (127.0.0.1): '_xsrf' argument has invalid format
新建templates/postcookie4.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>开启保护</title>
<!--<script src="https://code.jquery.com/jquery-3.3.1.min.js"></script>-->
<script type="text/javascript" charset="utf-8" src="{{static_url('js/jquery-3.3.1.min.js')}}"></script>
</head>
<body>
姓名:<input id="id_username" type="text" name="username" value=""><br/>
密码:<input id="id_password" type="password" name="passwd" value=""><br/>
<button onclick="login()">登录</button>
<script>
function Getcookie(name) {
// 查找cookie
var cook = document.cookie.match("\\b" + name + "=([^:]*)\\b")
// 存在则返回cook,不存在则返回undefined
return cook ? cook[1] : undefined
}
function login() {
var name = document.getElementById("id_username").value;
var passwd = document.getElementById("id_password").value;
data = {
"username":name,
"passwd": passwd,
};
// 将字典转化为json字符串
var datastr = JSON.stringify(data);
$.ajax({
url: "/cookieprotect4",
method: "POST",
// 设置请求头
headers: {
"X-XSRFToken": Getcookie("_xsrf")
},
data: data,
success: function (data) {
alert("ok");
},
})
}
</script>
</body>
</html>
views/index中修改一下
class Set_xsrfcookieHandeler(RequestHandler): # 手动设置xsrf_cookie
def get(self, *args, **kwargs):
self.xsrf_token # 设置一个_xsrf的cookie
self.finish("ok") #刷新缓存
class Cookie_protect4Handeler(RequestHandler):
def get(self, *args, **kwargs):
self.render("postcookie4.html")
def post(self, *args, **kwargs):
count = self.get_cookie("count", None)
if not count: # 如count不存在,即为第一次访问
count = 1
else:
count = int(count)
count += 1
self.set_cookie("count", str(count)) # 将count写到cookie属性中
self.redirect("/cookienum") # 重定向到/cookienum
配置一下url路由 application
(r"/cookieprotect4", index.Cookie_protect4Handeler), # 防止xsrf,非模板中应用,方法三
(r"/setxsrfcookie", index.Set_xsrfcookieHandeler), # 手动设置,之配置的设置cookie
每一次测试都要进行清除cookie

然后访问设置cookie的路由设置一下cookie
最后访问提交

如果这里再次刷新登录,你就会发现,报错了,这时候就又要进行清除一下cookie,再进行设置.因为原来测试的cookie和现在获取验证的cookie不一致。
问题:还需要解决手动添加xsrf_cookie的设置
自动设置xsrf_cookie
设置静态主页
以前的静态路由:
(r"/(.*)$",tornado.web.StaticFileHandler{"path":os.path.join(config.BASE_DIRS,"static/html"),"default_filename":"index.html"}),
#StaticFileHandler应用静态文件,注意要放在所有路由的下面。用来放静态主页
修改之后:
(r"/(.*)$", index.Static_FileHandler,{"path": os.path.join(config.BASE_DIRS, "static/html"), "default_filename": "index.html"}),
#由于我们想让用户进入主页即自动设置xsrf_cookie,所以我们用到继承 的方式,
让index.StaticFileHandler继承父tornado.web.StaticFileHandler,再向里面添加设置xsrf设置。
配置一下views/index
class Static_FileHandler(StaticFileHandler):
def __init__(self,*args,**kwargs):
super(StaticFileHandler, self).__init__(*args,**kwargs)
#调用父类中的init
self.xsrf_token #设置_xsrf
# 由于我们想让用户进入主页即自动设置xsrf_cookie,所以我们用到继承 的方式,让index.StaticFileHandler继承父类tornado.web.StaticFileHandler,再向里面重写设置xsrf设置
我们清楚浏览器cookie后进入静态主页
示例:http://127.0.0.1:8888/

用户验证
用处:受到用户请求后进行预先判断用户的认证状态(是否登录),若验证通过则正常处理,否则进入登录页面
应用:tornado.web.authenticated装饰器
1.tornado.web.authenticated装饰器:
Tornado将确保这个方法的主体只有合法的用户才有能调用
- def get_current_user(self):方法
验证用户的逻辑放在该方法中,如果方法返回的为Teue说明验证成功,否则验证失败
验证失败,会将客服重定向到配置config中的login_url中的login_url 所指定的路由
测试:
新建两个templates/login.html
templates/heme.html
login.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录</title>
</head>
<body>
<!--<form action="/login?next=/home" method="post"> -->
<!--action不能写死-->
<form action="{{url}}" method="post">
<!--保证next的值为哪一个页面进入的该login页面/login?next=/homes-->
{% module xsrf_form_html() %}
姓名:<input type="text" name="username"><br/>
密码:<input type="password" name="passwd"><br/>
<input type="submit" value="login"><br/>
</form>
</body>
</html>
home.htnl
class LoginHandler(RequestHandler): #用户验证
def get(self,*args,**kwargs): #目的将路径传递给页面,不让login.html页面的路径写死
next = self.get_argument("next","/") #获取 next
url = "login?next="+next
self.render("login.html",url=url) #传给页面
def post(self,*args,**kwargs): #接收post请求
name = self.get_body_argument("username")
pwd = self.get_body_argument("passwd")
if name == "1" and pwd =="1": #先测试一下,把密码账号写死
next = self.get_argument("next", "/")
# 这里就是获取http://127.0.0.1:12343/login?next=%2Fhomes,中的next的值,%2F为‘/’,但是next可能没有,所以设置默认值为/,http://127.0.0.1:12343/login?next=%2Fhomes的由来,后面会说明。
#但是这里因为是home重定向过来的http://127.0.0.1:8989/login?,即next没得,所以 默认为/
self.redirect(next + "?flag=logined") # 所以这里为 /?flag=logined,(访问之前设置的静态主页)然后我们再给他传一个参数flag表示已经登录
else:
next = self.get_argument("next", "/") #这里的next为%2Fhomes即/homes
self.redirect("login?next="+ next)
class Home_LoginHandler(RequestHandler):
"""
#当用户登陆后才能进入home页面,
"""
def get_current_user(self):#用来验证用户,返回True则验证成功,验证不通过,将客户重定向到配置中的
flag = self.get_argument("flag",None) #只要能取到flag就表示已经登录True,不能则为False
return flag
@tornado.web.authenticated #作用,验证成功了执行下面的get语句,不成功则重定向到config中 setting里面的 "login_url":"/login", 即login.html页面
def get(self,*args,**kwargs):
self.render("home.html")
application中配置url路由
r"/login",index.LoginHandler), #用户验证
(r"/homes",index.Home_LoginHandler),#验证跳转
config配置:
BASE_DIRS = os.path.dirname(__file__)
setting = {
"static_path":os.path.join(BASE_DIRS,"static"), #静态文件
"template_path":os.path.join(BASE_DIRS,"templates"), #视图
"debug":True , #修改完文件后服务自动启动
# "autoescape":None, #关闭自动转义
"cookie_secret":"OrGWKG+lTja4QD6jkt0YQJtk+yIUe0VTiy1KaGBIuks", #混淆加密
"xsrf_cookies":True, #开启xsrf保护
"login_url":"/login", #用户验证不成功时,重定向到/login
}
解释:next的由来
即http://127.0.0.1:12343/login?next=%2Fhomes由来
我们进入home界面, 因为def get_current_user(self)返回False 重定向到login页面 地址改变为:
http://127.0.0.1:12343/login?next=%2Fhomes
其中%2F为 “/” ;即next=/homes,
login?next=%2Fhomes表示是从homes页面进到login页面

GIF来了

说明:homes没有获取到flag,登录重定向---->login登录界面–>密码账号不对重定向–>login登录—>密码正确重定向–>hoems获取到flage重定向—>home主页
25.异步

- 异步原理
<生成器>
带有 yield 关键字的的函数在 Python 中被称之为 generator(生成器)。Python 解释器会将带有 yield 关键字的函数视为一个 generator 来处理。一个函数或者子程序都只能 return 一次,但是一个生成器能暂停执行并返回一个中间的结果 —— 这就是 yield 语句的功能 : 返回一个中间值给调用者并暂停执行。
import time
import threading
def genCoroutime(func):
def wrapper(*args, **kwargs):
gen1 = func() # reqA生成器函数 激活,
gen2 = next(gen1) # 运行到reqA中yield的右边longIo(),并停止运行(挂起),此时gen2为longIo的一个对象,即longIo生成器函数激活
def run(g):
res = next(g) # longIo的生成器运行, 进入longIo()运行到yield 的右边"good job "时停止(挂起)
try: # res即为"good job "
gen1.send(res) # 返回给reqA数值res,并使的reqA中res=yield longIo() yield向下执行
except StopIteration as e: # 迭代器 next()在所有行完成后-引发StopIteration()异常
pass
threading.Thread(target=run, args=(gen2,)).start() # 启动线程执行run,将参数gen2传入args=(gen2,)逗号必须要有;主线程处理reqB()
return wrapper
# handler获取数据(数据库。其他服务器。循环耗时)
def longIo():
print("开始耗时操作")
time.sleep(5)
print("结束耗时操作")
# 返回数据
yield "good job "
# 客户端A请求
@genCoroutime
def reqA():
print("开始处理 ")
res = yield longIo()
print("接收到loogIo的响应数据:", res)
print("结束 处理reqA")
# 客户端B的请求
def reqB():
print("开始处理reqB")
time.sleep(2)
print("结束 处理reqB")
# tornado服务
def main():
reqA()
reqB()
while 1:
time.sleep(0.1)
pass
if __name__ == "__main__":
main()

2. Tornado中的异步
概述:因为epoll主要是用来解决网络中的io并发的问题,所以Rornado的异步也是主要体现在网络的io异步上,即异步web请求。
测试一:模拟同步阻塞等待
views/index中
class Showstudent(RequestHandler):
def get(self,*args,**kwargs):
#获取所有学生的信息
time.sleep(20)
class Showsloop(RequestHandler):
def get(self, *args, **kwargs):
self.write("完成")
相应的配置路由
(r"/showstudent",index.Showstudent), #异步测试1
(r"/showsleep",index.Showsloop), #异步测试1
我们同时打开两个窗口,先进入/showstudent,后进/showsleep。
/showstudent因为设置了sleep=30,所以浏览器一直等待响应
而/showsleep,因为/showstudent在等待,所以也在等待/showstudent的完成
30秒到了,两个都响应了
测试二:改进为回调异步
from tornado.httpclient import AsyncHTTPClient
class Showstudent(RequestHandler):
def on_response(self,response): #回调函数,response响应
if response.error:
self.send_error(500)
else:
data =(response.body) # 有时候需要将数据转化为json字符串可以用 data=json.loads(response.body)
self.write(data) #在浏览器中展示
print(data) #pycharm中打印
self.finish()
@tornado.web.asynchronous #不关闭通信的通道
def get(self,*args,**kwargs):
#获取所有学生的信息
# time.sleep(20)
url="http://blog.jobbole.com/114397/" #请求的服务器
client = AsyncHTTPClient() #创建客户端
client.fetch(url,self.on_response) #发起请求,请求成功,执行回调函数。
class Showsloop(RequestHandler):
def get(self, *args, **kwargs):
self.write("完成")


接下来,把网络断掉,再执行一次,你会发现showstudent页面在请求的时候,访问showsleep时刻也访问的,这就实现了异步操作。
测试三:协程异步
views/index中
class Showstudent3(RequestHandler):
@tornado.gen.coroutine #不关闭通信的通道
def get(self,*args,**kwargs):
#获取所有学生的信息
# time.sleep(20)
url="http://blog.jobbole.com/114397/" #请求的服务器
client = AsyncHTTPClient() #创建客户端
res = yield client.fetch(url) #发起请求,请求成功,执行回调函数。
#client.fetch()执行一个请求,异步返回一个“HTTPResponse”
if res.error:
self.send_error(500)
else:
data = (res.body) # 如果需要将数据转化为json字符串 则data = json.loads(res.body)
self.write(data)
print(data)
self.finish() # 刷新缓存
class Showsleep3(RequestHandler): #测试异步
def get(self, *args, **kwargs):
self.write("完成")
application中配置路由
(r"/showstudent3", index.Showstudent3),# 异步测试3
(r"/showsleep3", index.Showsleep3), # 异步测试2-3

一样的:接下来,把网络断掉,再执行一次,你会发现showstudent页面在请求的时候,访问showsleep时刻也访问的,这就实现了异步操作。
实际上我们回调函数异步就像是重写了 协程异步中的异步装饰器,只是回调函数跟容易理解,协程异步更简洁方便。
将异步的web请求单独提取出来
class Showstudent4(RequestHandler):
@tornado.gen.coroutine
def get(self, *args, **kwargs):
res=yield self.getDate()
self.write(res)
@tornado.gen.coroutine
def getDate(self):
url = "http://blog.jobbole.com/114397/" # 请求的服务器
client = AsyncHTTPClient() # 创建客户端
res = yield client.fetch(url) # 发起请求,请求成功,执行回调函数。
# client.fetch()执行一个请求,异步返回一个“HTTPResponse”
if res.error:
self.send_error(500)
else:
data = (res.body)
# 如果需要将数据转化为json字符串 data = json.loads(res.body)
raise tornado.gen.Return(data) #类似生成器中 .send,将值data传回 res=yield self.getDate() 即res=data
访问验证:

连接数据库:

26.WebSocket
官方文档:https://developer.mozilla.org/zh-CN/docs/Web/API/WebSocket

聊天室连接测试:
views/index中
from tornado.websocket import WebSocketHandler #socket聊天室
class Chathandler(RequestHandler):
def get(self, *args, **kwargs):
self.render("chat.html")
class Chathandler1(WebSocketHandler):
users=[] #存放连接信息
def open(self): #当一个WebSocket连接建立后会被服务端调用
self.users.append(self)
for user in self.users:
# 向每一个人发送消息
print(self.request.remote_ip)
user.write_message("欢迎{}进入房间".format(self.request.remote_ip))
#write_message()主动向客服端发送message消息,message可以使字符串挥着字典(自动转为json字符串)
def on_message(self, message):
pass
def on_close(self):
pass
def check_origin(self, origin):
return True
新建templates/chat.html中
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>聊天界面</title>
<script type="text/javascript" charset="utf-8" src="{{static_url('js/jquery-3.3.1.min.js')}}"></script>
</head>
<body>
<div id="contents" style="width: 500px;height: 500px;overflow: auto">
</div>
<div>
<input type="text" id="message">
<button onclick="sendMessage()">发送</button>
</div>
<script>
// 建立WebSocket连接,当页面加载后,自动执行/chat1 请求设置的服务端
var ws =new WebSocket("ws://192.168.137.1:8000/chat1");
ws.onmessage=function (e) {
// 找到id=contents标签,向里面天剑p标签和内容服务端传过来的e参数的data里面的内容
$("#contents").append("<p>"+e.data+"</p>")
}
function sendMessage() {
console.log("******")
}
</script>
</body>
</html>
application中配置url路由
(r"/chat",index.Chathandler),#socket聊天客户端
(r"/chat1", index.Chathandler1), # socket聊天服务端

说明:
当我们进入chat页面的时候,会调用chat.html中的var ws =new WebSocket(“ws://192.168.137.1:8000/chat1”);
服务端 执行操作class Chathandler1(WebSocketHandler):后
user.write_message(“欢迎{}进入房间”.format(self.request.remote_ip))将数据发送给客户端,
客户端接收后 $("#contents").append("
"+e.data+"
")展示内容出来聊天室功能测试
from tornado.web import RequestHandler
from tornado.websocket import WebSocketHandler #socket聊天室
class Chathandler(RequestHandler):
def get(self, *args, **kwargs):
self.render("chat.html")
class Chathandler1(WebSocketHandler):
users=[] #存放连接信息
def open(self): #当一个WebSocket连接建立后会被自动调用
self.users.append(self)
for user in self.users:
# 向每一个人发送消息
print("欢迎{}进入房间".format(self.request.remote_ip))
user.write_message("欢迎{}进入房间".format(self.request.remote_ip))
#write_message()主动向客服端发送message消息,message可以使字符串挥着字典(自动转为json字符串)
def on_message(self, message): #当客服端发送消息过来时调用
for user in self.users:
# 向每一个人发送消息
print("{}说:{}".format(self.request.remote_ip,message))
user.write_message("{}说:{}".format(self.request.remote_ip,message))
# write_message()主动向客服端发送message消息,message可以使字符串挥着字典(自动转为json字符串)
def on_close(self): #关当WebSocket关闭,(客户端主动关闭)的时候自动调用
self.users.remove(self)
for user in self.users:
# 向每一个人发送消息
print("{}退出房间".format(self.request.remote_ip))
user.write_message("{}退出房间".format(self.request.remote_ip))
def check_origin(self, origin):
#判断源origin,对于符合条件的请求源允许连接,类似同源策略,True/False
return True
chat.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>聊天界面</title>
<script type="text/javascript" charset="utf-8" src="{{static_url('js/jquery-3.3.1.min.js')}}"></script>
</head>
<body>
<div id="contents" style="width: 500px;height: 500px;overflow: auto">
</div>
<div>
<input type="text" id="message">
<button onclick="sendMessage()">发送</button>
</div>
<script>
// 建立WebSocket连接,当页面加载后,自动执行/chat1连接路由在pycharm里面执行对应的Handler
var ws =new WebSocket("ws://192.168.137.1:8888/chat1");
ws.onmessage=function (e) {
// 找到id=contents标签,向里面天剑p标签和内容服务端传过来的e参数的data里面的内容
$("#contents").append("<p>"+e.data+"</p>")
};
function sendMessage() {
var message = $("#message").val();
// 发送消息
ws.send(message);
// 清空输入框内容
$("#message").val("")
}
</script>
</body>
</html>


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)