
对于JDK1.8 HashMap源码的学习总结
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑。本文是对JDK8的HashMap源码进行学习分析和心得总结。 在研读源代码之前,我们要搞清楚一些基础的数据结构知识: 数...
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出现在各类的面试题中,重要性可见一斑。本文是对JDK8的HashMap源码进行学习分析和心得总结。
在研读源代码之前,我们要搞清楚一些基础的数据结构知识:
数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1),接下来我们就来看看哈希表是如何实现达到惊艳的常数阶O(1)的。
还有一个相对来说有些难度的红黑树结构,鉴于描述红黑树结构的篇幅太长,这里我就不多赘述了,不过这不影响我们来学习HashMap的源码思想。
这是HashMap的基本结构(JDK 1.8)
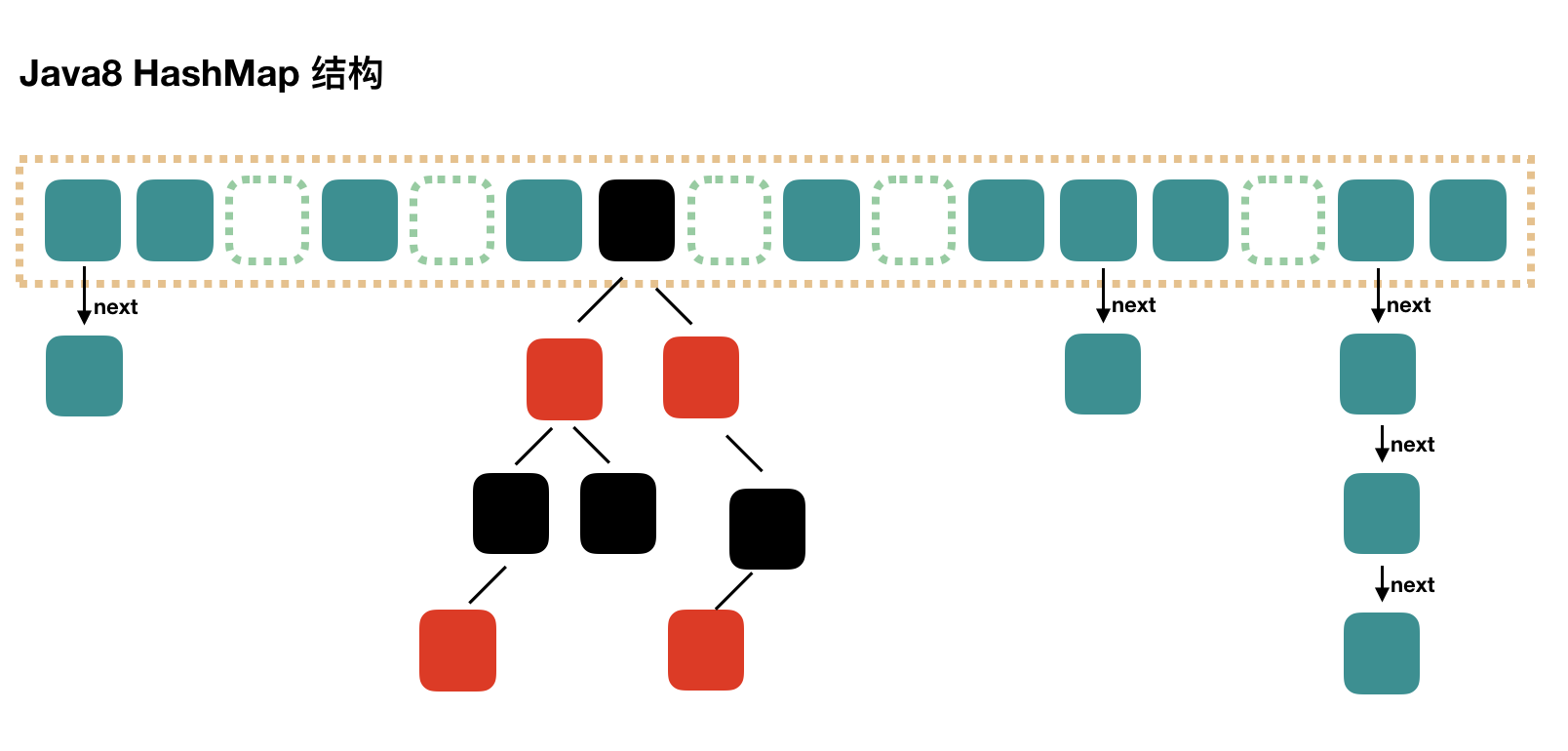
如图所示,HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
这是HashMap的基础结构,以下是我在学习中认为源码特别有意思的地方:
- HashMap是通过Entry中的 next属性(类似于链表指针)来将数组和Node/红黑树进行联系。
- HashMap Key的Hash值是通过高16位与低16位的^位运算来处理的。通过这种算法,尽可能保证数组的散列分布均匀并且有效率。
- 初始数组长度为16,而且扩容必须遵循2的幂次方原则;Default 负载因子为0.75f。也就是说,如果数组存储超过了16*0.75=12之后,会自动扩容。
- 链表结构和红黑树结构的转换阈值,>8 or <6。
- Resize()方法源代码非常精妙
- 线程非安全,如果使用synchronized方法效率会很低,在JDK1.8中我们可以使用ConcurrentHashMap。
- ConcurrentHashMap 主要通过。CAS,Spread以及局部Synchronized方法块来处理并发问题。(compareAndSwapInt)
本文描述了我在学习HashMap源码的过程中总结的一部分认为好的地方,并结合源码做了一点点的分析,最后简单介绍了精妙所在。希望本篇文章能帮助到大家,同时也欢迎讨论指导,谢谢支持!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)