
利用Spark MLIB实现电影推荐
源码及数据集:https://github.com/luo948521848/BigDataSpark 机器学习库MLLibMLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要...
利用Spark MLIB实现电影推荐
源码及数据集:https://github.com/luo948521848/BigData
Spark 机器学习库MLLib
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
- 1.算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
- 2.特征化公交:特征提取、转化、降维,和选择公交;
- 3.管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
- 4.持久性:保存和加载算法,模型和管道;
- 5.实用工具:线性代数,统计,数据处理等工具。
Spark 机器学习库从 1.2 版本以后被分为两个包
•spark.mllib包含基于RDD的原始算法API。Spark MLlib 历史比较长,在1.0 以前的版本即已经包含了,提供的算法实现都是基于原始的 RDD。
•spark.ml 则提供了基于DataFrames 高层次的API,可以用来构建机器学习工作流(PipeLine)。ML Pipeline 弥补了原始 MLlib 库的不足,向用户提供了一个基于 DataFrame 的机器学习工作流式 API 套件。
使用 ML Pipeline API可以很方便的把数据处理,特征转换,正则化,以及多个机器学习算法联合起来,构建一个单一完整的机器学习流水线。这种方式给我们提供了更灵活的方法,更符合机器学习过程的特点,也更容易从其他语言迁移。Spark官方推荐使用spark.ml。如果新的算法能够适用于机器学习管道的概念,就应该将其放到spark.ml包中,如:特征提取器和转换器。开发者需要注意的是,从Spark2.0开始,基于RDD的API进入维护模式(即不增加任何新的特性),并预期于3.0版本的时候被移除出MLLib。
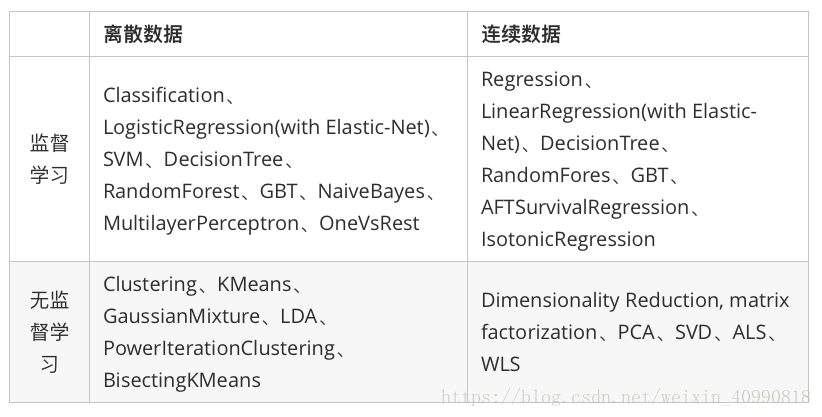
Spark在机器学习方面的发展非常快,目前已经支持了主流的统计和机器学习算法。纵观所有基于分布式架构的开源机器学习库,MLlib可以算是计算效率最高的。MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤。下表列出了目前MLlib支持的主要的机器学习算法:
经典的电影推荐系统是通过将用户信息通过不同维度展现出来。同现相似度可用于为协调过滤推荐中,查找相似的物品或者用户。下面对同相似度进行简单的定义
物品i和物品j的同相似度公式定义:
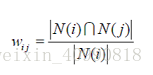
其中,分母是喜欢物品i的用户数,而分子则是同时喜欢物品i和物品j的用户数。因此,上述公式可用理解为喜欢物品i的用户有多少比例的用户也喜欢j (和关联规则类似)
但上述的公式存在一个问题,如果物品j是热门物品,有很多人都喜欢,则会导致Wij很大,接近于1。因此会造成任何物品都和热门物品交有很大的相似度。为此我们用如下公式进行修正:
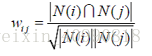
这个格式惩罚了物品j的权重,因此减轻了热门物品和很多物品相似的可能性。(也归一化了[i,j]和[j,i]
数据集
电影:电影id 、电影名、类型
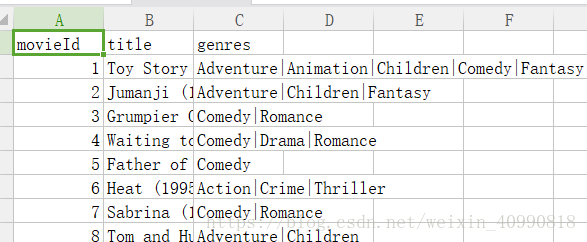
评分:用户id 、电影id 、评分、时间戳
具体代码部分(Scala)
package com.luo
import java.util.Random
import org.apache.log4j.Logger
import org.apache.log4j.Level
import scala.io.Source
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd._
import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
object Recomment {
def main(args: Array[String]): Unit = {
//建立spark环境
val conf = new SparkConf().setAppName("movieRecomment")
val sc = new SparkContext(conf)
//去读文件并且进行预处理
val ratings = sc.textFile("ratings.dat").map {
line =>
val fields = line.split("::")
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
//时间戳、用户编号、电影编号、评分
//表中已预设名称了
}
val movies = sc.textFile("movies.dat").map { line =>
val fields = line.split("::")
// format: (movieId, movieName)
(fields(0).toInt, fields(1))
}.collect.toMap
//记录数、用户数、电影数
val numRatings = ratings.count
val numUsers = ratings.map(_._2.user).distinct.count
val numMovies = ratings.map(_._2.product).distinct.count
println("从" + numRatings + "记录中" + "分析了" + numUsers + "的人观看了" + numMovies + "部电影")
//提取一个得到最多评分的电影子集,以便进行评分启发
//矩阵最为密集的部分
val mostRatedMovieIds = ratings.map(_._2.product)
.countByValue()
.toSeq
.sortBy(-_._2)
.take(50) //50个
.map(_._1) //获取他们的id
val random = new Random(0)
val selectedMovies = mostRatedMovieIds.filter(
x => random.nextDouble() < 0.2).map(x => (x, movies(x))).toSeq
//引导或者启发评论
//调用函数 从目前最火的电影中随机获取十部电影
//让用户打分
val myRatings = elicitateRatings(selectedMovies)
val myRatingsRDD = sc.parallelize(myRatings)
//将评分系统分成训练集60%,验证集20%,测试集20%
val numPartitions = 20
//训练集
val training = ratings.filter(x => x._1 < 6).values
.union(myRatingsRDD).repartition(numPartitions)
.persist
//验证集
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8).values
.repartition(numPartitions).persist
//测试集
val test = ratings.filter(x => x._1 >= 8).values.persist
val numTraining = training.count
val numValidation = validation.count
val numTest = test.count
println("训练集数量:" + numTraining + ",验证集数量: " + numValidation + ", 测试集数量:" + numTest)
//训练模型,并且在验证集上评估模型
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation)=" + validationRmse + "for the model trained with rand =" + rank + ", lambda=" + lambda + ", and numIter= " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//在测试集中 获得最佳模型
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank=" + bestRank + " and lambda =" + bestLambda + ", and numIter =" + bestNumIter + ", and itsRMSE on the test set is" + testRmse + ".")
//产生个性化推荐
val myRateMoviesIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRateMoviesIds.contains(_)).toSeq)
val recommendations = bestModel.get.predict(candidates.map((0, _)))
.collect()
.sortBy((-_.rating))
.take(50)
var i = 1
println("以下电影推荐给你")
recommendations.foreach { r =>
println("%2d".format(i) + ":" + movies(r.product))
i += 1
}
}
/** Compute RMSE (Root Mean Squared Error). */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long) = {
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
/** Elicitate ratings from command-line. */
def elicitateRatings(movies: Seq[(Int, String)]) = {
val prompt = "给以下电影评分(1——5分)"
println(prompt)
val ratings = movies.flatMap { x =>
var rating: Option[Rating] = None
var valid = false
while (!valid) {
print(x._2 + ": ")
try {
val r = Console.readInt
if (r < 0 || r > 5) {
println(prompt)
} else {
valid = true
if (r > 0) {
rating = Some(Rating(0, x._1, r))
}
}
} catch {
case e: Exception => println(prompt)
}
}
rating match {
case Some(r) => Iterator(r)
case None => Iterator.empty
}
}
if (ratings.isEmpty) {
error("No rating provided!")
} else {
ratings
}
}
}
将项目打包成jar格式 上传到Spark集群中,注意上传之后:
Spark 提交任务时,报: Invalid signature file digest for Manifest main attributes
https://blog.csdn.net/dai451954706/article/details/50086295
zip -d <jar file name>.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF
启动spark
bin/spark-submit --master local --class com.luo.Recomment MoiveRecomment.jar
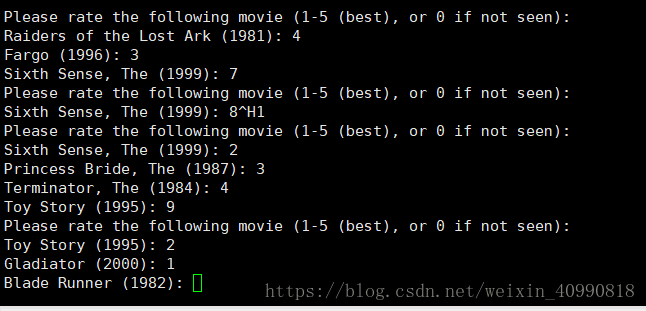
首先随机选出评分密度最密集的10部分电影,对其进行评分:
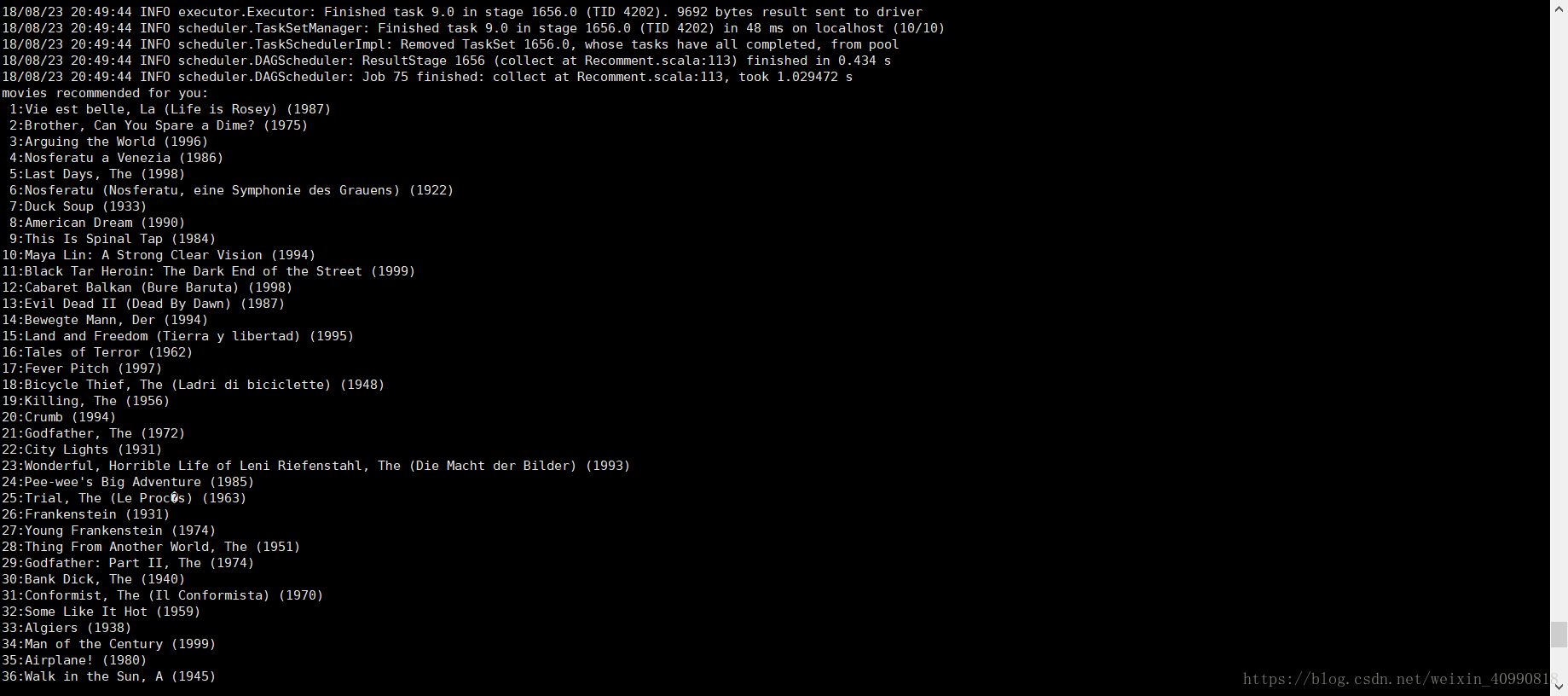
利用矩阵相似度,训练处模型产生由高到底产生50推荐电影:


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)