tensorflow随笔——深度学习中GPU型号对比
深度学习是机器学习的一个分支。深度学习通过深层神经网络自行寻找特征来解决问题,不同于传统方法需要告诉算法找什么样的特征。为获取数据的本质特征深度神经网络需要处理大量信息,一般有两种处理方式:CPU和GPU先抛出三个问题:1. 为什么深度学习需要使用GPU?2. GPU的哪些性能指标最重要?3. 如何选购GPU? CPU or GPU:CPU是基于延迟优化,更擅长快速获取...
深度学习是机器学习的一个分支。深度学习通过深层神经网络自行寻找特征来解决问题,不同于传统方法需要告诉算法找什么样的特征。为获取数据的本质特征深度神经网络需要处理大量信息,一般有两种处理方式:CPU和GPU
先抛出三个问题:
1. 为什么深度学习需要使用GPU?
2. GPU的哪些性能指标最重要?
3. 如何选购GPU?
CPU or GPU:
CPU是基于延迟优化,更擅长快速获取少量的内存(5×3×7),GPU基于带宽优化,更擅长获取大量的内存(矩阵乘法A×B×C)。所以GPU的处理速度快得益于它可以高效的处理矩阵乘法和卷积,背后的原因是由高带宽的内存、多线程并行下的内存访问隐藏延迟、数量多且速度快的可调整的寄存器和L1缓存三大因素支撑。
下图是处理器内部结构图:
DRAM即动态随机存取存储器,是常见的系统内存。
Cache存储器:电脑中作高速缓冲存储器,是位于CPU和主存储器DRAM之间,规模较小,但速度很高的存储器。
算术逻辑单元ALU是能实现多组算术运算和逻辑运算的组合逻辑电路。

当采用深度学习进行网络训练需要对大数据做同样的事情时,GPU更合适,能够专注于大量并发的浮点数计算。
深度学习相关的GPU性能指标如下:
- 内存带宽:GPU处理大量数据的能力,是最重要的性能指标,指单位时间内数据的吞吐量。
- 处理能力:表示GPU处理数据的速度,可以量化为CUDA核数量和每一个核的频率的乘积。
- 显存大小:一次性加载到显卡上的数据量,运行计算机视觉模型显存越大越好。
Single GPU or Multi GPU:
- 单GPU
- 多GPU一般用于并行训练多个模型或者分布式训练单个模型。分布式训练或在多个显卡上训练单个模型的效率较低,但是此方法越来越受欢迎。主流的深度学习框架Tensorflow、Keras、PyTorch等都开放了分布式训练接口,分布式训练几乎可以随着GPU数量成线性的性能提升,比如两个GPU可以获得1.8倍的训练速度。
- 总而言之,GPU越多需要越快的处理器并需要更快的数据读取能力的硬盘
Nivda or AMD:
英伟达已经关注深度学习有一段时间,并取得了领先优势。他们的 CUDA 工具包具备扎实的技术水平,可用于所有主要的深度学习框架——TensorFlow、PyTorch、Caffe、CNTK 等。但截至目前,这些框架都不能在 OpenCL(运行于 AMD GPU)上工作。由于市面上的 AMD GPU 便宜得多,我希望这些框架对 OpenCL 的支持能尽快实现。而且,一些 AMD 卡还支持半精度计算,从而能将性能和显存大小加倍。AMD 发布的 ROCm 平台提供深度学习支持,它同样适用于主流深度学习库(如 PyTorch、TensorFlow、MxNet 和 CNTK)。但是ROCm 仍然在不断开发中,所以优先选择Nivda的显卡。
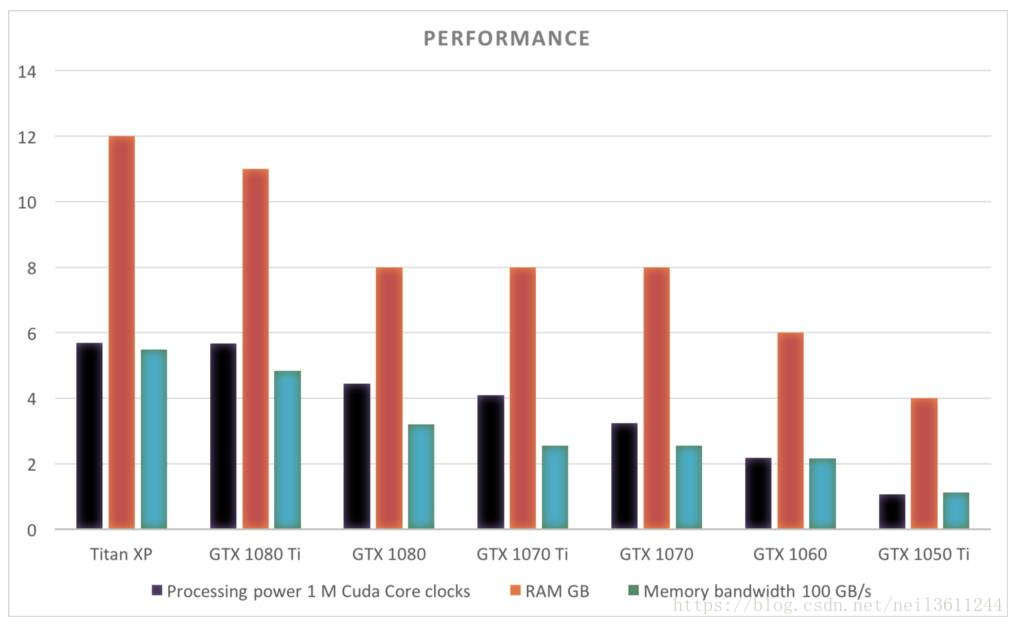
主流GPU的性能比较:
下图展示了每个GPU的RAM或内存带宽信息。
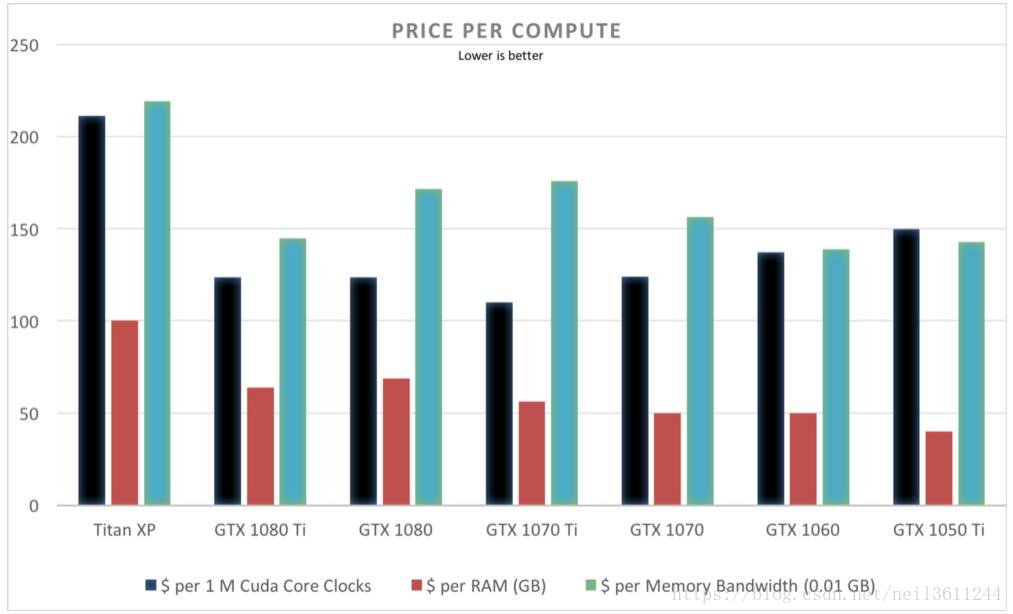
价格对比表明GTX1080Ti、GTX1070和GTX1060的性价比较高:
Titan XP 英伟达消费级显卡的旗舰产品,正如性能指标所述,12GB 的内存宣示着它并不是为大多数人准备的,只有当你知道为什么需要它的时候,它才会位列推荐列表。一块 Titan XP 的价格可以让你买到两块 GTX 1080,而那意味着强大的算力和 16GB 的显存。参数:
- 显存(VRAM):12GB
- 内存带宽:547.7GB/s
- 处理器:3840个CUDA核心@1480MHz
- 官方价格:9700 RMB
GTX 1080 Ti 英伟达产品线里的高端显卡,拥有大容量显存和高吞吐量,GTX 1080 Ti 可以让你完成计算机视觉任务,并在 Kaggle 竞赛中保持强势。参数:
- 显存(VRAM):11GB
- 内存带宽:484GB/s
- 处理器:3584个CUDA核心@1582MHz
- 单精度浮点性能:10.6-11.4TFLOPS
- 官方价格:4600 RMB
GTX 1080 英伟达产品线里的中高端显卡,8 GB 的内存对于计算机视觉任务来说够用了。大多数 Kaggle 上的人都在使用这款显卡。 参数:
- 显存(VRAM):8GB
- 内存带宽:320GB/s
- 处理器:2560个CUDA核心@1733MHz
- 单精度浮点性能:8.2-8.9TFLOPS
- 官方价格:3600 RMB
GTX 1070 Ti 可以为你提供同样大的 8 GB 显存,以及大约 80% 的性能。参数:
- 显存(VRAM):8GB
- 内存带宽:256GB/s
- 处理器:2432个CUDA核心@1683MHz
- 单精度浮点性能:7.8-8.2TFLOPS
- 官方价格:3000 RMB
GTX 1070 主要用于虚拟货币挖矿。它的显存配得上这个价位,就是速度有些慢。参数:
- 显存(VRAM):8GB
- 内存带宽:256GB/s
- 处理器:1920个CUDA核心@1683MHz
- 单精度浮点性能:5.8-6.5TFLOPS
- 官方价格:2700 RMB
GTX 1060 相对来说比较便宜,但是 6 GB 显存对于深度学习任务可能不够用。如果你要做计算机视觉,那么这可能是最低配置。如果做 NLP 和分类数据模型,这款还可以。参数:
- 显存(VRAM):6GB
- 内存带宽:216GB/s
- 处理器:1280个CUDA核心@1708MHz
- 官方价格:2000 RMB
GTX 1050 Ti 一款入门级 GPU。如果你不确定是否要做深度学习,那么选择这款不用花费太多钱就可以体验一下。参数:
- 显存(VRAM):4GB
- 内存带宽:112GB/s
- 处理器:768个CUDA核心@1392MHz
- 官方价格:1060 RMB
备注:一个TFLOPS(teraFLOPS)等於每秒万亿(=10^12)次的浮点运算。
Nivda面向专业市场的Tesla GPU产品型号包括K40、K80、P100等,经过前人针对 GTX 1080 Ti 和 K40 的一些基准测试。1080Ti 的速度是 K40 的 5 倍,是 K80 的 2.5 倍。K40 有 12 GB 显存,K80 有 24 GB 的显存。P100 和 GTX 1080 Ti 应该性能差不多。但是性价比落后于桌面级 GPU故暂不推荐。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)