
聚簇索引和非聚簇索引的区别
参考链接:和刚入门的菜鸟们聊聊--什么是聚簇索引与非聚簇索引 MYSQL索引:对聚簇索引和非聚簇索引的认识一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。因此,MYSQL中不同的数据存储引擎对聚...
参考链接:和刚入门的菜鸟们聊聊--什么是聚簇索引与非聚簇索引 MYSQL索引:对聚簇索引和非聚簇索引的认识
一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引。
在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
因此,MYSQL中不同的数据存储引擎对聚簇索引的支持不同就很好解释了。
下面,我们可以看一下MYSQL中MYISAM和INNODB两种引擎的索引结构。
如原始数据为:
MyISAM引擎的数据存储方式如图:
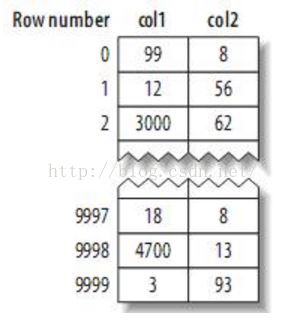
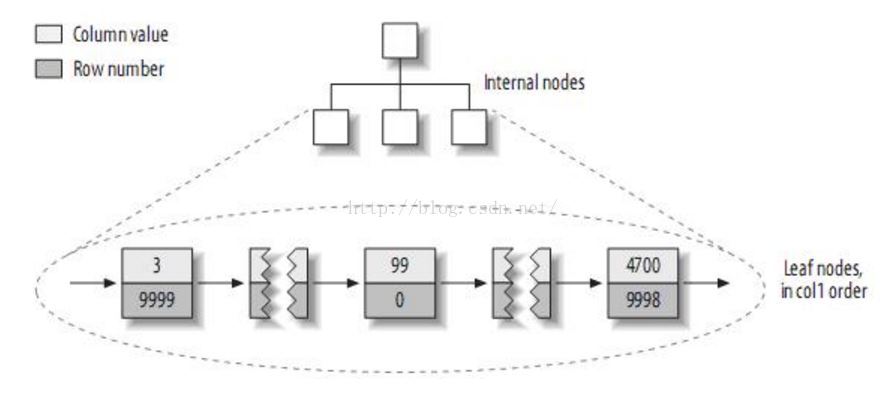
MYISAM是按列值与行号来组织索引的。它的叶子节点中保存的实际上是指向存放数据的物理块的指针。
从MYISAM存储的物理文件我们能看出,MYISAM引擎的索引文件(.MYI)和数据文件(.MYD)是相互独立的。
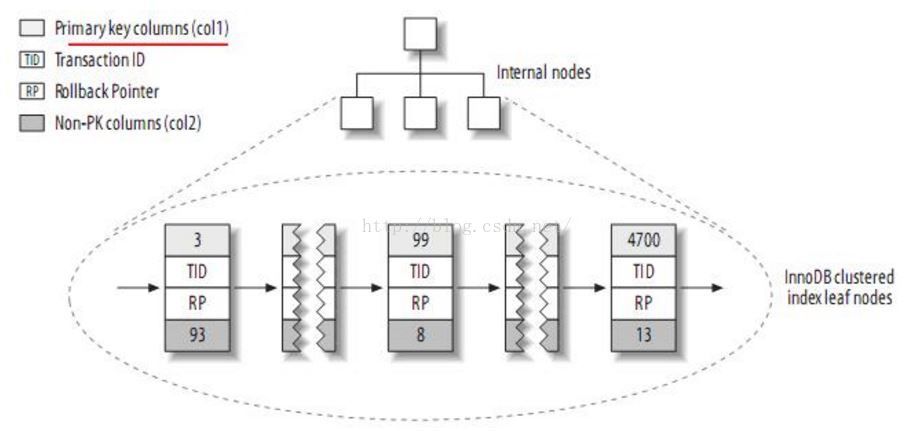
而InnoDB按聚簇索引的形式存储数据,所以它的数据布局有着很大的不同。它存储数据的结构大致如下:
注:聚簇索引中的每个叶子节点包含主键值、事务ID、回滚指针(rollback pointer用于事务和MVCC)和余下的列(如col2)。
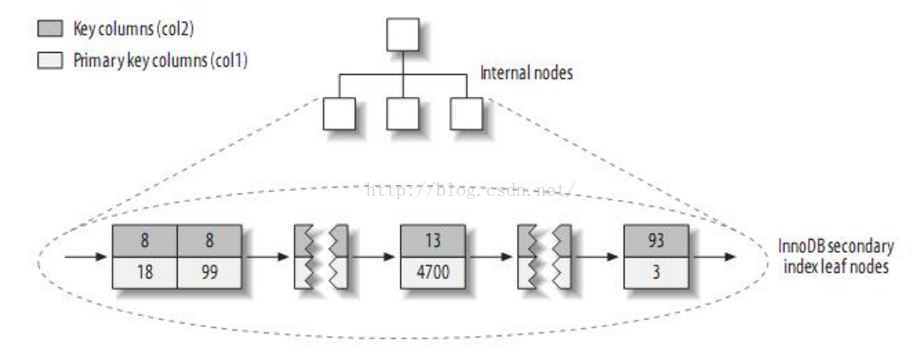
INNODB的二级索引与主键索引有很大的不同。InnoDB的二级索引的叶子包含主键值,而不是行指针(row pointers),这减小了移动数据或者数据页面分裂时维护二级索引的开销,因为InnoDB不需要更新索引的行指针。其结构大致如下:
INNODB和MYISAM的主键索引与二级索引的对比:
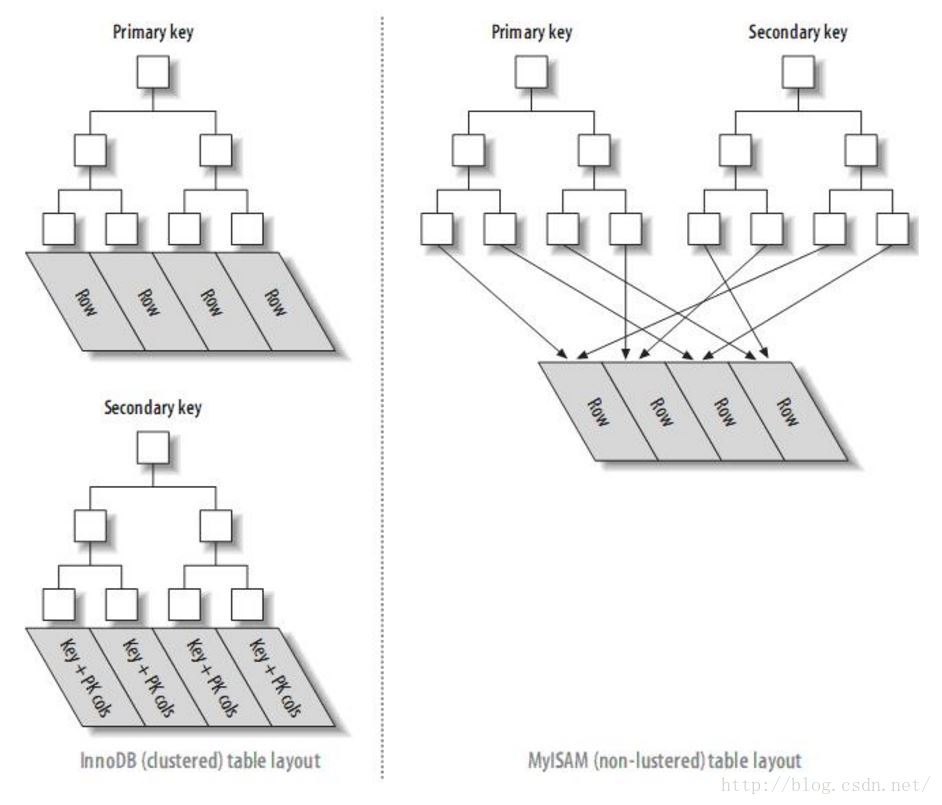
InnoDB的的二级索引的叶子节点存放的是KEY字段加主键值。因此,通过二级索引查询首先查到是主键值,然后InnoDB再根据查到的主键值通过主键索引找到相应的数据块。而MyISAM的二级索引叶子节点存放的还是列值与行号的组合,叶子节点中保存的是数据的物理地址。所以可以看出MYISAM的主键索引和二级索引没有任何区别,主键索引仅仅只是一个叫做PRIMARY的唯一、非空的索引,且MYISAM引擎中可以不设主键。
【聚簇索引】
平时习惯逛图书馆的童鞋可能比较清楚,如果你要去图书馆借一本书,最开始是去电脑里面查书名然后根据书名来定位藏书在那个区,哪个书柜,哪一行,第多少本。。。清晰明确,一目了然,因为藏书的结构与图书室的位置,书架的顺序,书本的摆放顺序与书籍的编号都是从大到小一致的顺序摆放的,所以很容易找到。比如,你的目标藏书在C区2柜3排5仓,那么你走到B区你就很快知道前面就快到了C区了,你直接奔着2柜区就能找到了。 这就是雷同于聚簇索引的功效了,聚簇索引,实际存储的循序结构与数据存储的物理机构是一致的,所以通常来说物理顺序结构只有一种,那么一个表的聚簇索引也只能有一个,通常默认都是主键,设置了主键,系统默认就为你加上了聚簇索引,当然有人说我不想拿主键作为聚簇索引,我需要用其他字段作为索引,当然这也是可以的,这就需要你在设置主键之前自己手动的先添加上唯一的聚簇索引,然后再设置主键,这样就木有问题啦。
总而言之,聚簇索引是顺序结构与数据存储物理结构一致的一种索引,并且一个表的聚簇索引只能有唯一的一条;
【非聚簇索引】
同样的,如果你去的不是图书馆,而是某城市的商业性质的图书城,那么你想找的书就摆放比较随意了,由于商业图书城空间比较紧正,藏书通常按照藏书上架的先后顺序来摆放的,所以如果查询到某书籍放在C区2柜3排5仓,但你可能要绕过F区,而不是A.B.C.D...连贯一致的,也可能同在C区的2柜,书柜上第一排是计算机类的书记,也可能最后一排就是医学类书籍;
那么对照着来看非聚簇索引的概念就比较好理解了,非聚簇索引记录的物理顺序与逻辑顺序没有必然的联系,与数据的存储物理结构没有关系;一个表对应的非聚簇索引可以有多条,根据不同列的约束可以建立不同要求的非聚簇索引;
动手试试:看看代码怎么敲的
建立索引之前选好表对象,假设表明为IndexTestTable此表中包含三个字段Id,Name,UniqueCode
为了更快的进行姓名查询,我们可以在Name字段上添加非聚簇索引;
创建索引的格式如下:
CREATE NONCLUSTERED INDEX [index_name【索引名称】] ON [table_name【表名称】]([column_name1【列名称】],[column_name2【列名称】],...);
我们给IndexTestTable表的Name字段添加一个非聚簇索引:
CREATE NONCLUSTERED INDEX IndexTestTable_index_name ON IndexTestTable(Name);给IndexTestTable表的UniqueCode字段添加一个聚簇索引:
CREATE CLUSTERED INDEX IndexTestTable_index_uniquecode ON IndexTestTable(UniqueCode)以上的代码是最简单最直接设置索引的方式,而通常实际应用中,会有多字段联合添加索引的情况,这个就需要你根据实际的应用查询场景,以及在where条件下最常用的查询字段,例如:在 TableX中你最经常查询的条件为:
SELECT Name,Message
FROM TableX
WHERE 1=1
AND DeptId='003523'
AND LimitedCondition='SomeValue'
这个时候你就可以 添加一个基于 DeptId 和 LimitedCondition 两个字段的非聚簇索引,以便于加速查询速度;
CREATE NONCLUSTERED INDEX TableX_index_departid_limitedcondition
ON TableX(DeptId,LimitedCondition);
简言之,就是需要根据你的实际应用场景,添加有用并且高效的索引;

快速构建 Web 应用程序
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)