[深度学习] 池化层
转载自:https://blog.csdn.net/l691899397/article/details/52250190池化层的输入一般来源于上一个卷积层,主要的作用是提供了很强的鲁棒性。(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反..
转载自:https://blog.csdn.net/l691899397/article/details/52250190
池化层的输入一般来源于上一个卷积层,主要的作用是提供了很强的鲁棒性。(例如max-pooling是取一小块区域中的最大值,此时若此区域中的其他值略有变化,或者图像稍有平移,pooling后的结果仍不变),并且减少了参数的数量,防止过拟合现象的发生。池化层一般没有参数,所以反向传播的时候,只需对输入参数求导,不需要进行权值更新。
卷积层的前向传播
前向计算过程中,我们对卷积层输出map的每个不重叠(有时也可以使用重叠的区域进行池化)的n*n区域(我这里为2*2,其他大小的pooling过程类似)进行降采样,选取每个区域中的最大值(max-pooling)或是平均值(mean-pooling),也有最小值的降采样,计算过程和最大值的计算类似。

上图中,池化层1的输入为卷积层1的输出,大小为24*24,对每个不重叠的2*2的区域进行降采样。对于max-pooling,选出每个区域中的最大值作为输出。而对于mean-pooling,需计算每个区域的平均值作为输出。最终,该层输出一个(24/2)*(24/2)的map。池化层2的计算过程也类似。
下面用图示来看一下2种不同的pooling过程。
max-pooling

mean-pooling

池化的反向传播
在池化层进行反向传播时,max-pooling和mean-pooling的方式也采用不同的方式。
对于max-pooling,在前向计算时,是选取的每个2*2区域中的最大值,这里需要记录下最大值在每个小区域中的位置。在反向传播时,只有那个最大值对下一层有贡献,所以将残差传递到该最大值的位置,区域内其他2*2-1=3个位置置零。具体过程如下图,其中4*4矩阵中非零的位置即为前边计算出来的每个小区域的最大值的位置。
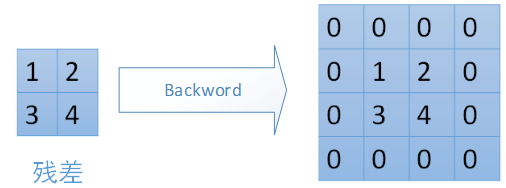
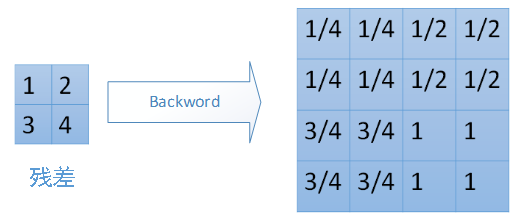
对于mean-pooling,我们需要把残差平均分成2*2=4份,传递到前边小区域的4个单元即可。具体过程如图:

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)