hanlp中文自然语言处理分词方法介绍
自然语言处理在大数据以及近年来大火的人工智能方面都有着非同寻常的意义。那么,什么是自然语言处理呢?在没有接触到大数据这方面的时候,也只是以前在学习计算机方面知识时听说过自然语言处理。书本上对于自然语言处理的定义或者是描述太多专业化。换一个通俗的说法,自然语言处理就是把我们人类的语言通过一些方式或者技术翻译成机器可以读懂的语言。人类的语言太多,计算机技术起源于外国,所以一直以来自然语言处理基本都是围
自然语言处理在大数据以及近年来大火的人工智能方面都有着非同寻常的意义。那么,什么是自然语言处理呢?在没有接触到大数据这方面的时候,也只是以前在学习计算机方面知识时听说过自然语言处理。书本上对于自然语言处理的定义或者是描述太多专业化。换一个通俗的说法,自然语言处理就是把我们人类的语言通过一些方式或者技术翻译成机器可以读懂的语言。
人类的语言太多,计算机技术起源于外国,所以一直以来自然语言处理基本都是围绕英语的。中文自然语言处理当然就是将我们的中文翻译成机器可以识别读懂的指令。中文的博大精深相信每一个人都是非常清楚,也正是这种博大精深的特性,在将中文翻译成机器指令时难度还是相当大的!至少在很长一段时间里中文自然语言的处理都面临这样的问题。
Hanlp中文自然语言处理相信很多从事程序开发的朋友都应该知道或者是比较熟悉的。Hanlp中文自然语言处理是大快搜索在主持开发的,是大快DKhadoop大数据一体化开发框架中的重要组成部分。下面就hanlp中文自然语言处理分词方法做简单介绍。
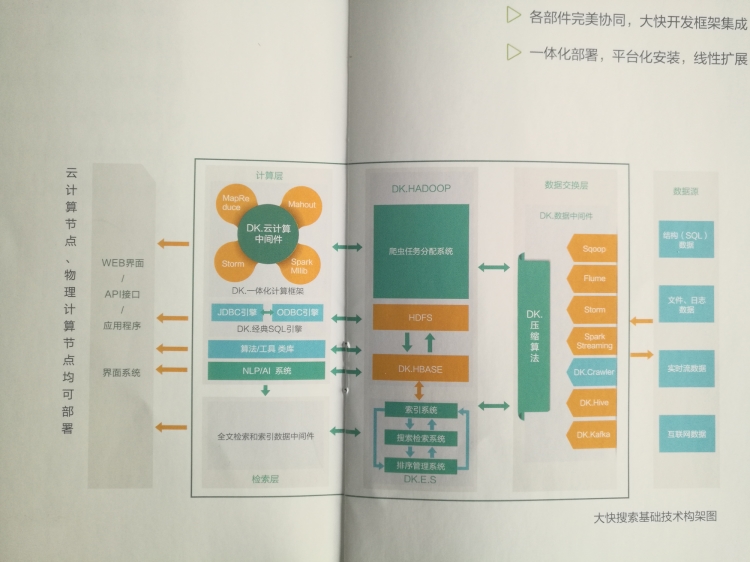
Hanlp中文自然语言处理中的分词方法有标准分词、NLP分词、索引分词、N-最短路径分词、CRF分词以及极速词典分词等。下面就这几种分词方法进行说明。
标准分词:

Hanlp中有一系列“开箱即用”的静态分词器,以Tokenizer结尾。HanLP.segment其实是对StandardTokenizer.segment的包装
NLP分词:
1. List<Term> termList = NLPTokenizer.segment("中国科学院计算技术研究所的宗成庆教授正在教授自然语言处理课程");
2. System.out.println(termList);
NLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
索引分词:

索引分词IndexTokenizer是面向搜索引擎的分词器,能够对长词全切分,另外通过term.offset可以获取单词在文本中的偏移量。
N-最短路劲分词

N最短路分词器NShortSegment比最短路分词器慢,但是效果稍微好一些,对命名实体识别能力更强。
一般场景下最短路分词的精度已经足够,而且速度比N最短路分词器快几倍,请酌情选择。
CRF分词:

CRF对新词有很好的识别能力,但是无法利用自定义词典。
极速词典分词:
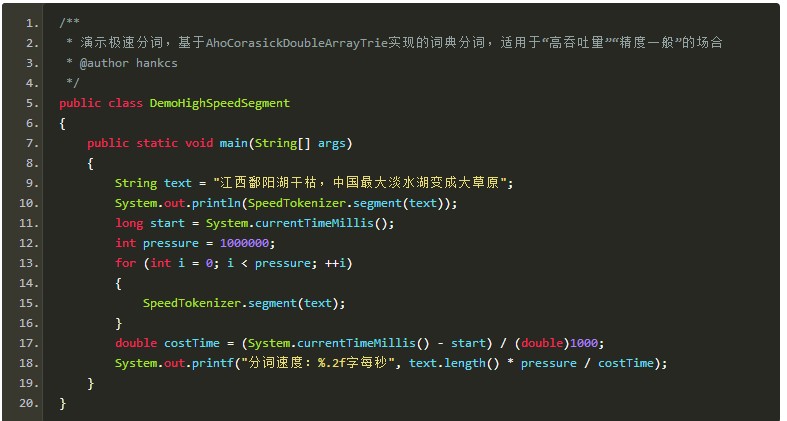
极速分词是词典最长分词,速度极其快,精度一般。
在i7上跑出了2000万字每秒的速度。
上述信息整编的并不是很全面,以后在做补充!

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)