深度学习系列之Focal Loss个人总结
1. Introductionobject detection按其流程来说,一般分为两大类。一类是two stage detector(如非常经典的Faster R-CNN),另一类则是one stage detector(如SSD、YOLO系列)。虽然one stage detector检测速度可以完爆two stage,但是mAP却干不过two stage。So,Why?the...
1. Introduction
object detection按其流程来说,一般分为两大类。一类是two stage detector(如非常经典的Faster R-CNN),另一类则是one stage detector(如SSD、YOLO系列)。
虽然one stage detector检测速度可以完爆two stage,但是mAP却干不过two stage。
So,Why?
the Reason is:Class Imbalance(正负样本不平衡)
one stage detector evaluate 10^4 - 10^5 candidate locations per image, but only a few locations contain objects.
这带来的问题就是:样本中会存在大量的easy examples,且都是负样本(属于背景的样本)。这样,en masse(这个词不错,以前在经济学人里学过)easy negative examples会对loss起主要贡献作用,会主导梯度的更新方向。
这样,网络学不到有用的信息,无法对object进行准确分类。
还有一个问题,为什么two stage不会有这样的问题呢或者为什么two stage没有one stage这么严重呢?
因为,对于two stage来说,首先利用RPN产生region proposal,这一步就已经删去了很多easy examples。我们对这些region proposal进行筛选,可以人为控制正负样本的比例为1:3.
此外,对于负样本的选取,可以通过在线难例挖掘,选取有利于网络更新的难分样本,让网络学习到有用的信息,进行参数的更新。
因此,one stage在检测mAP上不如two stage。
2. Focal Loss
如下是未变化前的交叉熵(cross entropy) loss,以二分类为例:

为了便于表示,做如下变换:

最终形式为:

通过实验发现,即使是easy examples(Pt >> 0.5),它的loss也很高,如下图蓝线
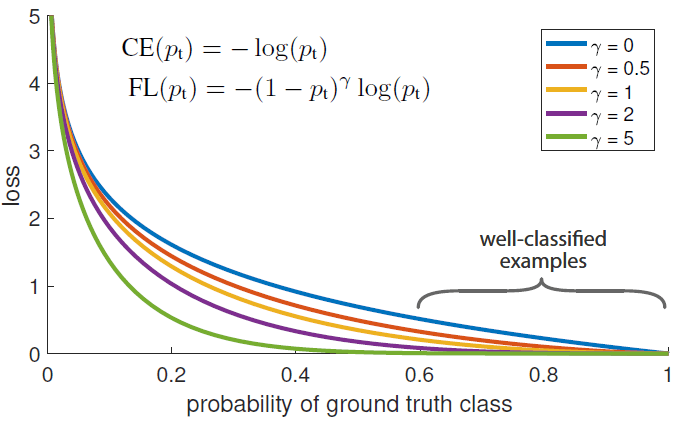
因此,对于大量的easy negative examples,这些loss会主导梯度下降的方向,淹没少量的正样本的影响。
so,我们要降低easy examples的影响。

我们为交叉熵叫一个权重,其中权重因子的大小一般为相反类的比重。即负样本不是多吗,它越多,我们给它的权重越小。这样就可以降低负样本的影响。
这只是解决了正负样本的不平衡,但是并没有解决easy和hard examples之间的不平衡。
因此,针对easy和hard 样本,我们定义Focal loss:

其中,gamma range from 0 to 5.
这样,当对于简单样本,Pt会比较大,所以权重自然减小了。针对hard example,Pt比较小,则权重比较大,让网络倾向于利用这样的样本来进行参数的更新。
且这个权重是动态变化的,如果复杂的样本逐渐变得好分,则它的影响也会逐渐的下降。
最终,我们把这两种单独的改进进行合并,最终Focal Loss的形式为:

既做到了解决正负样本不平衡,也做到了解决easy与hard样本不平衡的问题。
3. Conclusion
Focal loss让one stage detecor也变的牛逼起来,解决了class imbalance的问题。根据我的解读,是同时解决了正负样本不平衡以及区分简单与复杂样本的问题。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)