
ELK(ElasticSearch, Logstash, Kibana)日志环境搭建(一)
一、背景简述 为避免在查询日志时,还是采用依次登录每台机器去查阅日志,这种繁琐,低效率的方式,为此采用业界成熟的解决方案,基于支付平台,搭建一套ELK日志系统。进而实现对业务日志的志集中化管理、统计和检索。二、技术背景1、概述 ELK是一组开源软件的简称,其主要包括Elasticsearch、Logstash 和 Kibana,成为目前流行的集中式日志解决方案之一。Elastic
一、背景简述
为避免在查询日志时,还是采用依次登录每台机器去查阅日志,这种繁琐,低效率的方式,为此采用业界成熟的解决方案,基于支付平台,搭建一套ELK日志系统。进而实现对业务日志的志集中化管理、统计和检索。
二、技术背景
1、概述
ELK是一组开源软件的简称,其主要包括Elasticsearch、Logstash 和 Kibana,成为目前流行的集中式日志解决方案之一。
Elasticsearch: 是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。能对大容量的数据进行接近实时的存储,搜索和分析操作。
Logstash: LogStash由JRuby语言编写,基于消息(message-based)的简单架构,并运行在Java虚拟机(JVM)上。不同于分离的代理端(agent)或主机端(server),LogStash可配置单一的代理端(agent)与其它开源软件结合,以实现不同的功能。当用来数据收集引擎,它支持动态的的从各种数据源获取数据,并对数据进行过滤,分析,丰富,统一格式等操作,然后存储到用户指定的位置。
Kibana: Logstash是一个完全开源的工具,他可以对你的日志进行收集、分析,并将其存储供以后使用(如,搜索),您可以使用它。说到搜索,logstash带有一个web界面,搜索和展示所有日志。
Filebeat: 轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给Elasticsearch存储。
2、ELK第一阶段架构图

2.1架构图解读
数据源Datasource把数据写到input插件中,output插件使用消息队列把消息写入到消息队列Message Queue(Logstash 可以整合多个第三方队列,比如 Redis, Kafka 或 RabbitMQ),Logstash indexing Instance启动logstash使用input插件读取消息队列中的信息,Fliter插件过滤后在使用output写入到elasticsearch中。
如果生产环境中不适用正则grok匹配,可以写Python脚本从消息队列中读取信息,输出到elasticsearch中
2.2 该架构的优点
A)解耦,松耦合
B)解除了由于网络原因不能直接连elasticsearch的情况
C)方便架构演变,增加新内容
D)消息队列可以使用rabbitmq,zeromq等,也可以使用redis,kafka(消息不删除,但是比较重量级)等
3、ELK第二阶段架构图
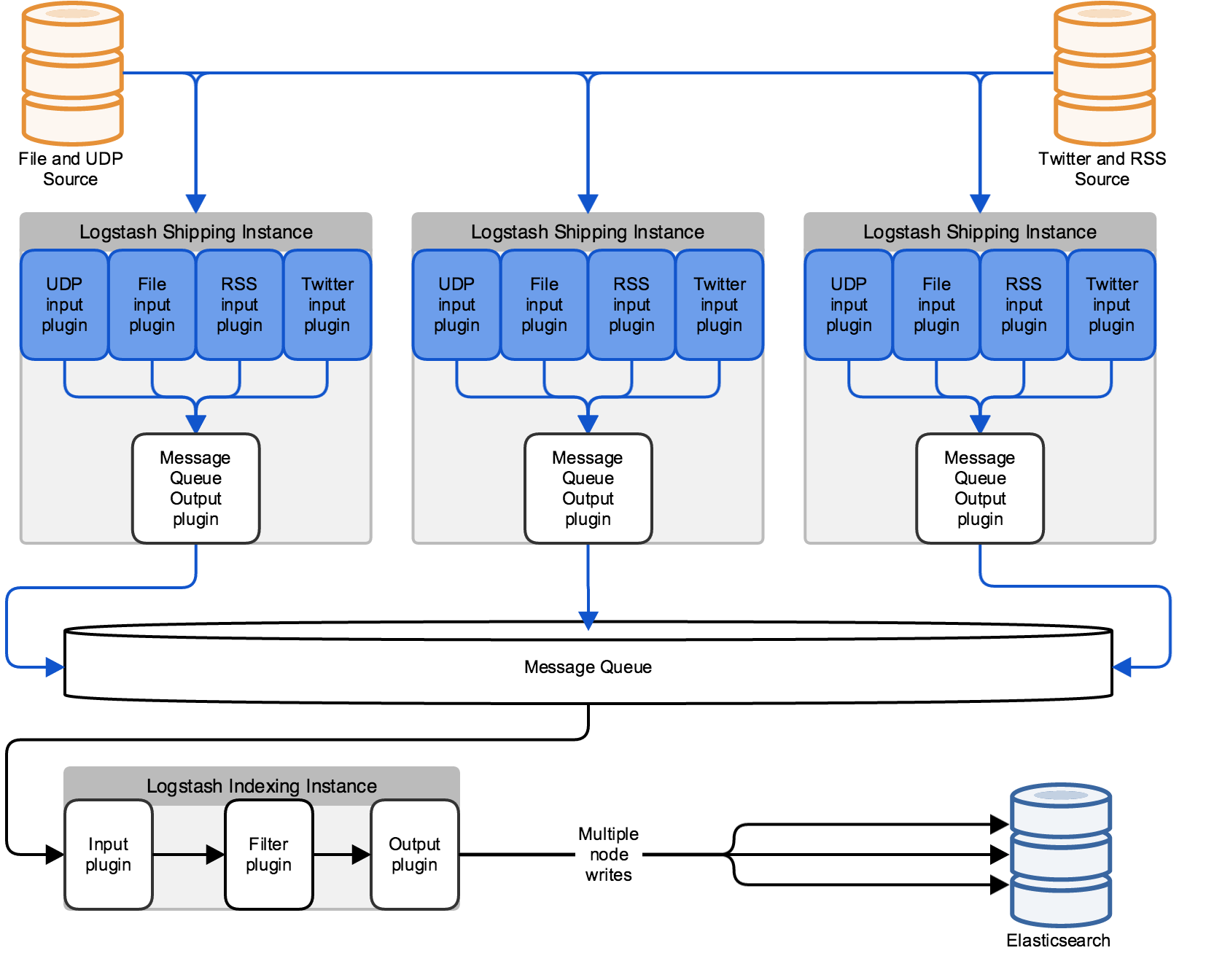
3.1架构图解读
为了使的Logstash 部署对单个实例失败更具弹性, 可以在数据源机器和 Logstash 集群之间建立一个负载平衡器。负载平衡器处理与 Logstash 实例的单独连接, 以确保数据摄入和处理的连续性, 即使个别实例不可用。
4、ELK第三阶段架构图

4.1架构图解读
在第二阶段的基础上,可以拓展出 HDFS\STORM
A) 日志文件可以写入HDFS,用于数据分析
1、其中HDFS数据可以直接映射到HIVE,数据本身存储在HDFS
2、定时对HIVE进行分析处理,将分析结果存储在HIVE表中
3、通过hodoop传输工具(sqoop)把增量或变更的数据同步至数据库
B) 日志文件可以写入STORM,用于数据异常实时告警
参考官网:https://www.elastic.co/cn/products

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)