
《TCP/IP详解 卷2》 笔记: mbuf结构体
在BSD TCP/IP协议栈代码设计中的一个基本概念就是存储器缓存,称作一个mbuf,用于存储各种信息。mbuf的主要用途是保存在进程和网络接口间互相传递的用户数据。但mbuf也用于保存其他各种数据:源与目标地址、插口选项等等。mbuf相当于Linux内核中的skb。/* header at beginning of each mbuf: */struct m_hdr {structmbu...
在BSD TCP/IP协议栈代码设计中的一个基本概念就是存储器缓存,称作一个mbuf,用于存储各种信息。mbuf的主要用途是保存在进程和网络接口间互相传递的用户数据。但mbuf也用于保存其他各种数据:源与目标地址、插口选项等等。mbuf相当于Linux内核中的skb。
/* header at beginning of each mbuf: */
struct m_hdr {
struct mbuf *mh_next; /* next buffer in chain */
struct mbuf *mh_nextpkt; /* next chain in queue/record */
int mh_len; /* amount of data in this mbuf */
caddr_t mh_data; /* location of data */
short mh_type; /* type of data in this mbuf */
short mh_flags; /* flags; see below */
};
/* record/packet header in first mbuf of chain; valid if M_PKTHDR set */
struct pkthdr {
int len; /* total packet length */
struct ifnet *rcvif; /* rcv interface */
};
/* description of external storage mapped into mbuf, valid if M_EXT set */
struct m_ext {
caddr_t ext_buf; /* start of buffer */
void (*ext_free)(); /* free routine if not the usual */
u_int ext_size; /* size of buffer, for ext_free */
};
struct mbuf {
struct m_hdr m_hdr;
union {
struct {
struct pkthdr MH_pkthdr; /* M_PKTHDR set */
union {
struct m_ext MH_ext; /* M_EXT set */
char MH_databuf[MHLEN];
} MH_dat;
} MH;
char M_databuf[MLEN]; /* !M_PKTHDR, !M_EXT */
} M_dat;
};每个mbuf结构都包含数据部分和一个m_hdr结构的首部,m_hdr结构中的mh_next成员指向该mbuf链中的下一个mbuf,mh_nextpkt成员指向(该队列中)下一个mbuf链。
mh_type表示mbuf的类型,有几个常见的值:MT_DATA表示动态分配的普通数据。MT_HEADER表示分组首部,此时mbuf中包含pkthdr结构,并且成员mh_flags置上M_PKTHDR标志。MT_SONAME表示插口名称,此时数据中存放的是sockaddr_in结构。
mh_flags表示mbuf的标志,有两个常见的值:M_EXT表示此mubf带有簇(外部缓存)。M_PKTHDR表示该mbuf是一个分组首部。
根据mh_flags的值不同,有如下四种mbuf:

针对不同类型的mbuf可存储的数据量有如下宏定义:
/*每个mbuf的大小*/
#define MSIZE 128
/*一个mbuf簇(外部缓存)的大小*/
#define MCLBYTES 2048
/*108,正常mbuf中的最大数据量*/
#define MLEN (MSIZE - sizeof(struct m_hdr))
/*100,带分组首部的mbuf的最大数据量*/
#define MHLEN (MLEN - sizeof(struct pkthdr))
/*208,存储到簇中的最小数据量*/
#define MINCLSIZE (MHLEN + MLEN)如下定义的宏和函数可用来分配和释放mbuf:
/*分配一个mbuf*/
#define MGET(m, how, type) { \
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \
if (m) { \
(m)->m_type = (type); \
MBUFLOCK(mbstat.m_mtypes[type]++;) \
(m)->m_next = (struct mbuf *)NULL; \
(m)->m_nextpkt = (struct mbuf *)NULL; \
(m)->m_data = (m)->m_dat; \
(m)->m_flags = 0; \
} else \
(m) = m_retry((how), (type)); \
}
/*分配一个mbuf,并把它初始化为一个分组首部*/
#define MGETHDR(m, how, type) { \
MALLOC((m), struct mbuf *, MSIZE, mbtypes[type], (how)); \
if (m) { \
(m)->m_type = (type); \
MBUFLOCK(mbstat.m_mtypes[type]++;) \
(m)->m_next = (struct mbuf *)NULL; \
(m)->m_nextpkt = (struct mbuf *)NULL; \
(m)->m_data = (m)->m_pktdat; \
(m)->m_flags = M_PKTHDR; \
} else \
(m) = m_retryhdr((how), (type)); \
}
/*分配一个簇并将m指向的mbuf中的数据指针(m_data)设置为指向这个簇*/
#define MCLGET(m, how) \
{ MCLALLOC((m)->m_ext.ext_buf, (how)); \
if ((m)->m_ext.ext_buf != NULL) { \
(m)->m_data = (m)->m_ext.ext_buf; \
(m)->m_flags |= M_EXT; \
(m)->m_ext.ext_size = MCLBYTES; \
} \
}
/*释放一个mbuf*/
#define MFREE(m, nn) \
{ MBUFLOCK(mbstat.m_mtypes[(m)->m_type]--;) \
if ((m)->m_flags & M_EXT) { \
MCLFREE((m)->m_ext.ext_buf); \
} \
(nn) = (m)->m_next; \
FREE((m), mbtypes[(m)->m_type]); \
}
/*分配一个mbuf,把108字节的缓存清零*/
struct mbuf* m_getclr(int nowait,int type);
/*分配一个mbuf,并把它初始化为一个分组首部*/
struct mbuf* m_gethdr(intnowait,inttype);
/*分配一个mbuf*/
struct mbuf* m_get(int nowait,int type);
/*释放mbuf*/
struct mbuf* m_free(struct mbuf *m);
/*释放m指向的mbuf链中的所有mbuf*/
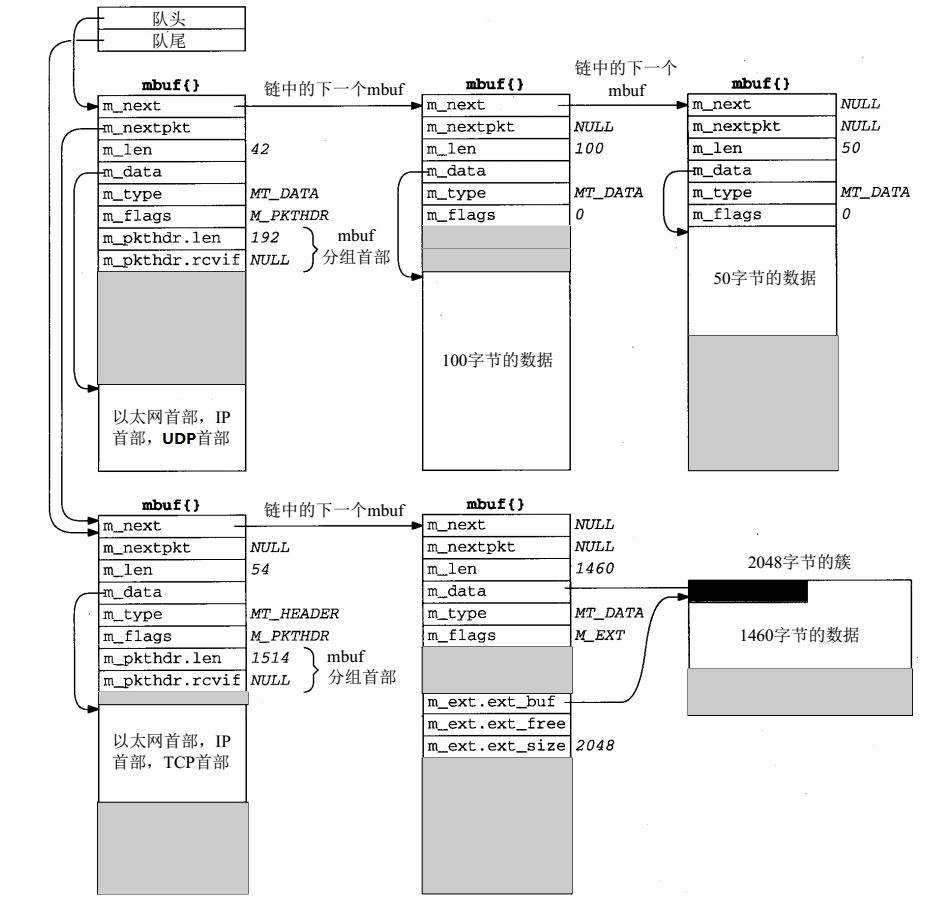
void m_freem(register struct mbuf *m);下图显示的是在接口输出队列中的两个分组:第一个带有192字节数据,第二个带有1514字节数据:
有如下宏和函数来操作mbuf中的数据:
/*设置一个包含分组首部的mbuf的m_data,在这个数据区的尾部为一个长度
为len字节的对象提供空间。这个数据指针是长字对齐方式。*/
#define MH_ALIGN(m, len) \
{ (m)->m_data += (MHLEN - (len)) &~ (sizeof(long) - 1); }
/*在m指向的mbuf中的数据的前面添加len字节的数据。如果mbuf有空间,则仅把指针(m_data)
减len字节,并将长度(m_len)增加len字节。如果没有足够的空间,就分配一个新的mbuf,它的
m_next指针被设置为m,数据放置到这个新mbuf的尾部(例如,调用MH_ALIGN)。如果一个新mbuf
被分配,并且原来的mbuf的分组首部标志被设置,则分组首部从老mbuf中移到新mbuf中*/
#define M_PREPEND(m,plen,how){\
if(M_LEADINGSPACE(m)>=(plen)){\
(m)->m_data-=(plen);\
(m)->m_len+=(plen);\
}else\
(m)=m_prepend((m),(plen),(how));\
if((m)&&(m)->m_flags&M_PKTHDR)\
(m)->m_pkthdr.len+=(plen);\
}
/*将m指向的mbuf的数据区指针的类型转换成type类型*/
#define mtod(m,t) ((t)((m)->m_data))
/*将指向一个mbuf数据区中某个位置的指针x转换成一个指向这个mbuf的起始的指针*/
#define dtom(x) ((struct mbuf *)((int)(x) & ~(MSIZE-1)))
/*从m指向的mbuf链中首部或尾部移走req_len字节的数据*/
void m_adj(struct mbuf *m, int req_len);
/*把由n指向的mbuf链表链接到由m指向的mbuf链表的尾部*/
void m_cat(register struct mbuf *m, register struct mbuf *n);
/*从m指向的mbuf链表数据区起始的offset字节开始复制len字节数据到cp指向的缓存*/
void m_copydata(register struct mbuf *m, register int off, register int len, caddr_t cp);
/*从cp指向的缓存中复制len字节数据到由m0指向的mbuf链数据区起始的offset字节后*/
void m_copyback(struct mbuf *m0, register int off, register int len, caddr_t cp);
#define m_copy(m,o,l) m_copym((m),(o),(l),M_DONTWAIT)
/*创建一个新的mbuf链表,并从m指向的mbuf链表数据区起始的off0字节处开始复制
len字节数据到这个新的mbuf链的数据区*/
struct mbuf* m_copym(register struct mbuf *m, int off0, register int len, int wait);
/*创建一个带分组首部的mbuf链表,并返回指向这个链表的指针。这个分组首部的len和
rcvif字段被设置为totlen和ifp。调用函数copy从设备接口(由buf指向)将数据复制到mbuf中。
如果copy是一个空指针,调用函数bcopy。*/
struct mbuf* m_devget(char *buf, int totlen, int off0, struct ifnet *ifp, void(*copy)());
/*重新安排mbuf链表,使得前len字节数据被连续地存放在链表第一个mbuf中*/
struct mbuf* m_pullup(register struct mbuf *m,int len);
更多推荐



 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)