
Toward Multimodal Image-to-Image Translation(BicycleGAN)图像一对多转换测试
CycleGAN、pix2pix、iGAN的主要贡献者最近在NIPS 2017上又推出了一篇文章Toward Multimodal Image-to-Image Translation(见https://junyanz.github.io/BicycleGAN/,https://arxiv.org/pdf/1711.11586.pdf),讨论如何从一张图像同时转换为多张风格不一成对的图像。
CycleGAN、pix2pix、iGAN的主要贡献者最近在NIPS 2017上又推出了一篇文章Toward Multimodal Image-to-Image Translation(见https://junyanz.github.io/BicycleGAN/,https://arxiv.org/pdf/1711.11586.pdf),讨论如何从一张图像同时转换为多张风格不一成对的图像。
从作者摘要第一句可以看出:“Many image-to-image translation problems are ambiguous, as a single input image may correspond to multiple possible outputs. In this work, we aim to model a distribution of possible outputs in a conditional generative modeling setting.” 像pix2pix这样的图像转换(一对一)的方式是存在歧义的,因为不可能只对应一个输出。因此作者提出了一种一对多的输出,即将可能输出的图像是存在一定的分布特性的。

论文的主要方法如下图所示,即作者结合了两种GAN来实现。

其原理框图如下所示:
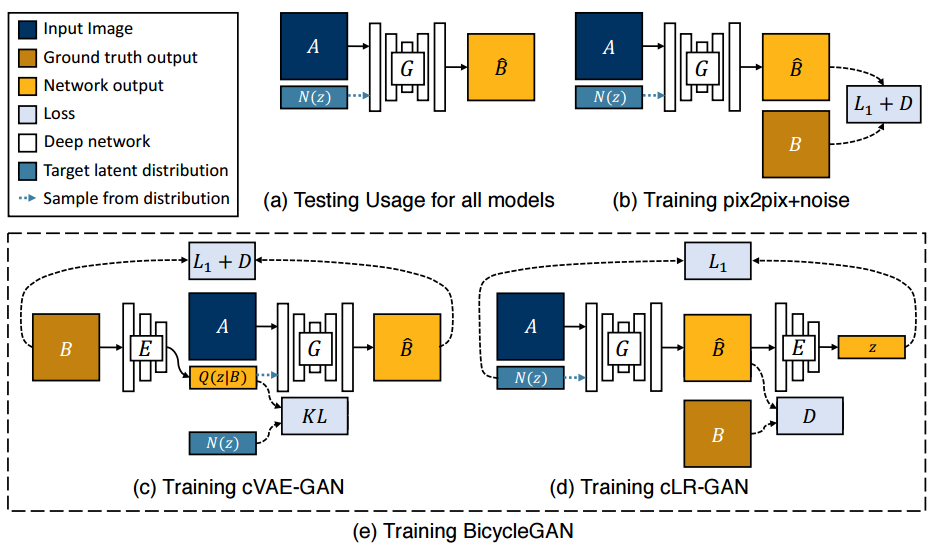
其中cVAE-GAN(条件变分自编码GAN),即通过VAE来学习图像输出的隐分布,进行建模多样式输出分布方法。如上图(C) 所示,cVAE-GAN 首先从ground truth目标图像B开始并将它编码到隐空间中。然后生成器试图将输入图像A连同样本z逆映射到原始图像B。
-
cLR-GAN(条件潜在回归GAN):从随机抽样的隐编码开始,条件生成器应该产生一个输出,当它作为输入给编码器时,它应该返回相同的隐编码,从而实现自我一致性。cLR-GAN从一个已知的分布中随机采样隐编码,利用这个编码将A映射到输出B,然后试图从输出中重建隐编码。
-
那么BicycleGAN就是综合了上面两个模型,得到以下的模型:
-
实验测试(参照https://github.com/junyanz/BicycleGAN/ 公开代码进行重新编译和测试,去掉GPU设置模块,进行测试):

生成结果如下所示,还是相当酷的。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)