Neural Networks API
https://developer.android.com/ndk/guides/neuralnetworks/index.htmlNeural Networks APIIn this documentSHOWMOREUnderstanding the Neural Networks API RuntimeNeural Networks
https://developer.android.com/ndk/guides/neuralnetworks/index.html
Android Neural Networks API (NNAPI)是Android C API, 使用NDK进行编译运行。它设计用于在移动设备上运行机器学习的计算密集型操作。NNAPI旨在为构建和训练神经网络的高级机器学习框架(如TensorFlow Lite,Caffe2或其他)提供基础层功能。NNAPI适用于Android8.1 及以上系统
NNAPI支持在Android 设备上通过使用开发人员之前定义并且训练好的模型进行推理。包括图像分类,预测用户行为等。在设备上推理有如下优点
延迟: 你不需要通过网络连接发送请求并等待响应。这对视频应用从摄像头接受一帧再进行处理是十分关键的。
可用性: 应用可以在没有网络服务的情况下运行。
速度:专门用于神经网络处理的新硬件提供比单独使用通用CPU更快的计算。
隐私性:数据不脱离设备
花费:所有的计算在设备上完成,不需要服务器支持。
同时,开发人员需要权衡和注意:
神经网络运算需要大量的计算,会提升电池的消耗。如果你的APP需要持续的计算,你需要考虑电池的状况。
Model 的大小同样需要注意。有些模型会占用很大的空间,需要考虑安装APP后从云端下载模型。NNAPI不支持在云上运行模型。
NNAPI Runtime
NNAPI旨在被机器学习库,框架和工具所调用,它可以让开发人员将他们的模型脱离设备训练后在Android设备上进行部署。应用程序通常不会直接使用NNAPI,而是直接使用更高级别的机器学习框架。这些框架反过来可以使用NNAPI在受支持的设备上执行硬件加速推理操作。
基于应用程序的需求和设备上的硬件功能,Android的神经网络runtime可以有效地将计算工作量分配到可用的设备上,包括专用的神经网络硬件,图形处理单元(GPU)和数字信号处理器(DSP)
NNAPI Runtime同样可以在CPU上运行优化后的code。下图是NNAPI的high-level的系统架构。
Neural Networks API
The Android Neural Networks API (NNAPI) is an Android C API designed for running computationally intensive operations for machine learning on mobile devices. NNAPI is designed to provide a base layer of functionality for higher-level machine learning frameworks (such as TensorFlow Lite, Caffe2, or others) that build and train neural networks. The API is available on all devices running Android 8.1 (API level 27) or higher.
NNAPI supports inferencing by applying data from Android devices to previously trained, developer-defined models. Examples of inferencing include classifying images, predicting user behavior, and selecting appropriate responses to a search query.
On-device inferencing has many benefits:
- Latency: You don’t need to send a request over a network connection and wait for a response. This can be critical for video applications that process successive frames coming from a camera.
- Availability: The application runs even when outside of network coverage.
- Speed: New hardware specific to neural networks processing provide significantly faster computation than with general-use CPU alone.
- Privacy: The data does not leave the device.
- Cost: No server farm is needed when all the computations are performed on the device.
There are also trade-offs that a developer should keep in mind:
- System utilization: Evaluating neural networks involve a lot of computation, which could increase battery power usage. You should consider monitoring the battery health if this is a concern for your app, especially for long-running computations.
- Application size: Pay attention to the size of your models. Models may take up multiple megabytes of space. If bundling large models in your APK would unduly impact your users, you may want to consider downloading the models after app installation, using smaller models, or running your computations in the cloud. NNAPI does not provide functionality for running models in the cloud.
Understanding the Neural Networks API runtime
NNAPI is meant to be called by machine learning libraries, frameworks, and tools that let developers train their models off-device and deploy them on Android devices. Apps typically would not use NNAPI directly, but would instead directly use higher-level machine learning frameworks. These frameworks in turn could use NNAPI to perform hardware-accelerated inference operations on supported devices.
Based on the app’s requirements and the hardware capabilities on a device, Android’s neural networks runtime can efficiently distribute the computation workload across available on-device processors, including dedicated neural network hardware, graphics processing units (GPUs), and digital signal processors (DSPs).
For devices that lack a specialized vendor driver, the NNAPI runtime relies on optimized code to execute requests on the CPU.
The diagram below shows a high-level system architecture for NNAPI.
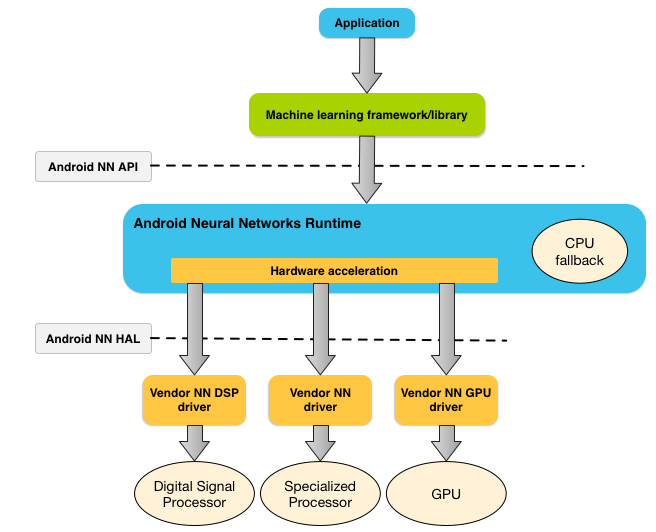
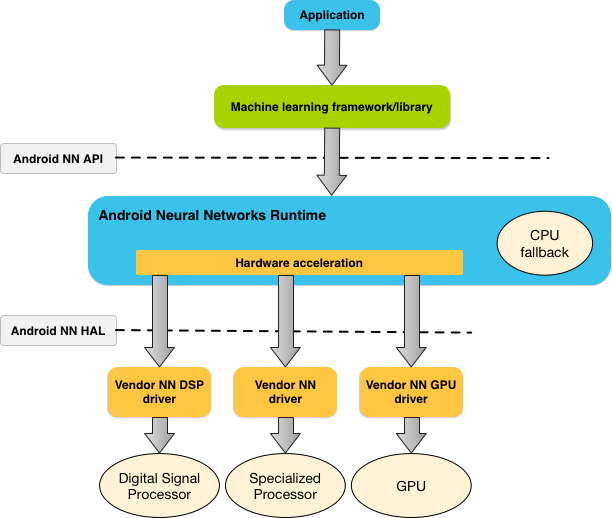 Figure 1. System architecture for Android Neural Networks API
Figure 1. System architecture for Android Neural Networks API
Neural Networks API programming model
To perform computations using NNAPI, you first need to construct a directed graph that defines the computations to perform. This computation graph, combined with your input data (for example, the weights and biases passed down from a machine learning framework), forms the model for NNAPI runtime evaluation.
NNAPI uses four main abstractions:
- Model: A computation graph of mathematical operations and the constant values learned through a training process. These operations are specific to neural networks. They include 2-dimensional (2D) convolution, logistic (sigmoid) activation, rectified linear (ReLU) activation, and more. Creating a model is a synchronous operation, but once successfully created, it can be reused across threads and compilations. In NNAPI, a model is represented as an
ANeuralNetworksModelinstance. - Compilation: Represents a configuration for compiling an NNAPI model into lower-level code. Creating a compilation is a synchronous operation, but once successfully created, it can be reused across threads and executions. In NNAPI, each compilation is represented as an
ANeuralNetworksCompilationinstance. - Memory: Represents shared memory, memory mapped files, and similar memory buffers. Using a memory buffer lets the NNAPI runtime transfer data to drivers more efficiently. An app typically creates one shared memory buffer that contains every tensor needed to define a model. You can also use memory buffers to store the inputs and outputs for an execution instance. In NNAPI, each memory buffer is represented as an
ANeuralNetworksMemoryinstance. - Execution: Interface for applying an NNAPI model to a set of inputs and to gather the results. Execution is an asynchronous operation. Multiple threads can wait on the same execution. When the execution completes, all threads will be released. In NNAPI, each execution is represented as an
ANeuralNetworksExecutioninstance.
The following diagram shows the basic programming flow.
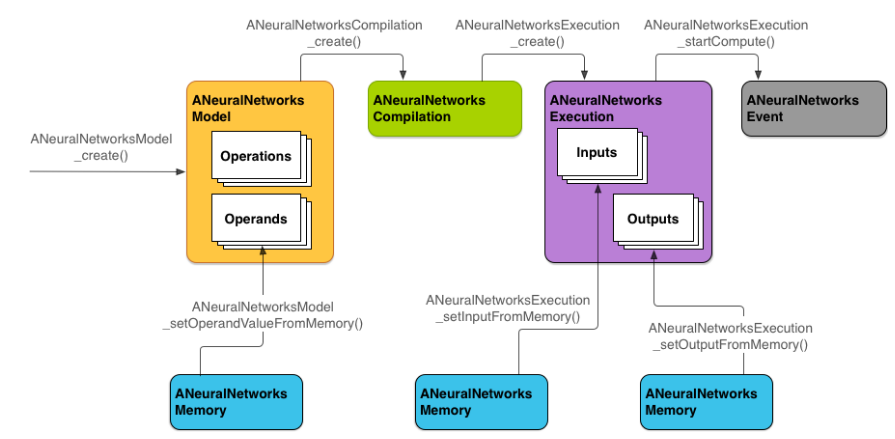
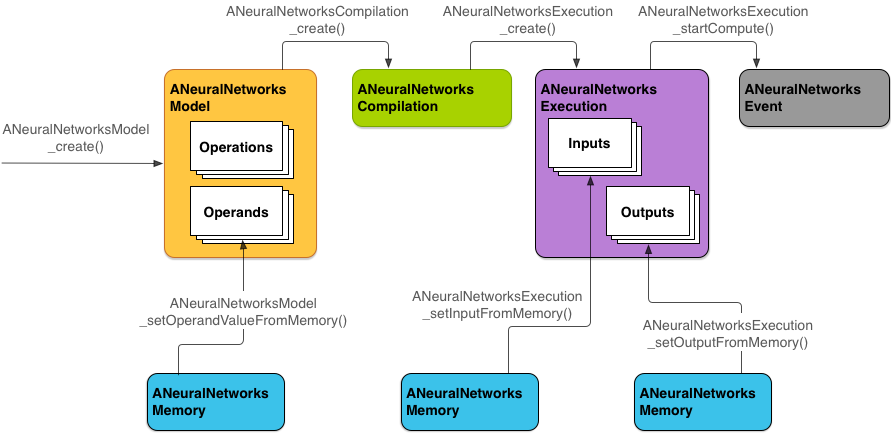 Figure 2. Programming flow for Android Neural Networks API
Figure 2. Programming flow for Android Neural Networks API
The rest of this section describes the steps to set up your NNAPI model to perform computation, compile the model, and execute the compiled model.
Tip: For brevity, we've omitted checking the result codes from each operation in the code snippets below. You should make sure to do so in your production code.Providing access to training data
Your trained weights and biases data are likely stored in a file. To provide the NNAPI runtime with efficient access to this data, create aANeuralNetworksMemory instance by calling the ANeuralNetworksMemory_createFromFd() function, and passing in the file descriptor of the opened data file.
You can also specify memory protection flags and an offset where the shared memory region starts in the file.
// Create a memory buffer from the file that contains the trained data.
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Although in this example we use only one ANeuralNetworksMemory instance for all our weights, it’s possible to use more than oneANeuralNetworksMemory instance for multiple files.
Models
A model is the fundamental unit of computation in NNAPI. Each model is defined by one or more operands and operations.
Operands
Operands are data objects used in defining the graph. These include the inputs and outputs of the model, the intermediate nodes that contain the data that flows from one operation to the other, and the constants that are passed to these operations.
There are two types of operands that can be added to NNAPI models: scalars and tensors.
A scalar represents a single number. NNAPI supports scalar values in 32-bit floating point, 32-bit integer, and unsigned 32-bit integer format.
Most operations with NNAPI involve tensors. Tensors are n-dimensional arrays. NNAPI supports tensors with 32-bit integer, 32-bit floating point, and 8-bit quantized values.
For example, the diagram below represents a model with two operations: an addition followed by a multiplication. The model takes an input tensor and produces one output tensor.
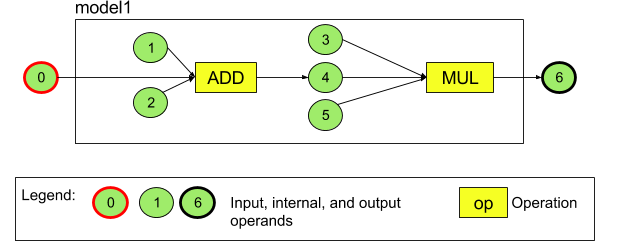
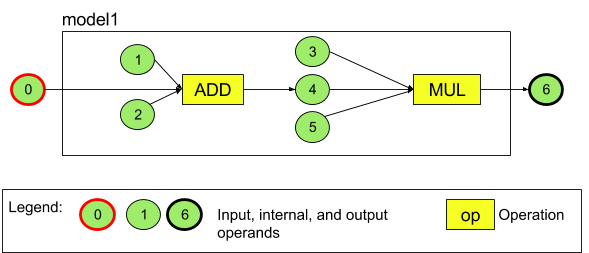 Figure 3. Example of operands for an NNAPI model
Figure 3. Example of operands for an NNAPI model
The model above has seven operands. These operands are identified implicitly by the index of the order in which they are added to the model. The first operand added has an index of 0, the second an index of 1, and so on.
The order in which you add the operands does not matter. For example, the model output operand could be the first one added. The important part is to use the right index value when referring to an operand.
Operands have types. These are specified when they are added to the model. An operand cannot be used as both input and output of a model.
For additional topics on using operands, see More about operands.
Operations
An operation specifies the computations to be performed. Each operation consists of these elements:
- an operation type (for example, addition, multiplication, convolution),
- a list of indexes of the operands that the operation uses for input, and
- a list of indexes of the operands that the operation uses for output.
The order in these lists matters; see the NNAPI API reference for each operation for the expected inputs and outputs.
You must add the operands that an operation consumes or produces to the model before the adding the operation.
The order in which you add operations does not matter. NNAPI relies on the dependencies established by the computation graph of operands and operations to determine the order in which operations are executed.
The operations that NNAPI supports are summarized in the table below:
| Category | Operations |
|---|---|
| Element-wise mathematical operations | |
| Array operations | |
| Image operations | |
| Lookup operations | |
| Normalization operations | |
| Convolution operations | |
| Pooling operations | |
| Activation operations | |
| Other operations |
Building models
To build a model, follow these steps:
-
Call the
ANeuralNetworksModel_create()function to define an empty model.In the following example, we create the two-operation model found in the diagram above.
ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model); -
Add the operands to your model by calling
ANeuralNetworks_addOperand(). Their data types are defined using theANeuralNetworksOperandTypedata structure.// In our example, all our tensors are matrices of dimension [3, 4]. ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are useful for quantized tensors. tensor3x4Type.zeroPoint = 0; // These fields are useful for quantized tensors. tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims; // We also specify operands that are activation function specifiers. ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL; // Now we add the seven operands, in the same order defined in the diagram. ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6 -
For operands that have constant values, such as weights and biases that your app obtains from a training process, use the
ANeuralNetworks_setOperandValue()andANeuralNetworks_setOperandValuesFromMemory()functions.In the following example, we set constant values from the training data file for which we created the memory buffer above.
// In our example, operands 1 and 3 are constant tensors whose value was // established during the training process. const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize. ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor); // We set the values of the activation operands, in our example operands 2 and 5. int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue)); -
For each operation in the directed graph you want to compute, add the operation to your model by calling the
ANeuralNetworks_addOperation()function.As parameters to this call, your app must provide:
- the operation type,
- the count of input values,
- the array of the indexes for input operands,
- the count of output values, and
- the array of the indexes for output operands.
Note that an operand cannot be used for both input and output of the same operation.
// We have two operations in our example. // The first consumes operands 1, 0, 2, and produces operand 4. uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes); // The second consumes operands 3, 4, 5, and produces operand 6. uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes); -
Identify which operands the model should treat as its inputs and outputs, by calling the
ANeuralNetworksModel_identifyInputsAndOutputs()function. This function lets you configure the model to use a subset of the input and output operands that you specified earlier in step 4.// Our model has one input (0) and one output (6). uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes); -
Call
ANeuralNetworksModel_finish()to finalize the definition of your model. If there are no errors, this function returns a result code ofANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Once you create a model, you can compile it any number of times and execute each compilation any number of times.
Compilation
The compilation step determines on which processors your model will be executed and asks the corresponding drivers to prepare for its execution. This could include the generation of machine code specific to the processors on which your model will run.
To compile a model, follow these steps:
-
Call the
ANeuralNetworksCompilation_create()function to create a new compilation instance.// Compile the model. ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation); -
You can optionally influence how the runtime trades off between battery power usage and execution speed. You can do so by calling
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption. ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);The valid preferences you can specify include:
ANEURALNETWORKS_PREFER_LOW_POWER: Prefer executing in a way that minimizes battery drain. This is desirable for compilations that will be executed often.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Prefer returning a single answer as fast as possible, even if this causes more power consumption.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Prefer maximizing the throughput of successive frames, for example when processing successive frames coming from the camera.
-
Finalize the compilation definition by calling
ANeuralNetworksCompilation_finish(). If there are no errors, this function returns a result code ofANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Execution
The execution step applies the model to a set of inputs, and stores the computation outputs to one or more user buffers or memory spaces that your app allocated.
To execute a compiled model, follow these steps:
-
Call the
ANeuralNetworksExecution_create()function to create a new execution instance.// Run the compiled model against a set of inputs. ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1); -
Specify where your app reads the input values for the computation. Your app can read input values from either a user buffer or an allocated memory space, by calling
Important: The indexes you specify when setting input and output buffers are indexes into the lists of inputs and outputs of the model as specified byANeuralNetworksExecution_setInput()orANeuralNetworksExecution_setInputFromMemory()respectively.ANeuralNetworksModel_identifyInputsAndOutputs(). Do not confuse them with the operand indexes used when creating the model. For example, for a model with three inputs, we should see three calls toANeuralNetworksExecution_setInput(): one with an index of 0, another with 1, and one with 2.// Set the single input to our sample model. Since it is small, we won’t use a memory buffer. float32 myInput[3, 4] = { ..the data.. }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput)); -
Specify where your app writes the output values. Your app can write output values to either a user buffer or an allocated memory space, by calling
ANeuralNetworksExecution_setOutput()orANeuralNetworksExecution_setOutputFromMemory()respectively.// Set the output. float32 myOutput[3, 4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput)); -
Schedule the execution to start, by calling the
ANeuralNetworksExecution_startCompute()function. If there are no errors, this function returns a result code ofANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously. ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end); -
Call the
ANeuralNetworksEvent_wait()function to wait for the execution to complete. If the execution was successful, this function returns a result code ofANEURALNETWORKS_NO_ERROR. Waiting can be done on a different thread than the one starting the execution.// For our example, we have no other work to do and will just wait for the completion. ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1); -
Optionally, you can apply a different set of inputs to the compiled model by using the same compilation instance to create a new
ANeuralNetworksExecutioninstance.// Apply the compiled model to a different set of inputs. ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Cleanup
The cleanup step handles the freeing of internal resources used for your computation.
// Cleanup
ANeuralNetworksCompilation_free(compilation);
ANeuralNetworksModel_free(model);
ANeuralNetworksMemory_free(mem1);
More about operands
The following section covers advanced topics about using operands.
Quantized tensors
A quantized tensor is a compact way to represent an n-dimensional array of floating point values.
NNAPI supports 8-bit asymmetric quantized tensors. For these tensors, the value of each cell is represented by an 8-bit integer. Associated with the tensor is a scale and a zero point value. These are used to convert the 8-bit integers into the floating point values that are being represented.
The formula is:
(cellValue - zeroPoint) * scale
where the zeroPoint value is a 32-bit integer and the scale a 32-bit floating point value.
Compared to tensors of 32-bit floating point values, 8-bit quantized tensors have two advantages:
- Your application will be smaller, as the trained weights will take a quarter of the size of 32-bit tensors.
- Computations can often be executed faster. This is due to the smaller amount of data that needs to be fetched from memory and the efficiency of processors such as DSPs in doing integer math.
While it is possible to convert a floating point model to a quantized one, our experience has shown that better results are achieved by training a quantized model directly. In effect, the neural network learns to compensate for the increased granularity of each value. For each quantized tensor, the scale and zeroPoint values are determined during the training process.
In NNAPI, you define quantized tensors types by setting the type field of the ANeuralNetworksOperandType data structure toANEURALNETWORKS_TENSOR_QUANT8_ASYMM. You also specify the scale and zeroPoint value of the tensor in that data structure.
Optional operands
A few operations, like ANEURALNETWORKS_LSH_PROJECTION, take optional operands. To indicate in the model that the optional operand is omitted, call theANeuralNetworksModel_setOperandValue() function, passing NULL for the buffer and 0 for the length.
If the decision on whether the operand is present or not varies for each execution, you indicate that the operand is omitted by using theANeuralNetworksExecution_setInput() or ANeuralNetworksExecution_setOutput() functions, passing NULL for the buffer and 0 for the length.

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)