
RPC入门总结(七)Thrift+Zookeeper实现服务治理
转载:基于zookeeper、连接池、Failover/LoadBalance等改造Thrift 服务化转载:基于ZooKeeper和Thrift构建动态RPC调用转载:架构设计:系统间通信(13)——RPC实例Apache Thrift 下篇(1)转载:转载:一、Thrift的弊端Thrift(或者说所有的纯粹的RPC框架都存在)的一大弊端是其静态性。由于Th
转载:基于zookeeper、连接池、Failover/LoadBalance等改造Thrift 服务化
转载:基于ZooKeeper和Thrift构建动态RPC调用
转载:架构设计:系统间通信(13)——RPC实例Apache Thrift 下篇(1)
一、Thrift的弊端
Thrift(或者说所有的纯粹的RPC框架都存在)的一大弊端是其静态性。
由于Thrift使用IDL定义RCP 调用接口,实现跨语言性。那么一旦当业务发生变化后需要重新定义接口时Thrift无法保证高可用,而且Thrift不提供对多节点的可用性保证。
二、服务治理的概念
服务治理主要为了解决RPC框架的问题而提出,主要基于服务化的思想。即在众多系统的RPC通信的上层再架一层专门进行RPC通信的协调管理,称之为服务治理框架。

1. 当服务提供者能够向外部系统提供调用服务时(无论这个调用服务是基于RPC的还是基于Http的,一般来说前者居多),它会首先向“服务管理组件”注册这个服务,包括服务名、访问权限、优先级、版本、参数、真实访路径、有效时间等等基本信息。
2. 当某一个服务使用者需要调用服务时,首先会向“服务管理组件”询问服务的基本信息。当然“服务管理组件”还会验证服务使用者是否有权限进行调用、是否符合调用的前置条件等等过滤。最终“服务管理组件”将真实的服务提供者所在位置返回给服务使用者。
3. 服务使用者拿到真实服务提供者的基本信息、调用权限后,再向真实的服务提供者发出调用请求,进行正式的业务调用过程。
在服务治理的思想中,包含几个重要元素:
1. 服务管理组件:这个组件是“服务治理”的核心组件,您的服务治理框架有多强大,主要取决于您的服务管理组件功能有多强大。它至少具有的功能包括:服务注册管理、访问路由;另外,它还可以具有:服务版本管理、服务优先级管理、访问权限管理、请求数量限制、连通性管理、注册服务集群、节点容错、事件订阅-发布、状态监控,等等功能。
2. 服务提供者(服务生产者):即服务的具体实现,然后按照服务治理框架特定的规范发布到服务管理组件中。这意味着什么呢?这意味着,服务提供者不一定按照RPC调用的方式发布服务,而是按照整个服务治理框架所规定的方式进行发布(如果服务治理框架要求服务提供者以RPC调用的形式进行发布,那么服务提供者就必须以RPC调用的形式进行发布;如果服务治理框架要求服务提供者以Http接口的形式进行发布,那么服务提供者就必须以Http接口的形式进行发布,但后者这种情况一般不会出现)。
3. 服务使用者(服务消费者):即调用这个服务的用户,调用者首先到服务管理组件中查询具体的服务所在的位置;服务管理组件收到查询请求后,将向它返回具体的服务所在位置(视服务管理组件功能的不同,还有可能进行这些计算:判断服务调用者是否有权限进行调用、是否需要生成认证标记、是否需要重新检查服务提供者的状态、让调用者使用哪一个服务版本等等)。服务调用者在收到具体的服务位置后,向服务提供者发起正式请求,并且返回相应的结果。第二次调用时,服务请求者就可以像服务提供者直接发起调用请求了(当然,您可以有一个服务提供期限的设置,使用租约协议就可以很好的实现)。
三、服务治理框架的设计
设计一个服务治理框架需要实现服务治理的两个重要组件:服务管理组件和服务提供者,结构图如下:
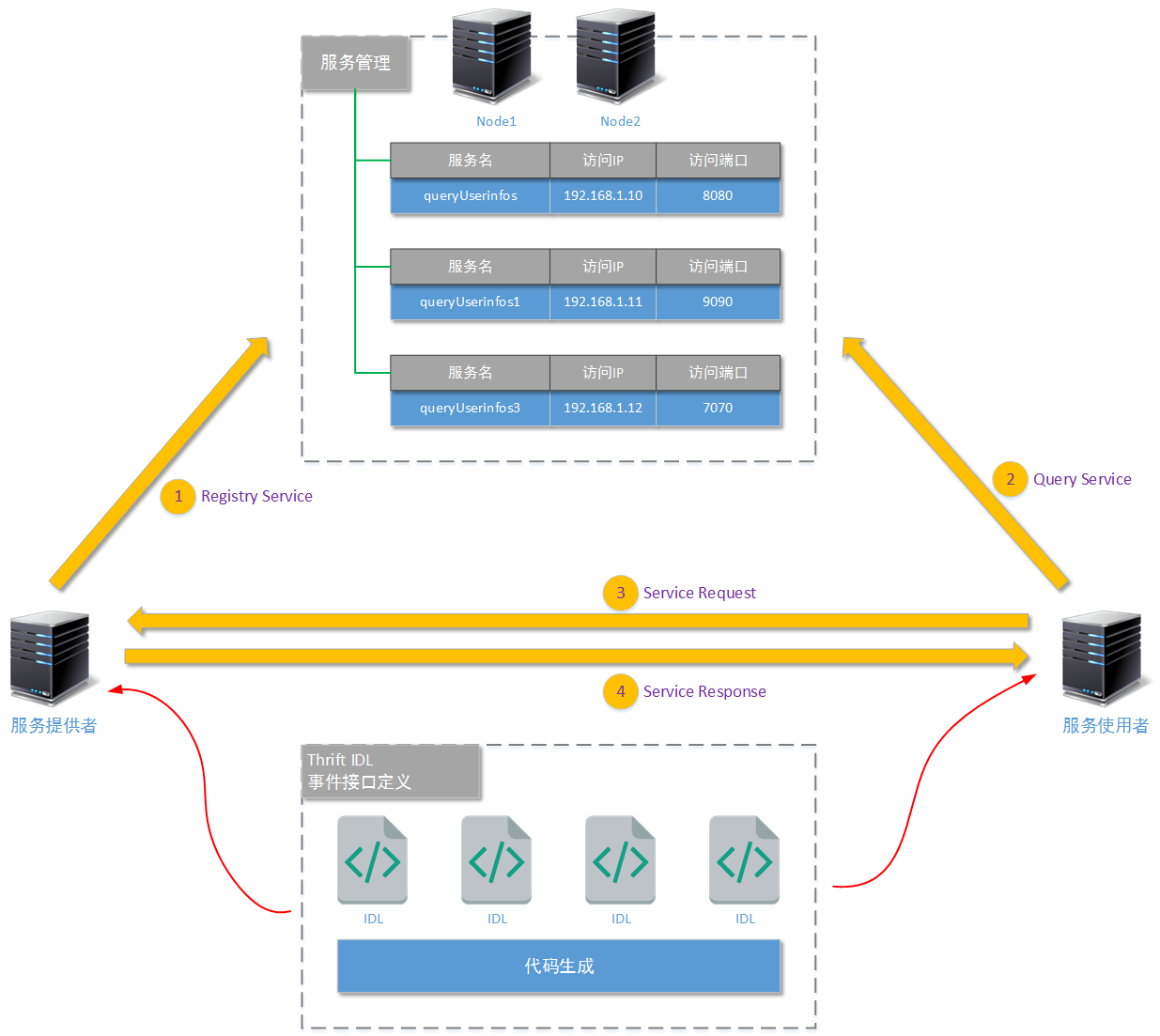
1. 服务管理组件
么按照Zookeeper的这些工作特点,我们对“服务描述格式”的结构进行了如下图所示的设计:
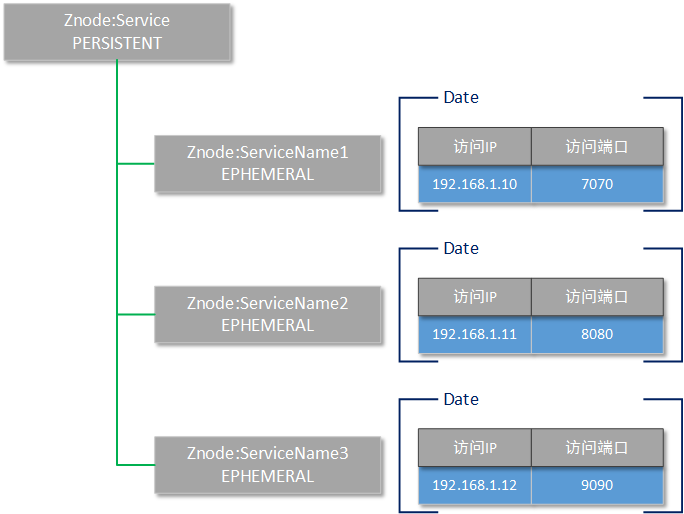
Zookeeper的根目录名字叫做Service,这是一个持久化的znode节点,并且不需要存储任何数据。
当某一个服务提供者启动后,它将连接到Zookeeper集群,并且在Service目录下,创建一个以提供的服务名为znode名称的临时节点(例如上图所示的znode,分别叫做ServiceName1、ServiceName2、ServiceName3)。
每一个Service的子级znode都使用JSON格式存储两个信息,分别是这个服务的真实访问路径和访问端口。
这样一来,当某一个服务提供者由于某些原因不能再提供服务,并且断掉和zookeeper的连接后,它所注册的服务就会消失。通过zookeeper的通知机制(或者等待客户端的下一次询问),客户端就会知道已经没有某一个服务了。
对于服务调用者(服务使用者)而言,实际上并不是每一次调用服务前,都需要请求zookeeper询问访问地址。而是只需要询问一次,如果找到相关的服务,则记录到本地;待到下一次请求时,直接寻找本地的历史记录即可。
2. Thrift
在我们这个自行设计的服务治理框架中,要解决的重要问题,就是保证做到新增一个服务时,不需要重新改变IDL定义,不需要重新生成代码。
这个问题主要的解决思路就是将Apache Thrift的接口定义进行泛化,即这个接口不调用具体的业务,而只给出调用者需要调用的接口名称(包括参数),然后在服务器端,以反射的进行具体服务的调用。IDL文件进行如下的定义:
# 这个结构体定义了服务调用者的请求信息
struct Request {
# 传递的参数信息,使用格式进行表示
1:required binary paramJSON;
# 服务调用者请求的服务名,使用serviceName属性进行传递
2:required string serviceName
}
# 这个结构体,定义了服务提供者的返回信息
struct Reponse {
# RESCODE 是处理状态代码,是一个枚举类型。例如RESCODE._200表示处理成功
1:required RESCODE responeCode;
# 返回的处理结果,同样使用JSON格式进行描述
2:required binary responseJSON;
}
# 异常描述定义,当服务提供者处理过程出现异常时,向服务调用者返回
exception ServiceException {
# EXCCODE 是异常代码,也是一个枚举类型。
# 例如EXCCODE.PARAMNOTFOUND表示需要的请求参数没有找到
1:required EXCCODE exceptionCode;
# 异常的描述信息,使用字符串进行描述
2:required string exceptionMess;
}
# 这个枚举结构,描述各种服务提供者的响应代码
enum RESCODE {
_200=200;
_500=500;
_400=400;
}
# 这个枚举结构,描述各种服务提供者的异常种类
enum EXCCODE {
PARAMNOTFOUND = 2001;
SERVICENOTFOUND = 2002;
}
# 这是经过泛化后的Apache Thrift接口
service DIYFrameworkService {
Reponse send(1:required Request request) throws (1:required ServiceException e);
}3. 服务提供者
要说清楚整个“服务治理”框架的设计思路,最主要的还是说清楚服务提供者的设计思路。因为基本上所有业务过程、事件监听调用,都发生在服务提供者这一端。对于服务调用者来说,最主要的就是两步调用过程:
1. 查询zookeeper服务管理器,找到要调用的服务地址,
2. 请求具体服务;
1. 服务提供者设计
下图表达了服务提供者的软件结构设计思路:
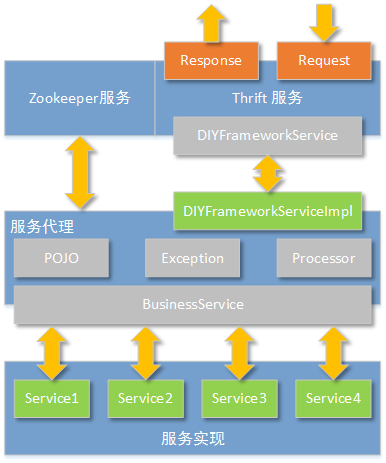
从上图可以看到,整个服务端的设计分为三层:
1. 最外层由Zookeeper客户端和Apache Thrift服务构成。Zookeeper客户端用于向Zookeeper服务集群注册“提供的服务”;Apache Thrift用于接受服务调用者的请求,并按照格式响应处理结果。
2. 由于我们定义的Apache Thrift接口(DIYFrameworkService)已经被泛化,所以具体的业务处理不能由Apache Thrift的实现(DIYFrameworkServiceImpl)来处理。由于这个原因,那么在服务端的设计中,就必须有一个服务代理层,这个服务代理层最重要的功能,就是根据Thrift收到的请求参数,决定调用哪个真实服务。
3. 根据软件功能需求的要求,具体的服务实现可以有多个。在设计中我们规定,所有的具体业务实现者,必须实现BusinessService接口中的handle方法。并且返回的类型都必须继承AbstractPojo。
2. 功能边界确认
我们目前介绍的示例如果要应用到实际工作中,那么还需要按照读者自己的业务特点进行调整、修改甚至是重新设计。对于这个示例提供的功能来说,我们提供一些简单的,具有代表意义的就可以了:
1. zookeeper服务:服务提供者的zookeeper客户端只负责连接到zookeeper服务集群,并且向zookeeper服务集群注册“服务提供者所提供的服务”。注册zookeeper时所依据的目录结构见上文中zookeeper目录结构设计的介绍。为了处理简单,zookeeper服务并不考虑性能问题,无需监听zookeeper集群上任何目录结构的变化事件,也无需将远程zookeeper集群上的目录结构缓存到本地。设计的目录结构也无需考虑一个服务由多个服务节点同时提供服务的情况。也无需考虑访问权限、访问优先级的问题。
2. Apache Thrift服务:服务提供者的Apache Thrift只负责提供远程RPC调用的监听服务。而且IDL的设计也很简单(参见上文中对IDL定义格式的介绍),只要的开发语言采用JAVA,无需生成多语言的代码。采用阻塞同步的网络通讯模式,无需考虑Apache Thrift的性能问题。
3. 服务代理:在正式的生产环境中,实际上服务代理层需要负责的工作是最多的。例如它要对服务请求者的令牌环进行判断,以便确定服务是否过期;要对请求者的权限进行验证;要管理具体的服务实现的注册,以便向zookeeper客户端告知注册情况;要决定具体执行哪一个服务实现,等等工作。但是为了让示例简洁,服务代理层只提供一个简单的注册管理和具体服务实现的调用。
服务实现在整个实例代码中,我们只提供一个服务:实现BusinessService服务层接口(business.impl.QueryUserDetailServiceImpl),查询用户详细信息的服务。并且向服务代理层注册这个服务为:”queryUserDetailService” -> “business.impl.QueryUserDetailServiceImpl”
四、服务治理框架的具体实现
1. 服务端主程序
服务端主程序的类名:processor.MainProcessor,它负责在服务端启动Apache Thrift并且在服务监听启动成功后,连接到zookeeper,注册这个服务的基本信息。
这里要注意一下,Apache Thrift的服务监听是阻塞式的,所以processor.MainProcessor的Apache Thrift操作应该另起线程进行(processor.MainProcessor.StartServerThread),并且通过线程间的锁定操作,保证zookeeper的连接一定是在Apache Thrift成功启动后才进行。
package processor;
import java.io.IOException;
import java.util.Set;
import java.util.concurrent.Executors;
import net.sf.json.JSONObject;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
import org.apache.thrift.TProcessor;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.server.ServerContext;
import org.apache.thrift.server.TServerEventHandler;
import org.apache.thrift.server.TThreadPoolServer;
import org.apache.thrift.server.TThreadPoolServer.Args;
import org.apache.thrift.transport.TServerSocket;
import org.apache.thrift.transport.TTransport;
import org.apache.thrift.transport.TTransportException;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.data.Stat;
import business.BusinessServicesMapping;
import thrift.iface.DIYFrameworkService;
import thrift.iface.DIYFrameworkService.Iface;
public class MainProcessor {
static {
BasicConfigurator.configure();
}
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(MainProcessor.class);
private static final Integer SERVER_PORT = 8090;
/**
* 专门用于锁定以保证这个主线程不退出的一个object对象
*/
private static final Object WAIT_OBJECT = new Object();
/**
* 标记apache thrift是否启动成功了
* 只有apache thrift启动成功了,才需要连接到zk
*/
private boolean isthriftStart = false;
public static void main(String[] args) {
/*
* 主程序要做的事情:
*
* 1、启动thrift服务。并且服务调用者的请求
* 2、连接到zk,并向zk注册自己提供的服务名称,告知zk真实的访问地址、访问端口
* (向zk注册的服务,存储在BusinessServicesMapping这个类的K-V常量中)
* */
//1、========启动thrift服务
MainProcessor mainProcessor = new MainProcessor();
mainProcessor.startServer();
// 一直等待,apache thrift启动完成
synchronized (mainProcessor) {
try {
while(!mainProcessor.isthriftStart) {
mainProcessor.wait();
}
} catch (InterruptedException e) {
MainProcessor.LOGGER.error(e);
System.exit(-1);
}
}
//2、========连接到zk
try {
mainProcessor.connectZk();
} catch (IOException | KeeperException | InterruptedException e) {
MainProcessor.LOGGER.error(e);
System.exit(-1);
}
// 这个wait在业务层面,没有任何意义。只是为了保证这个守护线程不会退出
synchronized (MainProcessor.WAIT_OBJECT) {
try {
MainProcessor.WAIT_OBJECT.wait();
} catch (InterruptedException e) {
MainProcessor.LOGGER.error(e);
System.exit(-1);
}
}
}
/**
* 这个私有方法用于连接到zk上,并且注册相关服务
* @throws IOException
* @throws InterruptedException
* @throws KeeperException
*/
private void connectZk() throws IOException, KeeperException, InterruptedException {
// 读取这个服务提供者,需要在zk上注册的服务
Set<String> serviceNames = BusinessServicesMapping.SERVICES_MAPPING.keySet();
// 如果没有任何服务需要注册到zk,那么这个服务提供者就没有继续注册的必要了
if(serviceNames == null || serviceNames.isEmpty()) {
return;
}
// 默认的监听器
MyDefaultWatcher defaultWatcher = new MyDefaultWatcher();
// 连接到zk服务器集群,添加默认的watcher监听
ZooKeeper zk = new ZooKeeper("192.168.61.128:2181", 120000, defaultWatcher);
//创建一个父级节点Service
Stat pathStat = null;
try {
pathStat = zk.exists("/Service", defaultWatcher);
//如果条件成立,说明节点不存在(只需要判断一个节点的存在性即可)
//创建的这个节点是一个“永久状态”的节点
if(pathStat == null) {
zk.create("/Service", "".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch(Exception e) {
System.exit(-1);
}
// 开始添加子级节点,每一个子级节点都表示一个这个服务提供者提供的业务服务
for (String serviceName : serviceNames) {
JSONObject nodeData = new JSONObject();
nodeData.put("ip", "127.0.0.1");
nodeData.put("port", MainProcessor.SERVER_PORT);
zk.create("/Service/" + serviceName, nodeData.toString().getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
}
//执行到这里,说明所有的service都启动完成了
MainProcessor.LOGGER.info("===================所有service都启动完成了,主线程开始启动===================");
}
/**
* 这个私有方法用于开启Apache thrift服务端,并进行持续监听
* @throws TTransportException
*/
private void startServer() {
Thread startServerThread = new Thread(new StartServerThread());
startServerThread.start();
}
private class StartServerThread implements Runnable {
@Override
public void run() {
MainProcessor.LOGGER.info("看到这句就说明thrift服务端准备工作 ....");
// 服务执行控制器(只要是调度服务的具体实现该如何运行)
TProcessor tprocessor = new DIYFrameworkService.Processor<Iface>(new DIYFrameworkServiceImpl());
// 基于阻塞式同步IO模型的Thrift服务,正式生产环境不建议用这个
TServerSocket serverTransport = null;
try {
serverTransport = new TServerSocket(MainProcessor.SERVER_PORT);
} catch (TTransportException e) {
MainProcessor.LOGGER.error(e);
System.exit(-1);
}
// 为这个服务器设置对应的IO网络模型、设置使用的消息格式封装、设置线程池参数
Args tArgs = new Args(serverTransport);
tArgs.processor(tprocessor);
tArgs.protocolFactory(new TBinaryProtocol.Factory());
tArgs.executorService(Executors.newFixedThreadPool(100));
// 启动这个thrift服务
TThreadPoolServer server = new TThreadPoolServer(tArgs);
server.setServerEventHandler(new StartServerEventHandler());
server.serve();
}
}
/**
* 为这个TThreadPoolServer对象,设置是一个事件处理器。
* 以便在TThreadPoolServer正式开始监听服务请求前,通知mainProcessor:
* “Apache Thrift已经成功启动了”
* @author yinwenjie
*
*/
private class StartServerEventHandler implements TServerEventHandler {
@Override
public void preServe() {
/*
* 需要实现这个方法,以便在服务启动成功后,
* 通知mainProcessor: “Apache Thrift已经成功启动了”
* */
MainProcessor.this.isthriftStart = true;
synchronized (MainProcessor.this) {
MainProcessor.this.notify();
}
}
/* (non-Javadoc)
* @see org.apache.thrift.server.TServerEventHandler#createContext(org.apache.thrift.protocol.TProtocol, org.apache.thrift.protocol.TProtocol)
*/
@Override
public ServerContext createContext(TProtocol input, TProtocol output) {
/*
* 无需实现
* */
return null;
}
@Override
public void deleteContext(ServerContext serverContext, TProtocol input, TProtocol output) {
/*
* 无需实现
* */
}
@Override
public void processContext(ServerContext serverContext, TTransport inputTransport, TTransport outputTransport) {
/*
* 无需实现
* */
}
}
/**
* 这是默认的watcher,什么也没有,也不需要有什么<br>
* 因为按照功能需求,服务器端并不需要监控zk上的任何目录变化事件
* @author yinwenjie
*/
private class MyDefaultWatcher implements Watcher {
public void process(WatchedEvent event) {
}
}
}服务端具体实现的代码很简单,就是在IDL脚本生成了java代码后,对DIYFrameworkService接口进行的实现。
package processor;
import java.nio.ByteBuffer;
import net.sf.json.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.thrift.TException;
import business.BusinessService;
import business.BusinessServicesMapping;
import business.exception.BizException;
import business.exception.ResponseCode;
import business.pojo.AbstractPojo;
import business.pojo.BusinessResponsePojo;
import business.pojo.DescPojo;
import thrift.iface.DIYFrameworkService.Iface;
import thrift.iface.EXCCODE;
import thrift.iface.RESCODE;
import thrift.iface.Reponse;
import thrift.iface.Request;
import thrift.iface.ServiceException;
import utils.JSONUtils;
/**
* IDL文件中,我们定义的唯一服务接口DIYFrameworkService.Iface的唯一实现
* @author yinwenjie
*
*/
public class DIYFrameworkServiceImpl implements Iface {
/**
* 日志
*/
public static final Log LOGGER = LogFactory.getLog(DIYFrameworkServiceImpl.class);
/* (non-Javadoc)
* @see thrift.iface.DIYFrameworkService.Iface#send(thrift.iface.Request)
*/
@SuppressWarnings("unchecked")
@Override
public Reponse send(Request request) throws ServiceException, TException {
/*
* 由于MainProcessor中,在Apache Thrift 服务端启动时已经加入了线程池,所以这里就不需要再使用线程池了
* 这个服务方法的实现,需要做以下事情:
*
* 1、根据request中,描述的具体服务名称,在配置信息中查找具体的服务类
* 2、使用java的反射机制,调用具体的服务类(BusinessService接口的实现类)。
* 3、根据具体的业务处理结构,构造Reponse对象,并进行返回
* */
//1、===================
String serviceName = request.getServiceName();
String className = BusinessServicesMapping.SERVICES_MAPPING.get(serviceName);
//未发现服务
if(StringUtils.isEmpty(className)) {
return this.buildErrorReponse("无效的服务" , null);
}
//2、===================
// 首先得到以json为描述格式的请求参数信息
JSONObject paramJSON = null;
try {
byte [] paramJSON_bytes = request.getParamJSON();
if(paramJSON_bytes != null && paramJSON_bytes.length > 0) {
String paramJSON_string = new String(paramJSON_bytes);
paramJSON = JSONObject.fromObject(paramJSON_string);
}
} catch(Exception e) {
DIYFrameworkServiceImpl.LOGGER.error(e);
// 向调用者抛出异常
throw new ServiceException(EXCCODE.PARAMNOTFOUND, e.getMessage());
}
// 试图进行反射
BusinessService<AbstractPojo> businessServiceInstance = null;
try {
businessServiceInstance = (BusinessService<AbstractPojo>)Class.forName(className).newInstance();
} catch (Exception e) {
DIYFrameworkServiceImpl.LOGGER.error(e);
// 向调用者抛出异常
throw new ServiceException(EXCCODE.SERVICENOTFOUND, e.getMessage());
}
// 进行调用
AbstractPojo returnPojo = null;
try {
returnPojo = businessServiceInstance.handle(paramJSON);
} catch (BizException e) {
DIYFrameworkServiceImpl.LOGGER.error(e);
return this.buildErrorReponse(e.getMessage() , e.getResponseCode());
}
// 构造处理成功情况下的返回信息
BusinessResponsePojo responsePojo = new BusinessResponsePojo();
responsePojo.setData(returnPojo);
DescPojo descPojo = new DescPojo("", ResponseCode._200);
responsePojo.setDesc(descPojo);
// 生成json
String returnString = JSONUtils.toString(responsePojo);
byte[] returnBytes = returnString.getBytes();
ByteBuffer returnByteBuffer = ByteBuffer.allocate(returnBytes.length);
returnByteBuffer.put(returnBytes);
returnByteBuffer.flip();
// 构造response
Reponse reponse = new Reponse(RESCODE._200, returnByteBuffer);
return reponse;
}
/**
* 这个私有方法,用于构造“Thrift中错误的返回信息”
* @param erroe_mess
* @return
*/
private Reponse buildErrorReponse(String erroe_mess , ResponseCode responseCode) {
// 构造返回信息
BusinessResponsePojo responsePojo = new BusinessResponsePojo();
responsePojo.setData(null);
DescPojo descPojo = new DescPojo(erroe_mess, responseCode == null?ResponseCode._504:responseCode);
responsePojo.setDesc(descPojo);
// 存储byteBuffer;
String responseJSON = JSONUtils.toString(responsePojo);
byte[] responseJSON_bytes = responseJSON.getBytes();
ByteBuffer byteBuffer = ByteBuffer.allocate(responseJSON_bytes.length);
byteBuffer.put(byteBuffer);
byteBuffer.flip();
Reponse reponse = new Reponse(RESCODE._500, byteBuffer);
return reponse;
}
}客户端有两件事情需要做:连接到zookeeper查询注册的服务该如何访问;然后向真实的服务提供者发起请求。代码如下:
package client;
import java.nio.ByteBuffer;
import java.util.List;
import net.sf.json.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.log4j.BasicConfigurator;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.transport.TSocket;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.data.Stat;
import thrift.iface.DIYFrameworkService.Client;
import thrift.iface.Reponse;
import thrift.iface.Request;
import utils.JSONUtils;
public class ThriftClient {
/**
* 日志
*/
private static final Log LOGGER = LogFactory.getLog(ThriftClient.class);
private static final String SERVCENAME = "queryUserDetailService";
static {
BasicConfigurator.configure();
}
public static final void main(String[] main) throws Exception {
/*
* 服务治理框架的客户端示例,要做以下事情:
*
* 1、连接到zk,查询当前zk下提供的服务列表中是否有自己需要的服务名称(queryUserDetailService)
* 2、如果没有找到需要的服务名称,则客户端终止工作
* 3、如果找到了服务,则通过服务给出的ip,port,基于Thrift进行正式请求
* (这时,和zookeeper是否断开,关系就不大了)
* */
// 1、===========================
// 默认的监听器
ClientDefaultWatcher defaultWatcher = new ClientDefaultWatcher();
// 连接到zk服务器集群,添加默认的watcher监听
ZooKeeper zk = new ZooKeeper("192.168.61.128:2181", 120000, defaultWatcher);
/*
* 为什么客户端连接上来以后,也可能创建一个Service根目录呢?
* 因为正式的环境下,不能保证客户端一点就在服务器端全部准备好的情况下,再来做调用请求
* */
Stat pathStat = null;
try {
pathStat = zk.exists("/Service", defaultWatcher);
//如果条件成立,说明节点不存在(只需要判断一个节点的存在性即可)
//创建的这个节点是一个“永久状态”的节点
if(pathStat == null) {
zk.create("/Service", "".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch(Exception e) {
System.exit(-1);
}
// 2、===========================
//获取服务列表(不需要做任何的事件监听,所以第二个参数可以为false)
List<String> serviceList = zk.getChildren("/Service", false);
if(serviceList == null || serviceList.isEmpty()) {
ThriftClient.LOGGER.info("未发现相关服务,客户端退出");
return;
}
//然后查看要找寻的服务是否在存在
boolean isFound = false;
byte[] data;
for (String serviceName : serviceList) {
if(StringUtils.equals(serviceName, ThriftClient.SERVCENAME)) {
isFound = true;
break;
}
}
if(!isFound) {
ThriftClient.LOGGER.info("未发现相关服务,客户端退出");
return;
} else {
data = zk.getData("/Service/" + ThriftClient.SERVCENAME, false, null);
}
/*
* 执行到这里,zk的工作就完成了,接下来zk是否断开,就不重要了
* */
zk.close();
if(data == null || data.length == 0) {
ThriftClient.LOGGER.info("未发现有效的服务端地址,客户端退出");
return;
}
// 得到服务器地值说明
JSONObject serverTargetJSON = null;
String serverIp;
String serverPort;
try {
serverTargetJSON = JSONObject.fromObject(new String(data));
serverIp = serverTargetJSON.getString("ip");
serverPort = serverTargetJSON.getString("port");
} catch(Exception e) {
ThriftClient.LOGGER.error(e);
return;
}
//3、===========================
TSocket transport = new TSocket(serverIp, Integer.parseInt(serverPort));
TProtocol protocol = new TBinaryProtocol(transport);
// 准备调用参数
JSONObject jsonParam = new JSONObject();
jsonParam.put("username", "yinwenjie");
byte[] params = jsonParam.toString().getBytes();
ByteBuffer buffer = ByteBuffer.allocate(params.length);
buffer.put(params);
buffer.flip();
Request request = new Request(buffer, ThriftClient.SERVCENAME);
// 开始调用
Client client = new Client(protocol);
// 准备传输
transport.open();
// 正式调用接口
Reponse reponse = client.send(request);
byte[] responseBytes = reponse.getResponseJSON();
// 一定要记住关闭
transport.close();
// 将返回信息显示出来
ThriftClient.LOGGER.info("respinse value = " + new String(responseBytes));
}
}
/**
* 这是默认的watcher,什么也没有,也不需要有什么<br>
* 因为按照功能需求,客户端并不需要监控zk上的任何目录变化事件
* @author yinwenjie
*/
class ClientDefaultWatcher implements Watcher {
public void process(WatchedEvent event) {
}
}

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)