SpringCloud Zipkin
前提:SpringCloud解决方案下,存在一个EurekaServer项目,外加两个子项目,并在一个项目中使用hystrix方法调用另外一个项目中的接口我这里有三个子项目分别为:eureka,gateway,user创建子项目zipkin,pom.xml中加入依赖:io.zipkin.javazipkin-server
Zipkin是一个链路跟踪工具,可以用来监控微服务集群中调用链路的通畅情况
前提:SpringCloud解决方案下,存在两个子项目,并在一个项目中使用RestTemplate或者Feign等方法调用另外一个项目中的接口
我这里有三个子项目分别为:gateway,user,blog;其中gateway的hello接口通过RestTemplate调用了user的hello接口,user的hello接口通过Feign调用blog的hi接口
创建子项目zipkin,pom.xml中加入依赖:
<dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> </dependency>
启动类:
@SpringBootApplication @EnableZipkinServer public class ZipkinApplication { public static void main(String[] args) { SpringApplication.run(ZipkinApplication.class, args); } }
在gateway和user项目的pom.xml中分配加入zipkin的依赖:
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
在gateway和user项目的application.yml中分配加入zipkin地址配置:
spring: zipkin: base-url: http://localhost:9998
启动zipkin项目,浏览器输入:http://localhost:9998,这里9998是我配置文件的端口号
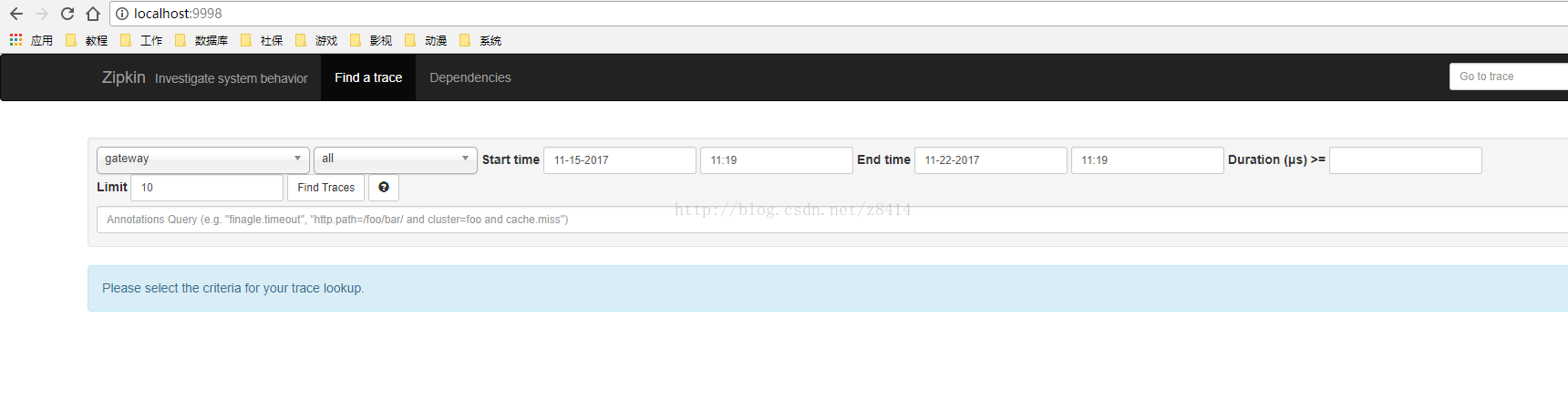
分别在user项目启动和停止的情况下,在浏览器中调用gateway的hello接口

蓝色的表示在user项目启动的情况下通过gateway成功调用了user的接口,红色的表示user停止的情况下,gateway不能成功调用
user接口。点击红色条目,可以看到调用情况图

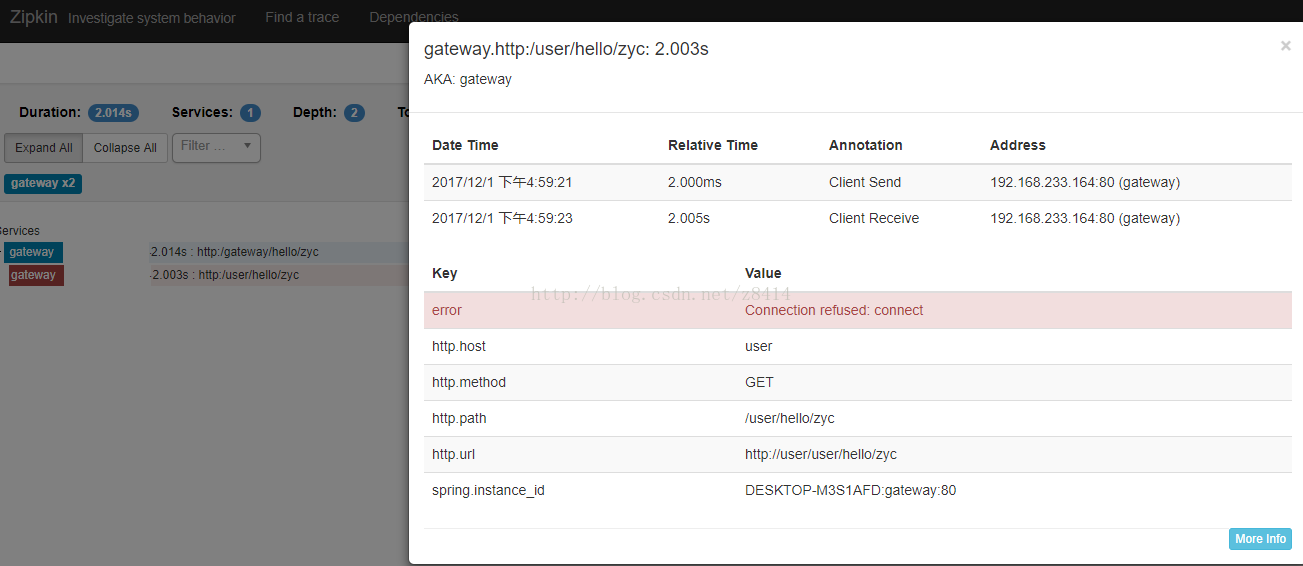
点击红色栏目,可以看到错误信息
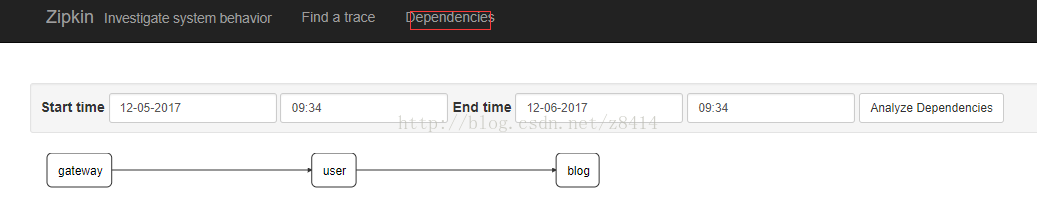
Dependencies菜单下可以看到项目依赖关系:
默认的采样比率为0.1,不能看到所有请求数据,可以在每个客户端的application.yml中加入下面的配置,更改采样比率为1,就能看到所有的请求数据了,但是这样会增加接口调用延迟
spring: sleuth: sampler: percentage: 1 #zipkin采样率,默认为0.1,改为1后全采样,但是会降低接口调用效率
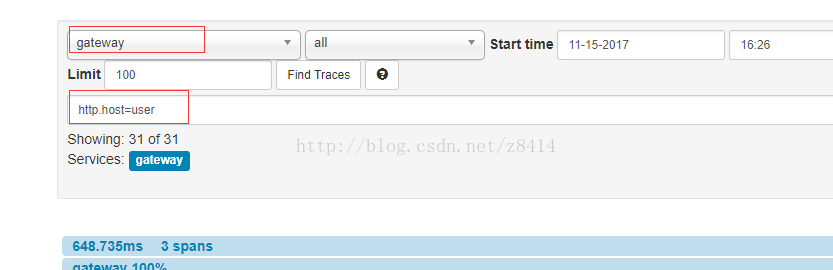
通过http.host过滤条件搜索出所有从gateway到user的调用请求,也可以用http.path=/user/hello/zyc过滤某个具体的请求
(改造一)通过数据库存储数据,参考了这篇文章https://www.cnblogs.com/shunyang/p/7011303.html
zipkin项目的pom.xml中加入依赖:
<dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-mysql</artifactId> </dependency>
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency>
<dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> </dependency>
HikariCP连接池可选,如果不用连接池去掉这个依赖,并把application.yml中的datasource.type属性去掉
application.yml中加入配置:spring: application: name: zipkin sleuth: enabled: false datasource: name: zipkin type: com.zaxxer.hikari.HikariDataSource driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://192.168.11.11:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false username: root password: 123456 schema[0]: classpath:/zipkin.sql initialize: true continue-on-error: true zipkin: storage: type: mysqlresources目录下放入zipkin.sql,此文件最新地址https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql/src/main/resources/mysql.sql
然后在数据库中创建一个名为zipkin的数据库,然后启动zipkin项目,这时会根据zipkin.sql脚本创建数据库;再启动两个存在调用关系的项目gateway和user,调用gateway的接口,然后就会发现数据库的表中有数据库了。zipkin页面上也可以显示数据,重启zipkin后数据也不会消失。
(改造二)通过kafka队列来异步传输数据
首先搭建一个kafka的集群,参考我的另外一篇文章kafka集群搭建
在改造一的基础上,在zipkin、gateway、user项目中加入下列依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <!--也可以使用spring-cloud-stream-binder-kafka--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-kafka</artifactId> </dependency>原来zipkin中的zipkin-server、gateway和user中的spring-cloud-starter-zipkin依赖可以移除了
在三个项目的yml配置文件中spring节点下加入kafka配置
spring: cloud: stream: kafka: binder: brokers: 192.168.1.2,192.168.1.3 #ip地址根据实际kafka集群地址 zkNodes: 192.168.1.2,192.168.1.3配置完成后启动gateway和user,先不启动zipkin,然后调用gateway的hello接口,然后在启动zipkin,发现马上就有调用记录了,而且数据库也有数据了,说明通过kafka传输数据成功了。
性能分析:
这里使用jmeter工具进行测试,使用了10个线程循环10次,配置如下:

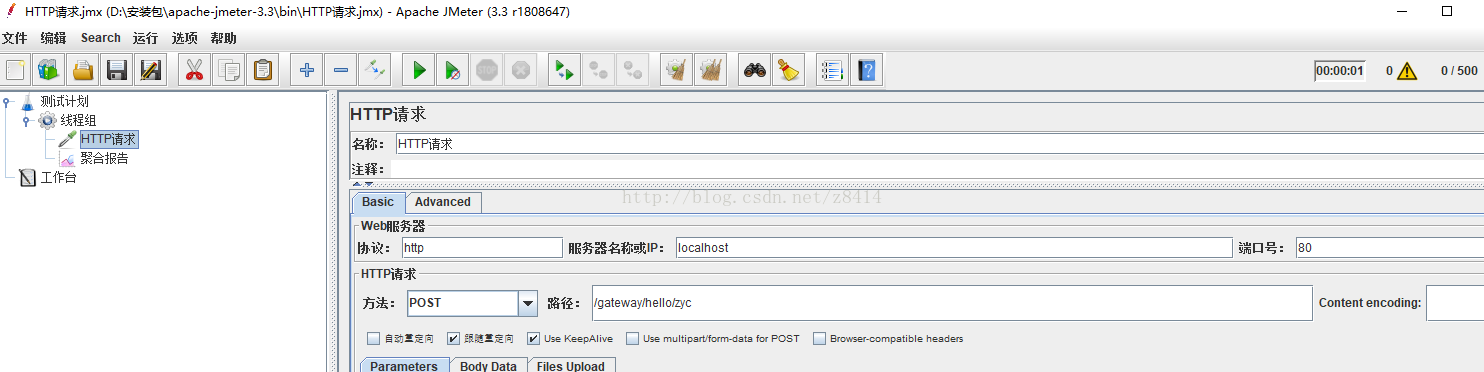
(1)不使用zipkin的情况

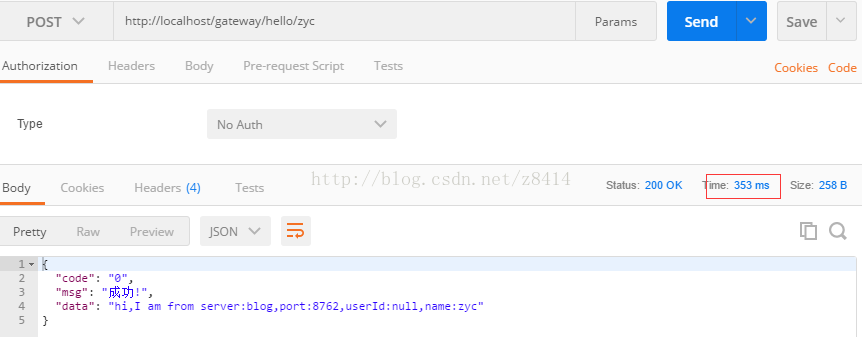
这里jmeter平均请求时间391ms
(2)使用zipkin,不使用数据库和kafka中间件的情况:
采样率为0.1的时候:

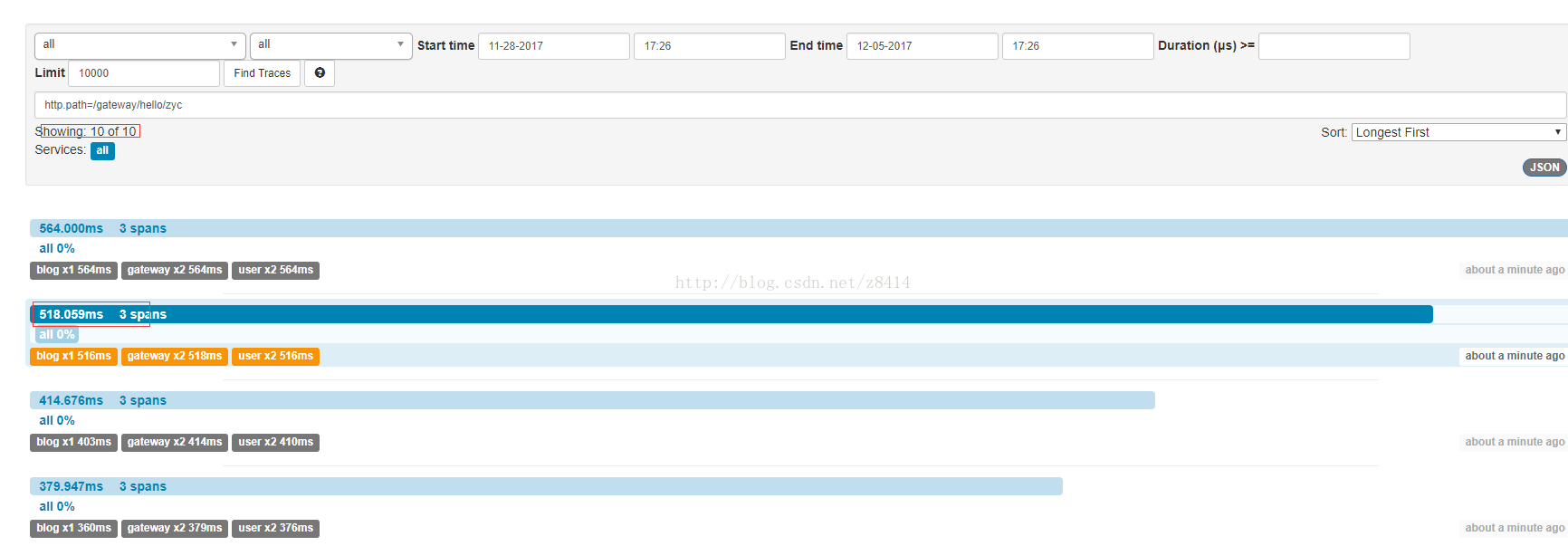
这里总共100次请求,在采样率为0.1的情况下记录了10次,jmeter平均请求时间为371ms
采样率为1的时候:


这里总共100次请求,在采样率为1的情况下记录了100次,jmeter平均请求时间为427ms
(3)使用zipkin,使用mysql数据库存储数据的情况:
采样率为0.1的时候:

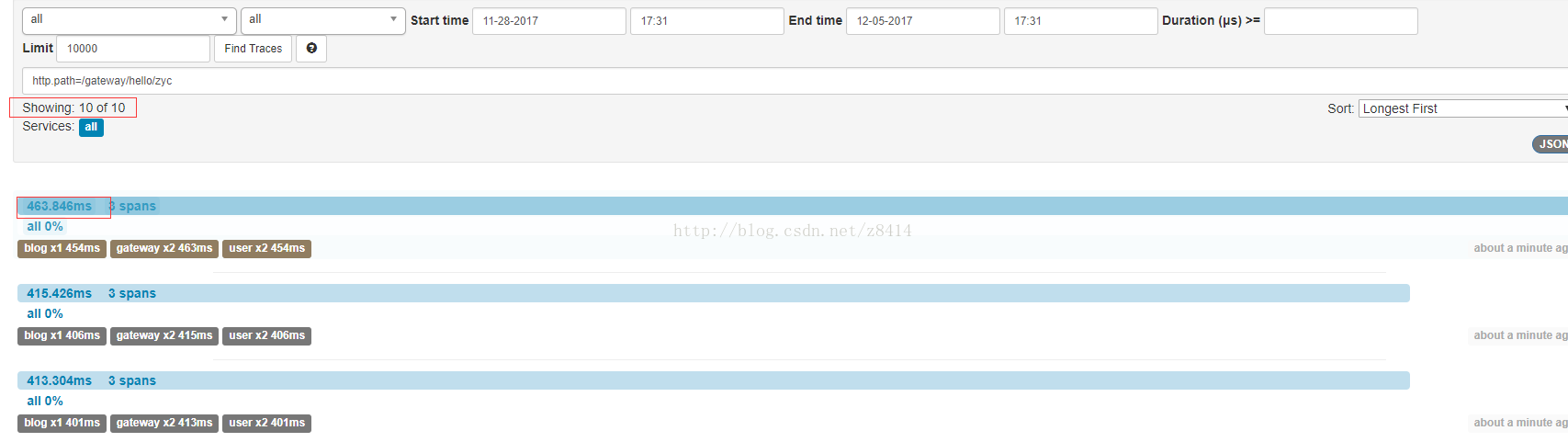
这里总共100次请求,在采样率为0.1的情况下记录了10次,jmeter平均请求时间为357ms
采样率为1的时候:

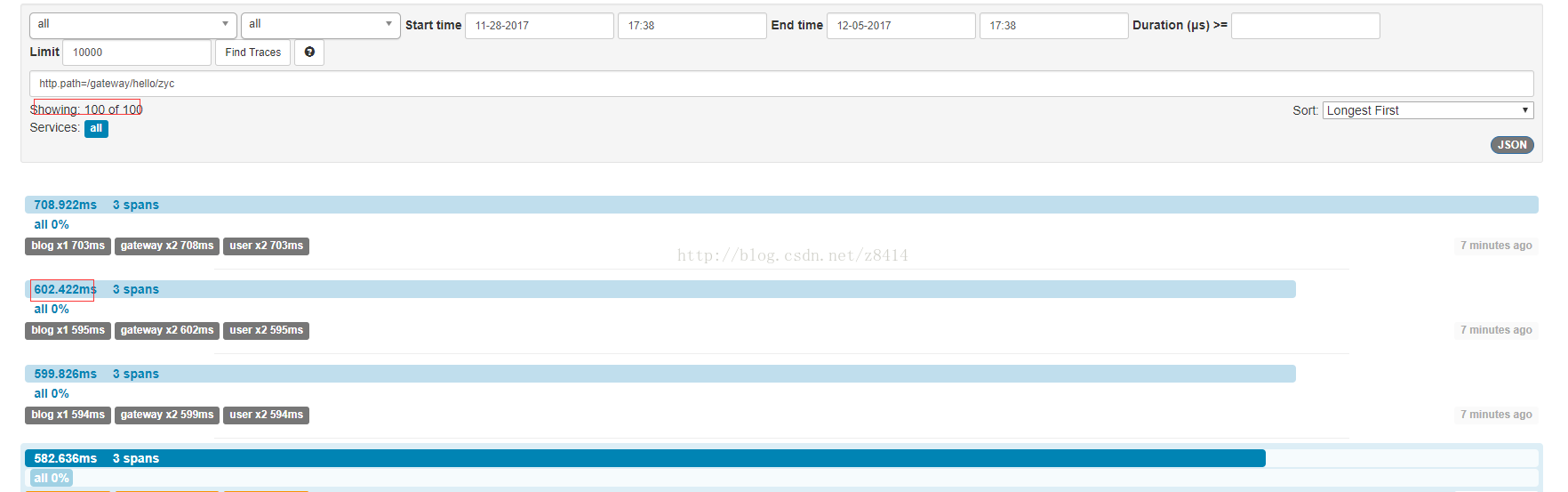
这里发现高采样率的情况下,请求时间波动变大,jmeter平均请求时间为412ms。
(4)使用zipkin,使用mysql存储数据,使用kafka传输数据的情况:
采样率为0.1的情况:

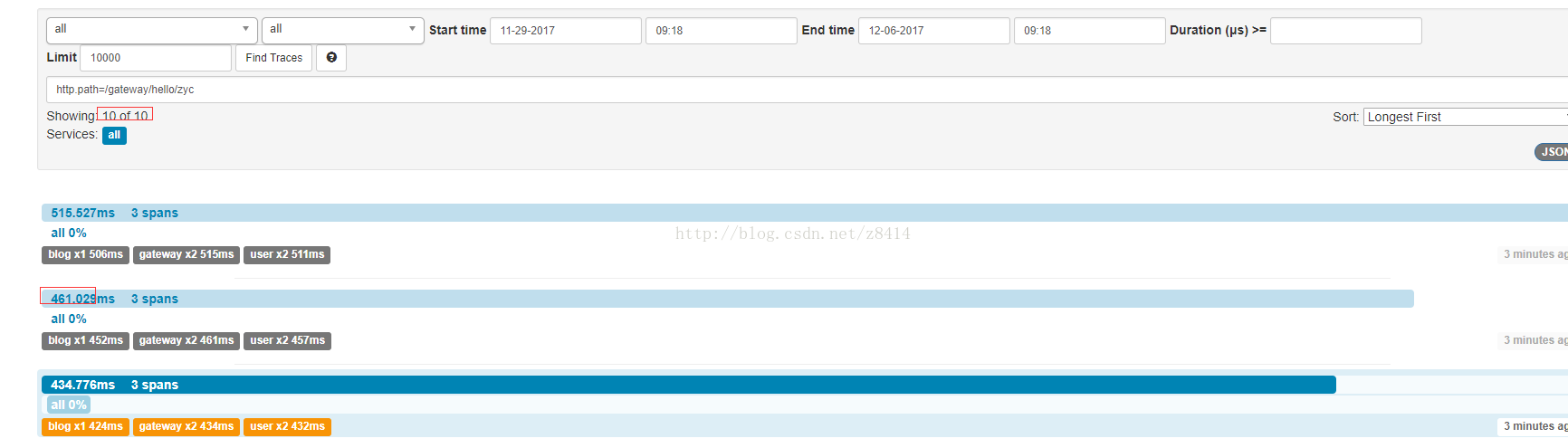
这里总共100次请求,在采样率为0.1的情况下记录了10次,jmeter平均请求时间为390ms
采样率为1的情况:

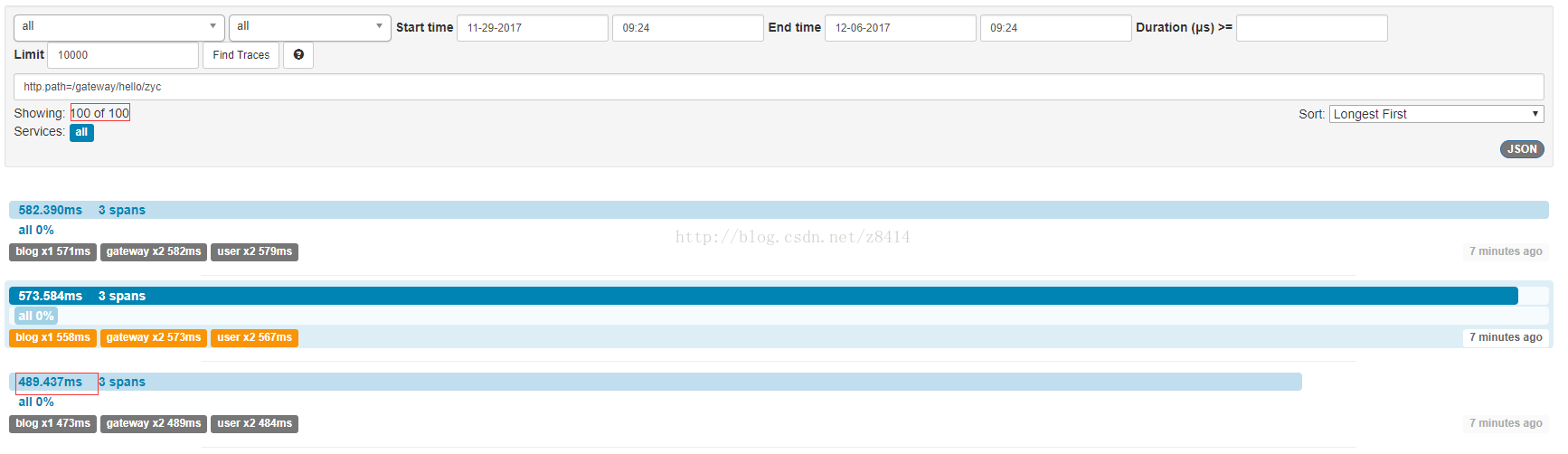
这里总共100次请求,在采样率为1的情况下记录了100次,jmeter平均请求时间为392ms
通过上述分析得出结论:
① 在内存存储数据时不适合使用高采样比率;
② 通过数据库存储时可以用高采样比率,对服务本身影响不大,但是如果zipkin服务端down掉,期间就不能存储数据了
③ 通过数据库和kafka等中间件异步传输数据基本对服务无影响,而且就算zipkin服务端down掉,重启后依然会从kafka中取出数据存储在数据库中,不会有数据丢失
另,在网上看到有说mysql保存链路调用信息,数据量大后会卡死,推荐使用elasticsearch保存数据,具体没有试过。
关于zipkin源码分析,这个博客写的不错https://my.oschina.net/mozhu/blog

云原生社区为您提供最前沿的新闻资讯和知识内容
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)