深度学习(七十)darknet 实现编写mobilenet源码
)parse.c文件中函数string_to_layer_type,添加网络层类型解析:if (strcmp(type, "[depthwise_convolutional]") == 0) return DEPTHWISE_CONVOLUTIONAL;(2)darknet.h文件中枚举类型LAYER_TYPE,添加网络层枚举类型:DEPTHWISE_CONVOLUTIONAL;(3)parse.
一、添加一个新的网络层
(1)parse.c文件中函数string_to_layer_type,添加网络层类型解析:
if (strcmp(type, "[depthwise_convolutional]") == 0) return DEPTHWISE_CONVOLUTIONAL;(2)darknet.h文件中枚举类型LAYER_TYPE,添加网络层枚举类型:
DEPTHWISE_CONVOLUTIONAL;(3)parse.c文件中函数parse_network_cfg添加网络层解析后进行构建:
LAYER_TYPE lt = string_to_layer_type(s->type);
if (lt == DEPTHWISE_CONVOLUTIONAL) {
l = parse_depthwise_convolutional(options, params);//自己编写的函数,主要调用了make layer
}
else if(lt == CONVOLUTIONAL){
l = parse_convolutional(options, params);(4)parse.c 添加参数读取网络层加载文件
A、添加网络层读取参数函数
void load_weights_upto(network *net, char *filename, int start, int cutoff)
load depthwise weights;B、把参数读取到内存上:
void load_depthwise_convolutional_weights(layer l, FILE *fp);C、以及修改depthwise_convolutional_kenel.cu把读取后的cpu参数拷贝到显存上:
void push_depthwise_convolutional_layer(depthwise_convolutional_layer layer);(5)parse.c添加参数保存功能:
void save_weights_upto(network net, char *filename, int cutoff):
void save_depthwise_convolutional_weights(layer l, FILE *fp);
void pull_depthwise_convolutional_layer(depthwise_convolutional_layer layer);(6)添加network.c中网络层:
int resize_network(network *net, int w, int h)的resize:
if (l.type==DEPTHWISE_CONVOLUTIONAL)
{
resize_depthwise_convolutional_layer(&l, w, h);
}(7)另外在多卡异步训练的时候,network_kernels.cu的好几个函数也要添加depth_convolutional参数相关的更新设置。
总结为一句话:直接搜索项目中调用:CONVOLUTIONAL的关键子
有调用到卷积层枚举类型的地方,可分离卷积层也要添加相对应的功能。
(8)darknet使用须知:darknet的网络配置文件中的学习率、batch并不是我们平时所说的学习率、batch_size。网络更新所用的学习率为:learning_rate/batch_size,所以学习率不能太小,比如如果学习率设置为0.01,batch=128,那么实际计算的学习率就是0.000078,非常小的一个数值,基本上就是更新不了
二、编写网络层代码:depthwise_convolutional_kernels.cu、depthwise_convolutional_layer.c、depthwise_convolutional_layer.h
三、编写mobilenet网络结构文件:
[net]
batch=32
subdivisions=1
height=224
width=224
channels=3
momentum=0.9
decay=0.000
max_crop=320
learning_rate=0.1
policy=poly
power=3
max_batches=1600000
#conv1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=2
pad=1
activation=relu
#conv2_1/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv2_1/sep
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=0
activation=relu
#conv2_2/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=2
pad=1
activation=relu
#conv2_2/sep
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=0
activation=relu
#conv3_1/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv3_1/sep
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=0
activation=relu
#conv3_2/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=2
pad=1
activation=relu
#conv3_2/sep
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=0
activation=relu
#conv4_1/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv4_1/sep
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=0
activation=relu
#conv4_2/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=2
pad=1
activation=relu
#conv4_2/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_1/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv5_1/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_2/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv5_2/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_3/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv5_3/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_4/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv5_4/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_5/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv5_5/sep
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=0
activation=relu
#conv5_6/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=2
pad=1
activation=relu
#conv5_6/sep
[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=0
activation=relu
#conv6/dw
[depthwise_convolutional]
batch_normalize=1
size=3
stride=1
pad=1
activation=relu
#conv6/sep
[convolutional]
batch_normalize=1
filters=1024
size=1
stride=1
pad=0
activation=relu
#pool6
[avgpool]
#fc7
[convolutional]
filters=1000
size=1
stride=1
pad=0
activation=leaky
[softmax]
groups=1
[cost]
1、训练一天后,经过两轮多的epoch后,精度:
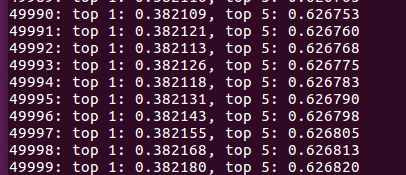
2、训练两天后,迭代第二天结果:

3\又训练了一天多:


CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 6
6 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)