
试一试dgraph
在github上下载了0.7.7版本的tar包dgraph-linux-amd64-v0.7.7.tar.gz。我是在ubuntu16.04下试的。解压后可以运行,但是在浏览器里输入localhost:8080看不到页面。 在ubuntu14.04和ubuntu12.04下不能运行。没办法拉一个docker试试吧。直接拉很慢,还是配置一下daocloud的镜像源吧。如果你跟我一样,用的是ubun
在github上下载了0.7.7版本的tar包dgraph-linux-amd64-v0.7.7.tar.gz。我是在ubuntu16.04下试的。解压后可以运行,但是在浏览器里输入localhost:8080看不到页面。 在ubuntu14.04和ubuntu12.04下不能运行。
没办法拉一个docker试试吧。直接拉很慢,还是配置一下daocloud的镜像源吧。
如果你跟我一样,用的是ubuntu16.04。请参考这篇文章ubuntu16.04设置daocloud镜像源。因为daocloud官网没有说在ubunt16.04上怎么配置镜像源。
设置好并且重启docker服务之后。
sudo docker pull dgraph/dgraph:v0.7.7
目前github上release最新的版本就是v0.7.7。docker里已经有1.0版本了,docker竟然比github新,出乎意料。
拉完了之后 sudo docker images看一下。
然后mkdir -p ~/dgraph
sudo docker run -it -p 9090:8080 -v ~/dgraph:/dgraph --name dgraph dgraph/dgraph:v0.7.7 dgraph --bindall=true-p 9090:8080 意思是把容器里8080端口映射到主机的9090端口上。
-v ~/dgraph:/dgraph是映射数据卷。将来dgraph的数据和日志都会写到主机的~/dgraph/目录下
–name dgraph是给容器起一个名字叫dgraph
dgraph/dgraph:v0.7.7 意思是从这个镜像启动一个容器
dgraph是容器起来后运行的命令。我们知道启动dgraph的命令就是 dgraph
–bindall=true 不知道什么意思。猜测是绑定 0.0.0.0到8080
这样dgraph的环境就搭好了。有docker就是好啊。
浏览器输入http://192.168.x.x:9090 看到如下画面:
哎哟乍一看很像neo4j的画面哦。 画面也比cayley好看一些。 cayley的页面太简陋了。
输入框里输入:
mutation {
set {
_:luke <name> "Luke Skywalker" .
_:leia <name> "Princess Leia" .
_:han <name> "Han Solo" .
_:lucas <name> "George Lucas" .
_:irvin <name> "Irvin Kernshner" .
_:richard <name> "Richard Marquand" .
_:sw1 <name> "Star Wars: Episode IV - A New Hope" .
_:sw1 <release_date> "1977-05-25" .
_:sw1 <revenue> "775000000" .
_:sw1 <running_time> "121" .
_:sw1 <starring> _:luke .
_:sw1 <starring> _:leia .
_:sw1 <starring> _:han .
_:sw1 <director> _:lucas .
_:sw2 <name> "Star Wars: Episode V - The Empire Strikes Back" .
_:sw2 <release_date> "1980-05-21" .
_:sw2 <revenue> "534000000" .
_:sw2 <running_time> "124" .
_:sw2 <starring> _:luke .
_:sw2 <starring> _:leia .
_:sw2 <starring> _:han .
_:sw2 <director> _:irvin .
_:sw3 <name> "Star Wars: Episode VI - Return of the Jedi" .
_:sw3 <release_date> "1983-05-25" .
_:sw3 <revenue> "572000000" .
_:sw3 <running_time> "131" .
_:sw3 <starring> _:luke .
_:sw3 <starring> _:leia .
_:sw3 <starring> _:han .
_:sw3 <director> _:richard .
_:st1 <name> "Star Trek: The Motion Picture" .
_:st1 <release_date> "1979-12-07" .
_:st1 <revenue> "139000000" .
_:st1 <running_time> "132" .
}
}点击“Run”
再输入如下内容,添加schema:
mutation {
schema {
name: string @index .
release_date: date @index .
revenue: float .
running_time: int .
}
}点击“Run”
现在可以查询了,输入如下内容可以查询名称为星球大战并且在1980年后发行的电影:
{
me(func:allofterms(name, "Star Wars")) @filter(ge(release_date, "1980")) {
name
release_date
revenue
running_time
director {
name
}
starring {
name
}
}
}哎哟,不错哦,页面挺漂亮的。这小清新的配色比neo4j和cayley好看多了。
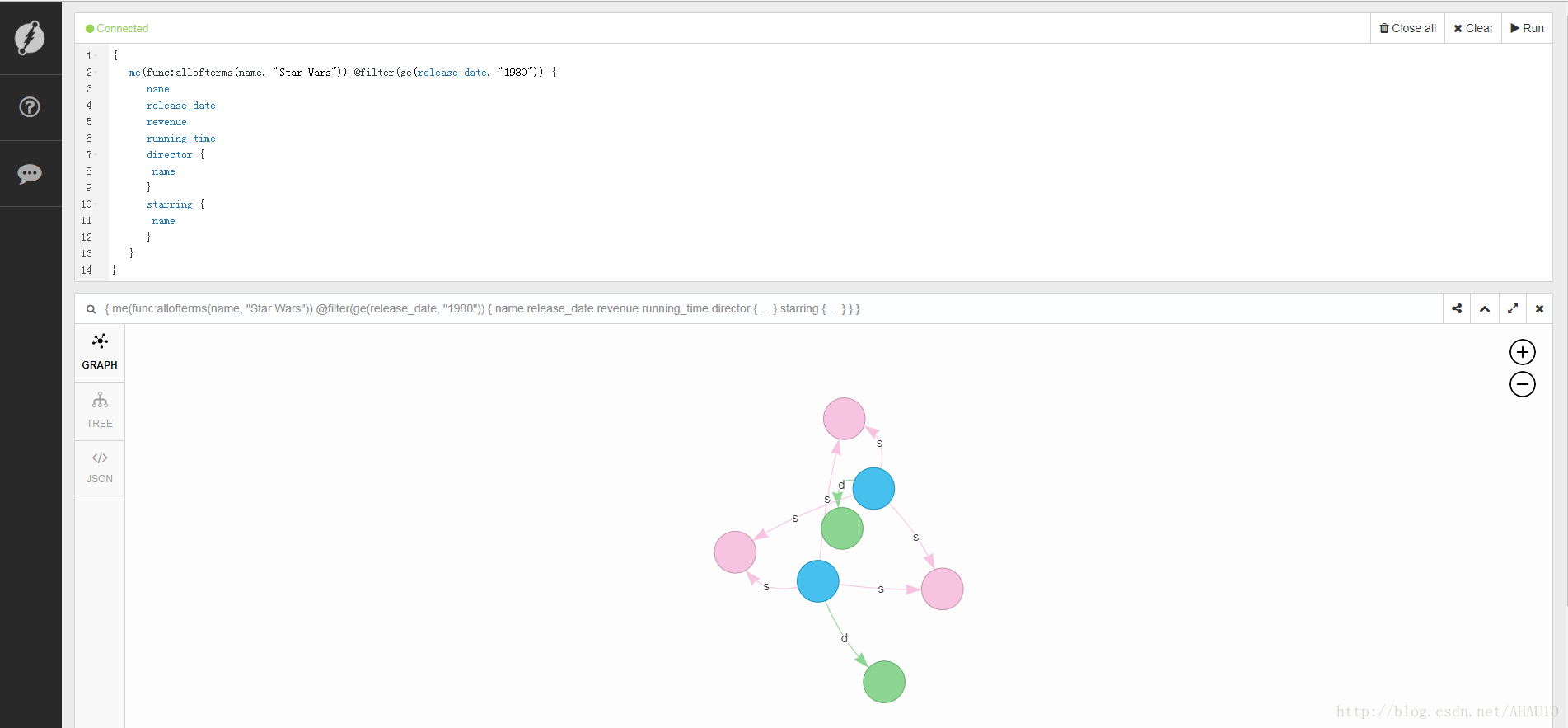
咦?才提交了这么一点数据,有这么多边吗?
不像neo4j, dgraph的vertex里没有property这概念。所有的property都是边。
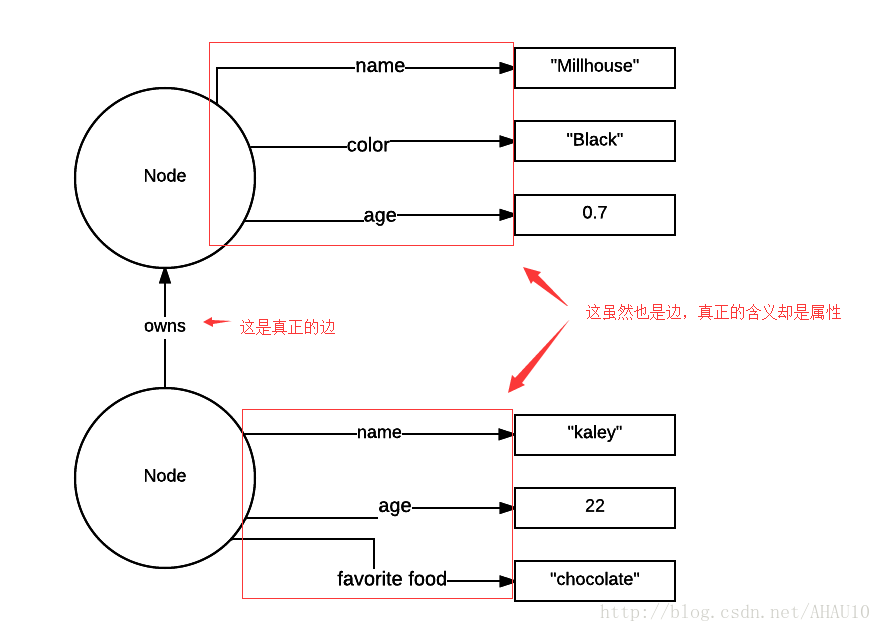
不要觉得这很傻。在stackoverflow上看到有人问如何让vertex的属性支持多值?有不少人都说了,给vertex添加多条边。用这种办法让vertex支持多值。
而且据我所知,添加边和查边的时候比属性快一些。别以为查边很慢,有邻接表和其它的策略,查边是非常快的。要不然图数据的优势怎么体现出来?
虽然直接在vertex里添加属性更直观一些。我相信dgraph这样做一定是考虑了很多因素的。别忘了dgraph比neo4j出来的晚,是有后发优势的。
dgraph是支持分片的。在微博上看到有人说dgraph是通过边来切图的。图数据库分片是个NP完全的问题。目前没有非常好的切图策略。
不管dgraph怎么实现分片的。至少人家是支持分片的。而且是底层设计上就考虑了分片的。
dgraph还有一个问题,就是需要你自己维护主键唯一性。上面的mutation操作中,
_:luke是一个伪id。 dgraph内部会为你生成一个唯一的id。如果你想通过id就能把这个vertex查出来,然后更新之。那么需要你自己去维护id的唯一性。 dgraph的设计理念是尽量保持简单(赞同)。 所以现在的问题是导数据的时候想更新节点可能没那么容易了。 mutation中每一句结尾的 “.”,相当于SQL里的分号。
我想通过全文检索把节点查出来怎么办?dgraph支持fulltext索引,不过很可惜,目前不支持中文。如果它是用java写的,那么我们可以快速的添加一个smartcn或者IK。但是人家使用go语言写的。哪位大神能搞一个go语言的中文分词,在此先行谢过。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)