
拒绝采样(reject sampling)原理详解
蒙特·卡罗方法(Monte Carlo method)也称统计模拟方法,通过重复随机采样模拟对象的概率与统计的问题,在物理、化学、经济学和信息技术领域均具有广泛应用。拒绝采样(reject sampling)就是针对复杂问题的一种随机采样方法。
蒙特·卡罗方法(Monte Carlo method)也称统计模拟方法,通过重复随机采样模拟对象的概率与统计的问题,在物理、化学、经济学和信息技术领域均具有广泛应用。拒绝采样(reject sampling)就是针对复杂问题的一种随机采样方法。
首先举一个简单的例子介绍Monte Carlo方法的思想。假设要估计圆周率
π
π
的值,选取一个边长为1的正方形,在正方形内作一个内切圆,那么我们可以计算得出,圆的面积与正方形面积之比为
π/4
π
/
4
。现在在正方形内随机生成大量的点,如图1所示,落在圆形区域内的点标记为红色,在圆形区域之外的点标记为蓝色,那么圆形区域内的点的个数与所有点的个数之比,可以认为近似等于
π/4
π
/
4
。因此,Monte Carlo方法是通过随机采样的方式,以频率估计概率。
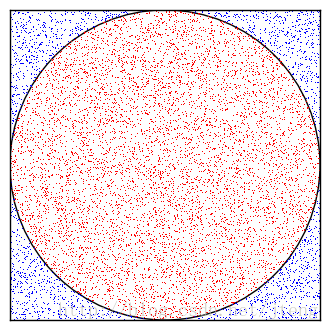
图1 Monte Carlo方法估计 π π 的值
简单分布的采样,如均匀分布、高斯分布、Gamma分布等,在计算机中都已经实现,但是对于复杂问题的采样,就需要采取一些策略, 拒绝采样就是一种基本的采样策略,其采样过程如下。
给定一个概率分布 p(z)=1Zpp̃ (z) p ( z ) = 1 Z p p ~ ( z ) ,其中, p̃ (z) p ~ ( z ) 已知, Zp Z p 为归一化常数,未知。要对该分布进行拒绝采样,首先借用一个简单的参考分布(proposal distribution),记为 q(x) q ( x ) ,该分布的采样易于实现,如均匀分布、高斯分布。然后引入常数 k k ,使得对所有的的,满足 kq(z)≥p̃ (z) k q ( z ) ≥ p ~ ( z ) ,如图2所示,红色的曲线为 p̃ (z) p ~ ( z ) ,蓝色的曲线为 kq(z) k q ( z ) 。在每次采样中,首先从 q(z) q ( z ) 采样一个数值 z0 z 0 ,然后在区间 [0,kq(z0)] [ 0 , k q ( z 0 ) ] 进行均匀采样,得到 u0 u 0 。如果 u0<p̃ (z0) u 0 < p ~ ( z 0 ) ,则保留该采样值,否则舍弃该采样值。最后得到的数据就是对该分布的一个近似采样。
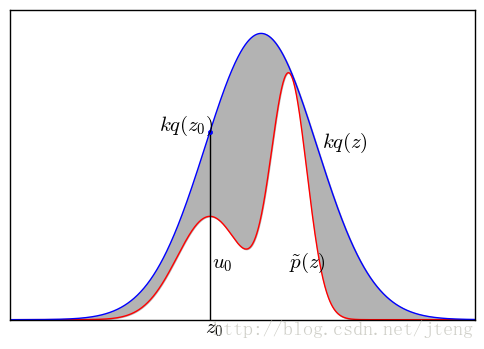
图2 拒绝采样示例
每次采样的接受概率计算如下:
p(accept)=∫p̃ (z)kq(z)q(z)dz=1k∫p̃ (z)dz p ( a c c e p t ) = ∫ p ~ ( z ) k q ( z ) q ( z ) d z = 1 k ∫ p ~ ( z ) d z
所以,为了提高接受概率,防止舍弃过多的采样值而导致采样效率低下, k k 的选取应该在满足的基础上尽可能小。
拒绝采样问题可以这样理解,
p̃ (z)
p
~
(
z
)
与
x
x
轴之间的区域为要估计的问题,类似于上面提到Monte Carlo方法中的圆形区域,与
x
x
轴之间的区域为参考区域,类似于上面提到的正方形。由于与
x
x
轴之间的区域面积为k,所以,与
x
x
轴之间的区域面积除以k即为对的估计。在每一个采样点,以
[0,kq(z0)]
[
0
,
k
q
(
z
0
)
]
为界限,落在
p̃ (z)
p
~
(
z
)
曲线以下的点就是服从
p(z)
p
(
z
)
分布的点。
针对图2的例子,我们对其进行拒绝采样。图中,要采样的分布为
p̃ (z)=0.3exp(−(z−0.3)2)+0.7exp(−(z−2)2/0.3)
p
~
(
z
)
=
0.3
e
x
p
(
−
(
z
−
0.3
)
2
)
+
0.7
e
x
p
(
−
(
z
−
2
)
2
/
0.3
)
其归一化常数
Zp≈1.2113
Z
p
≈
1.2113
,参考分布为高斯分布
q(z)=Gassian(1.4,1.2)
q
(
z
)
=
G
a
s
s
i
a
n
(
1.4
,
1.2
)
,其中均值和方差是经过计算和尝试得到的,以满足
kq(z)≥p̃ (z)
k
q
(
z
)
≥
p
~
(
z
)
,贴上python代码。
import numpy as np
import matplotlib.pyplot as plt
def f1(x):
return (0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3))/1.2113
x = np.arange(-4.,6.,0.01)
plt.plot(x,f1(x),color = "red")
size = int(1e+07)
sigma = 1.2
z = np.random.normal(loc = 1.4,scale = sigma, size = size)
qz = 1/(np.sqrt(2*np.pi)*sigma)*np.exp(-0.5*(z-1.4)**2/sigma**2)
k = 2.5
#z = np.random.uniform(low = -4, high = 6, size = size)
#qz = 0.1
#k = 10
u = np.random.uniform(low = 0, high = k*qz, size = size)
pz = 0.3*np.exp(-(z-0.3)**2) + 0.7* np.exp(-(z-2.)**2/0.3)
sample = z[pz >= u]
plt.hist(sample,bins=150, normed=True, edgecolor='black')
plt.show()得到的采样分布如下图:
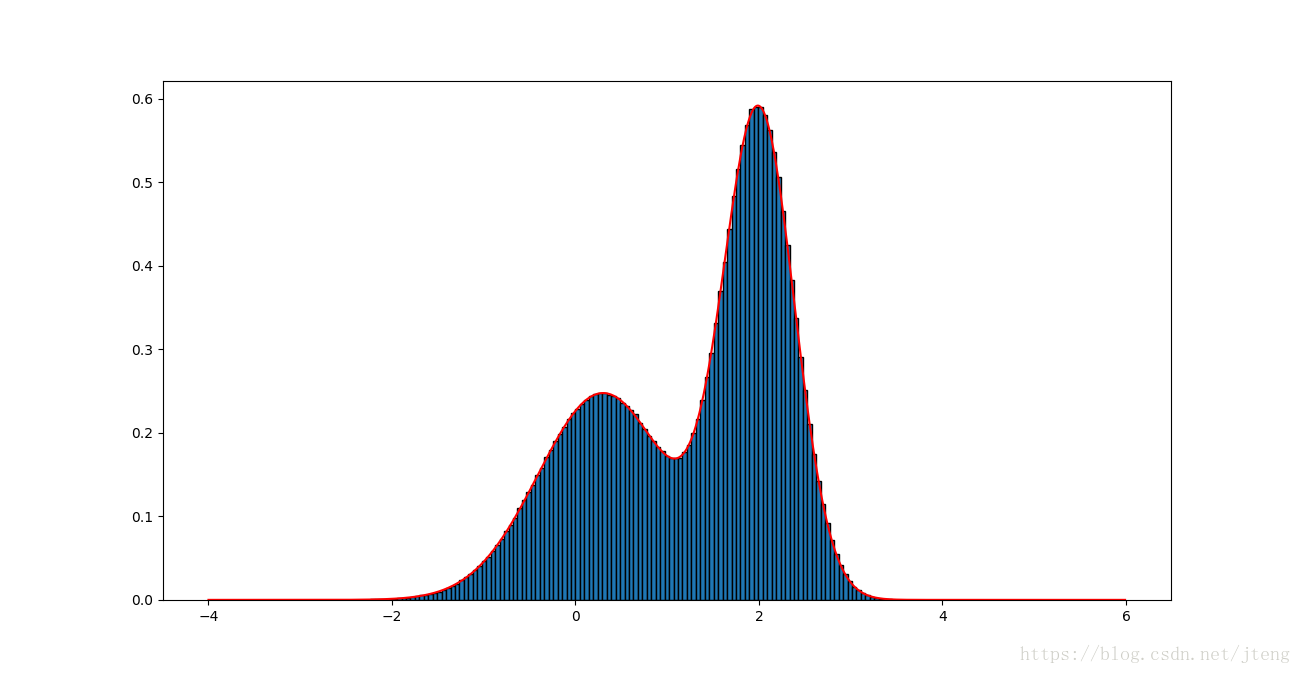
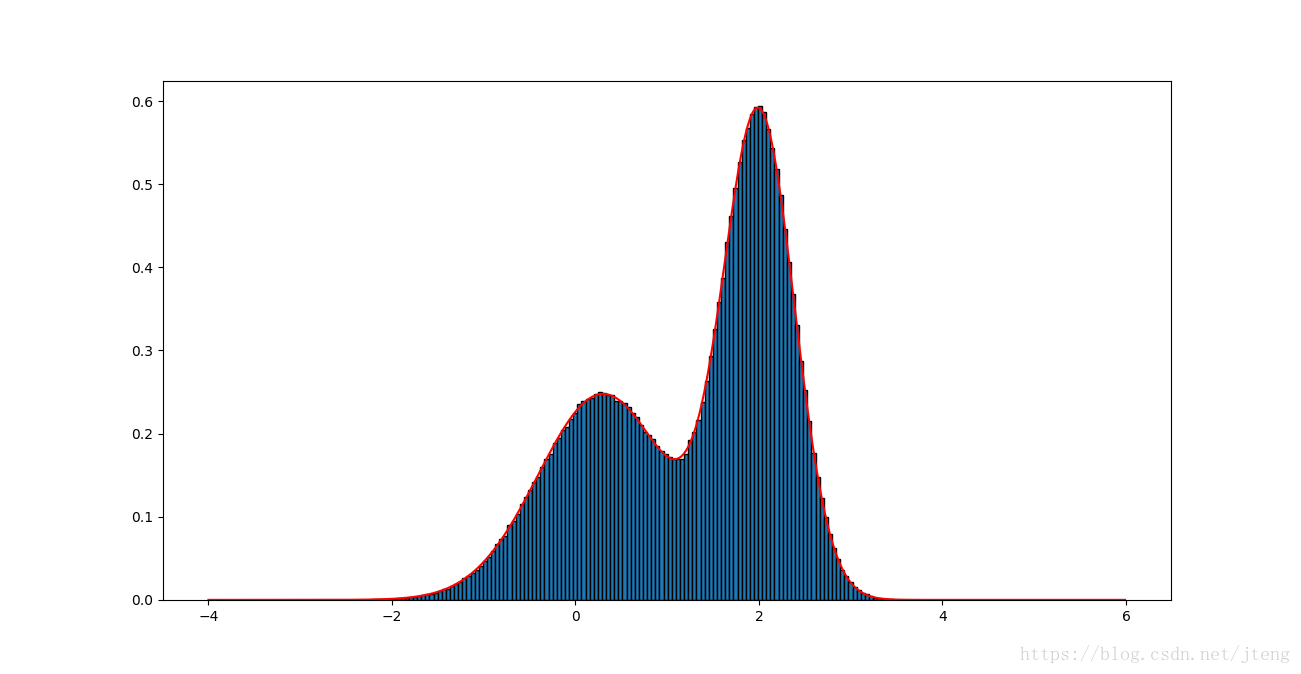
可以看到,采样结果完全符合原分布。另外把参考分布换为均匀分布(代码中z,q,k换为注释部分),仍然得到较好的采样结果,如下图:
最后附上生成图2的代码
import numpy as np
import matplotlib.pyplot as plt
def f1(x):
return 0.3*np.exp(-(x-0.3)**2) + 0.7* np.exp(-(x-2.)**2/0.3)
def f2(x):
sigma =1.2
return 2.5/(np.sqrt(2*np.pi)*sigma)*np.exp(-0.5*(x-1.4)**2/sigma**2)
x = np.arange(-4.,6.,0.01)
plt.plot(x,f1(x),color = "red")
plt.plot(x,f2(x),color = "blue")
plt.xticks([])
plt.yticks([])
plt.ylim(0,0.9)
plt.xlim(-4,6)
plt.plot([0.3,0.3],[0,0.54601532],color = "black")
plt.plot(0.3,0.54601532,'b.')
plt.fill_between(x,f1(x),f2(x),color = (0.7,0.7,0.7))
plt.annotate('$z_0$',xy=(0.,0),xytext=(0.2,-0.04),fontsize=15)
plt.annotate('$u_0$',xy=(0.,0.),xytext=(0.35,0.15),fontsize=15)
plt.annotate('$kq(z_0)$',xy=(0.,0.),xytext=(-0.8,0.55),fontsize=15)
plt.annotate('$p(z)$',xy=(0.,0.),xytext=(2,0.15),fontsize=15)
plt.annotate('$kq(z)$',xy=(0.,0.),xytext=(2.7,0.5),fontsize=15)
plt.show()
旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 42
42 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)