
Kylin 的架构和原理
1. Kylin的设计思想1.1 与其他开源大数据框架设计思想的对比解决大数据不断增长中高速查询的能力。怎么保证随着数据量的增长,怎么保证在未来的数据查询性能不受影响。从算法角度讲,现有的大数据框架可分为以下几类:1.并行计算:mapreduce、spark2.列式存储:parquet,节省IO3.(倒排)索引:节省IO这三种在集群规模不变的情况下,随着数据的无限增长,查
1. Kylin的设计思想
1.1 与其他开源大数据框架设计思想的对比
解决大数据不断增长中高速查询的能力。
怎么保证随着数据量的增长,怎么保证在未来的数据查询性能不受影响。
从算法角度讲,现有的大数据框架可分为以下几类:
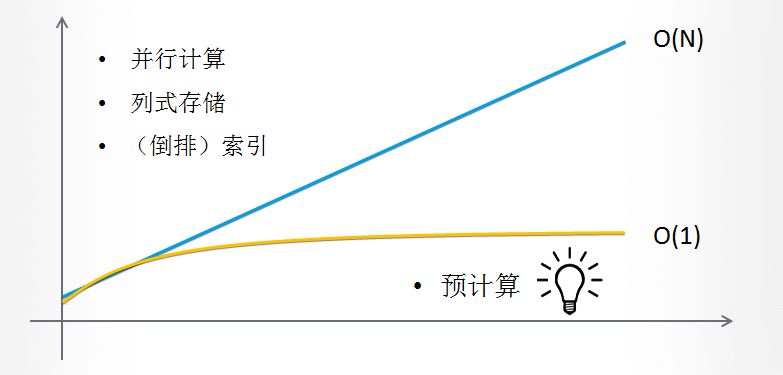
1.并行计算:mapreduce、spark
2.列式存储:parquet,节省IO
3.(倒排)索引:节省IO
这三种在集群规模不变的情况下,随着数据的无限增长,查询性能也会线性的下降。比如,数据增长十倍,查询意味着我们扫描的数据量也增长了十倍,这就必然影响查询的效率。从算法时间复杂度讲,还是一个O(N)的问题,解决这个问题,Kylin提出来预计算的思路。
4.预计算:事先将增长的数据量在离线的情况做完,那么用户再来查询的时就可以减少工作量。
1.2 Kylin预计算思想的具体细节
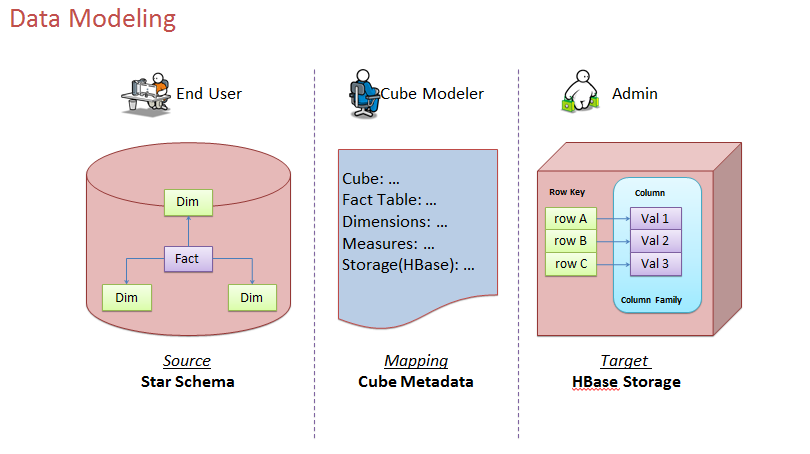
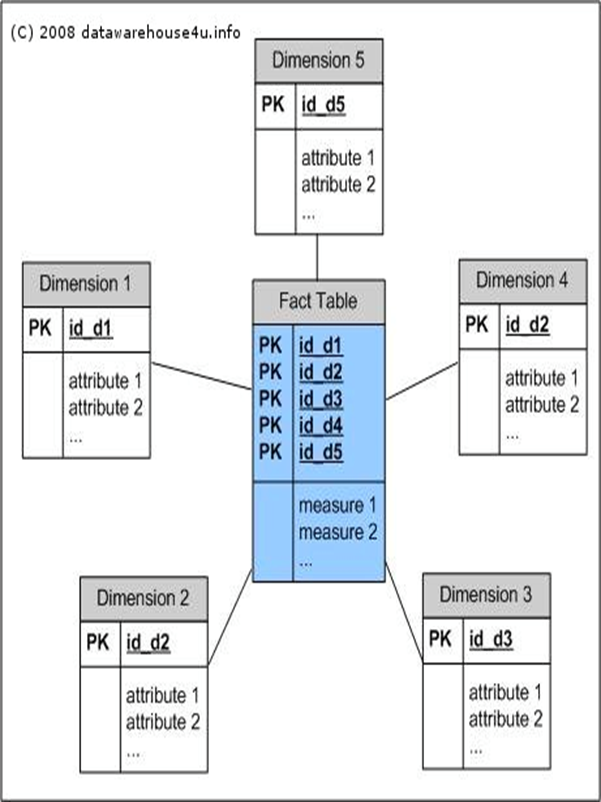
数据建模,这对Kylin用户来说是最重要的工作。
使用关系数据库模型中的星型模型
模型决定了预计算的边界,给定了预计算的范围,内容。从而穷尽所有的计算量,实现预计算。
cube模型:多维立方体理论
有事实表,维度,度量,定义了维度和度量之后就可以做各种维度的排列组合和预计算,
预计算的结果存储在Hbase中,用户查询的结果直接从cube中反馈
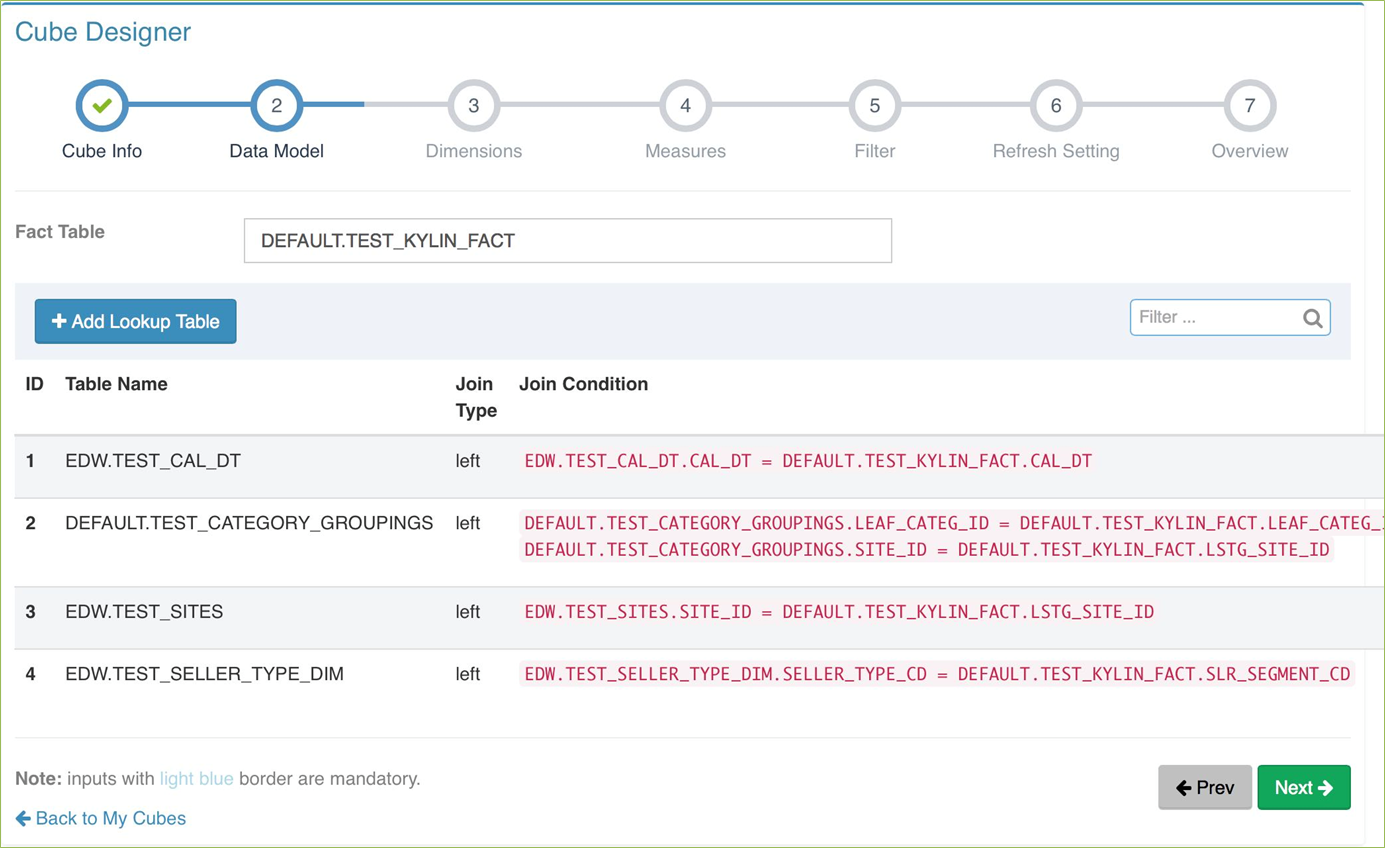
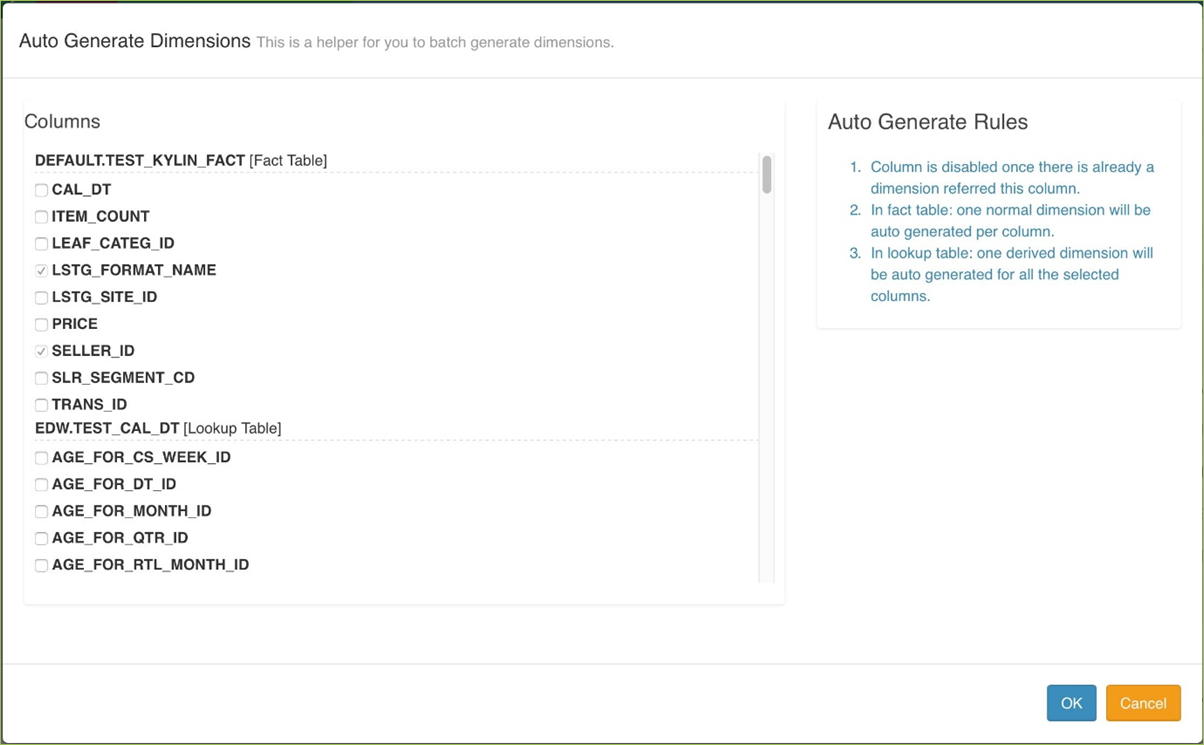
cube的设计:
cube的设计过程示例:
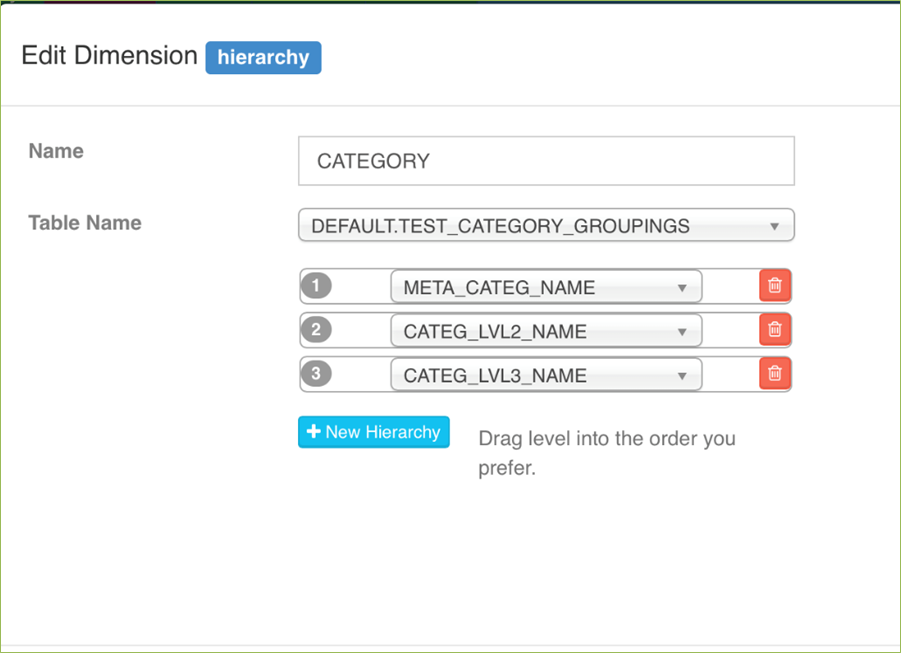
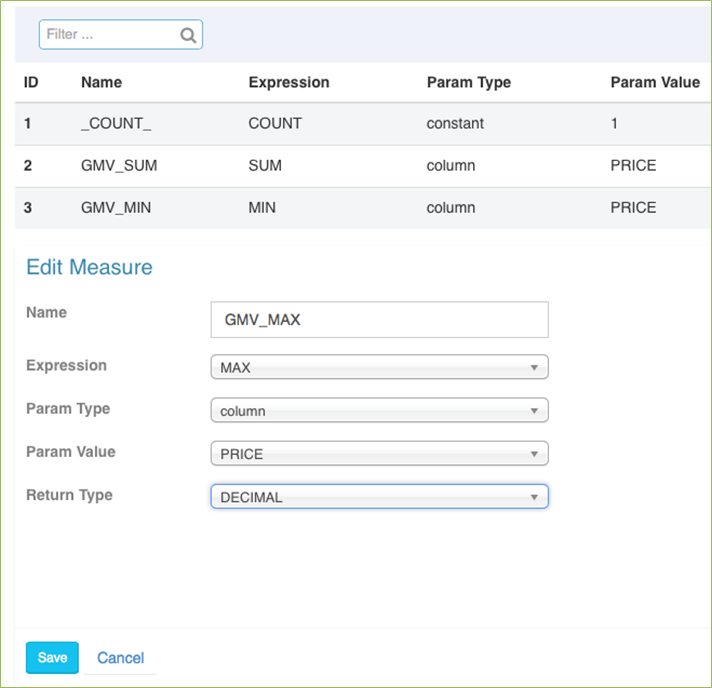
另外Kylin还提供了工作管理、web查询界面以及简单的可视化。可视化方面Kylin可以与Tableu集成。
Kylin特性:高并发,低延迟。
2. 工作原理
目标:提供稳定的大数据查询
2.1 引言:物化视图
一个常用的3维立方体,包含:时间、地点、产品
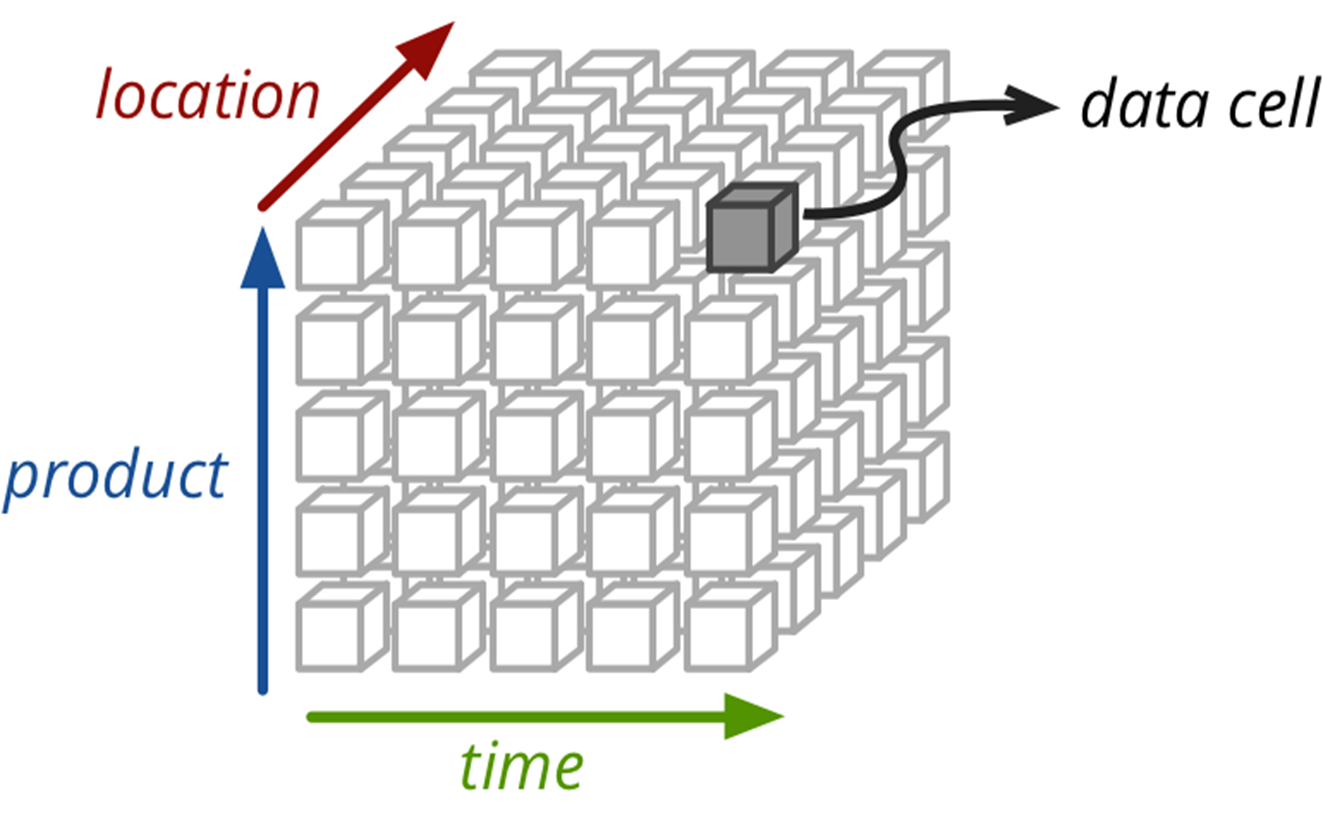
Cuboid = one combination of dimensions
Cube = all combination of dimensions (all cuboids)
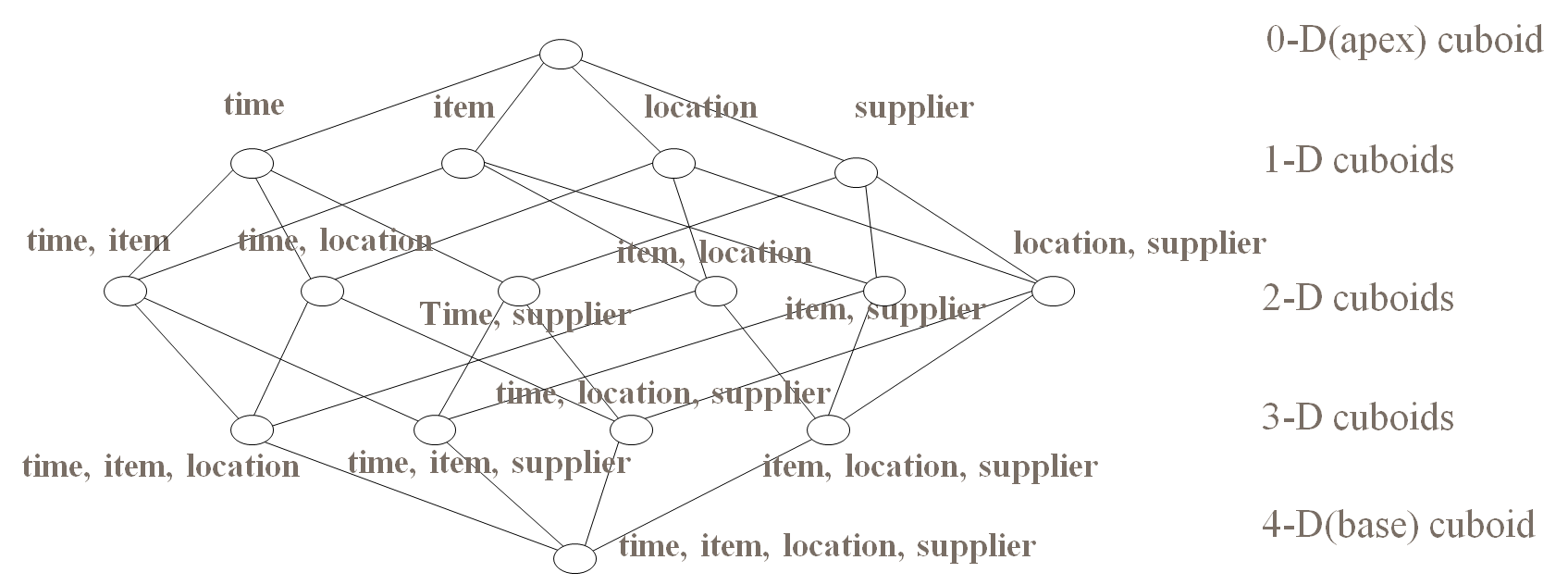
Base vs. aggregate cells; ancestor vs. descendant cells; parent vs. child cells
(9/15, milk, Urbana, Dairy_land) - <time, item, location, supplier>
(9/15, milk, Urbana, *) - <time, item, location>
(*, milk, Urbana, *) - <item, location>
(*, milk, Chicago, *) - <item, location>
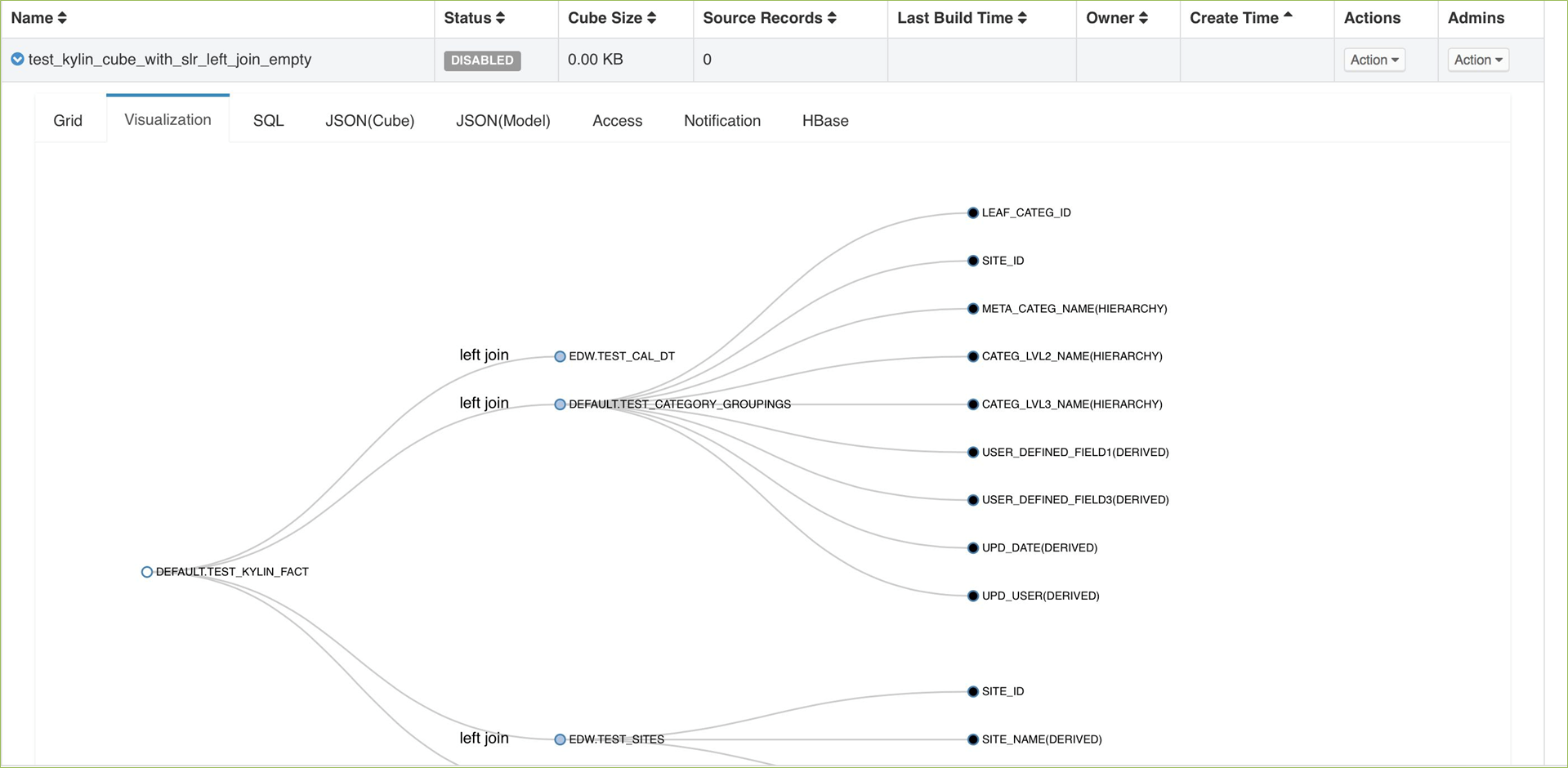
(*, milk, *, *) - <item>2.2 Kylin的架构
数据源:hive or kafka
计算框架:mapreduce、spark,目前主要用mapreduce,因为spark和mapreduce性能差不多。
结果:存储在HBase中
对外查询接口:REST、JDBC、ODBC
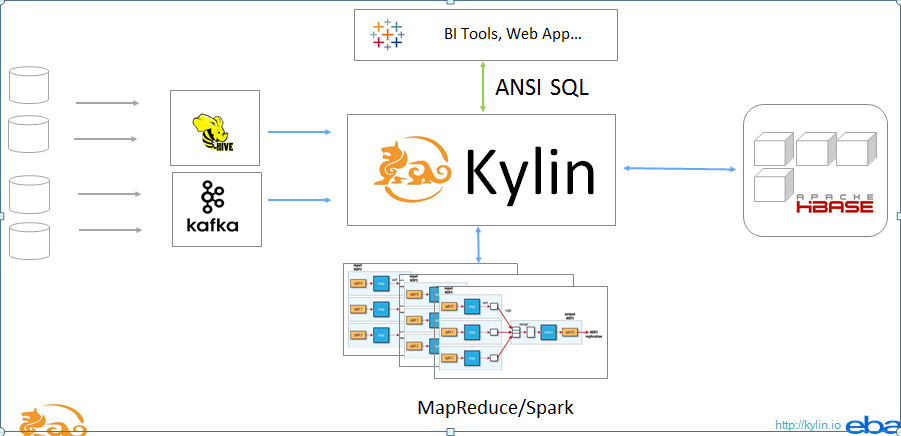
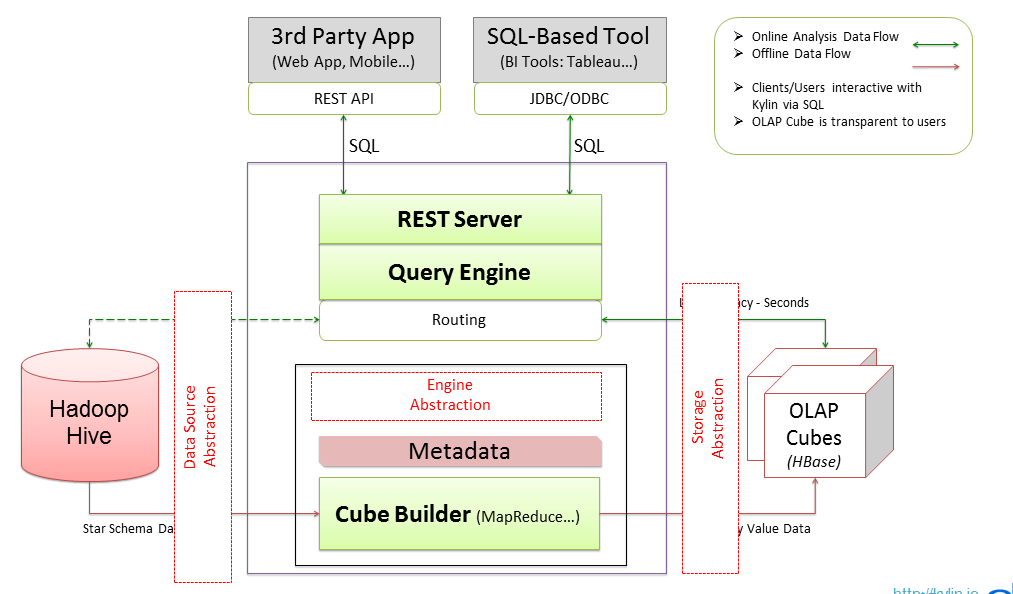
2.3 cube构建工作流
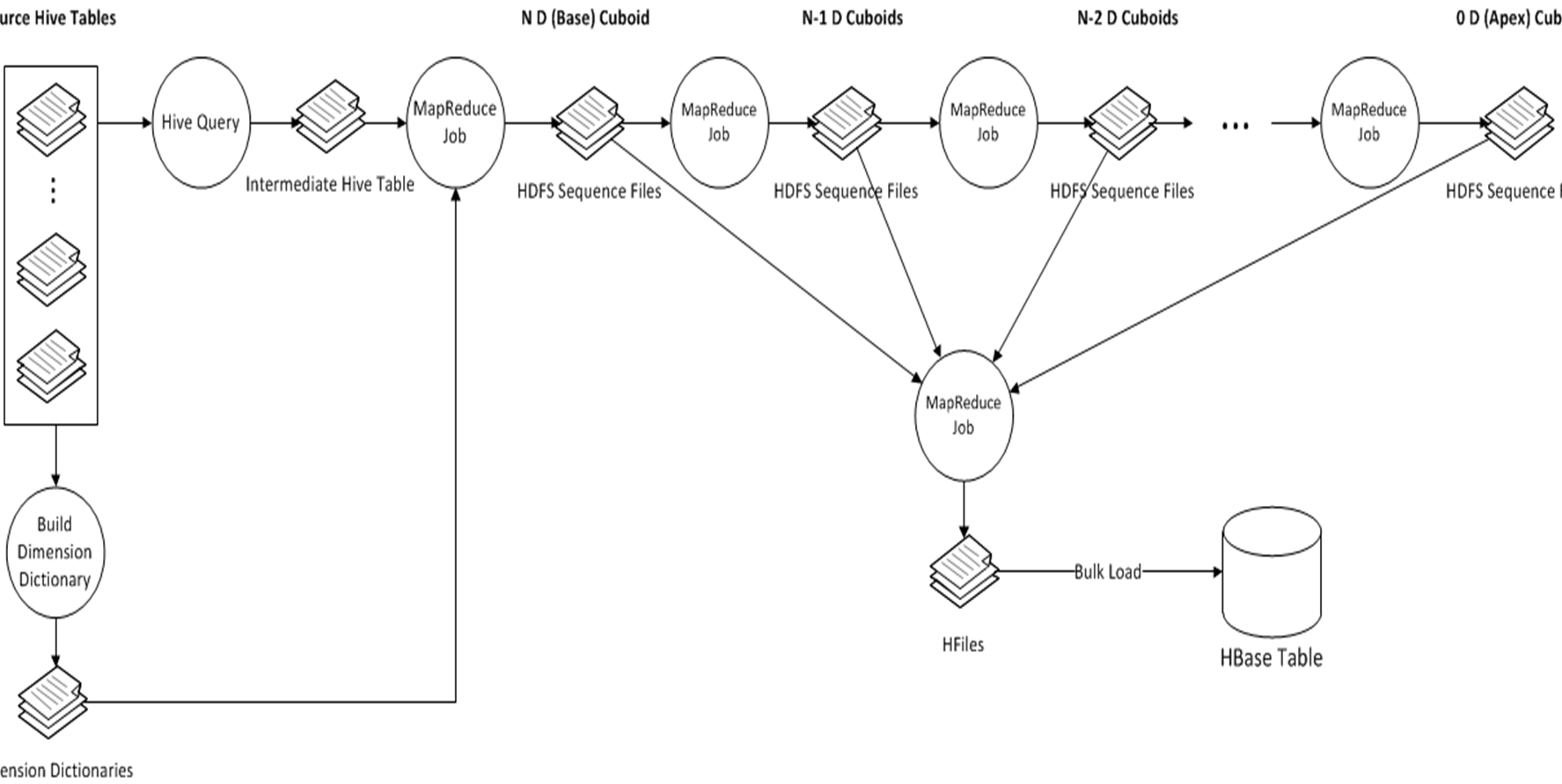
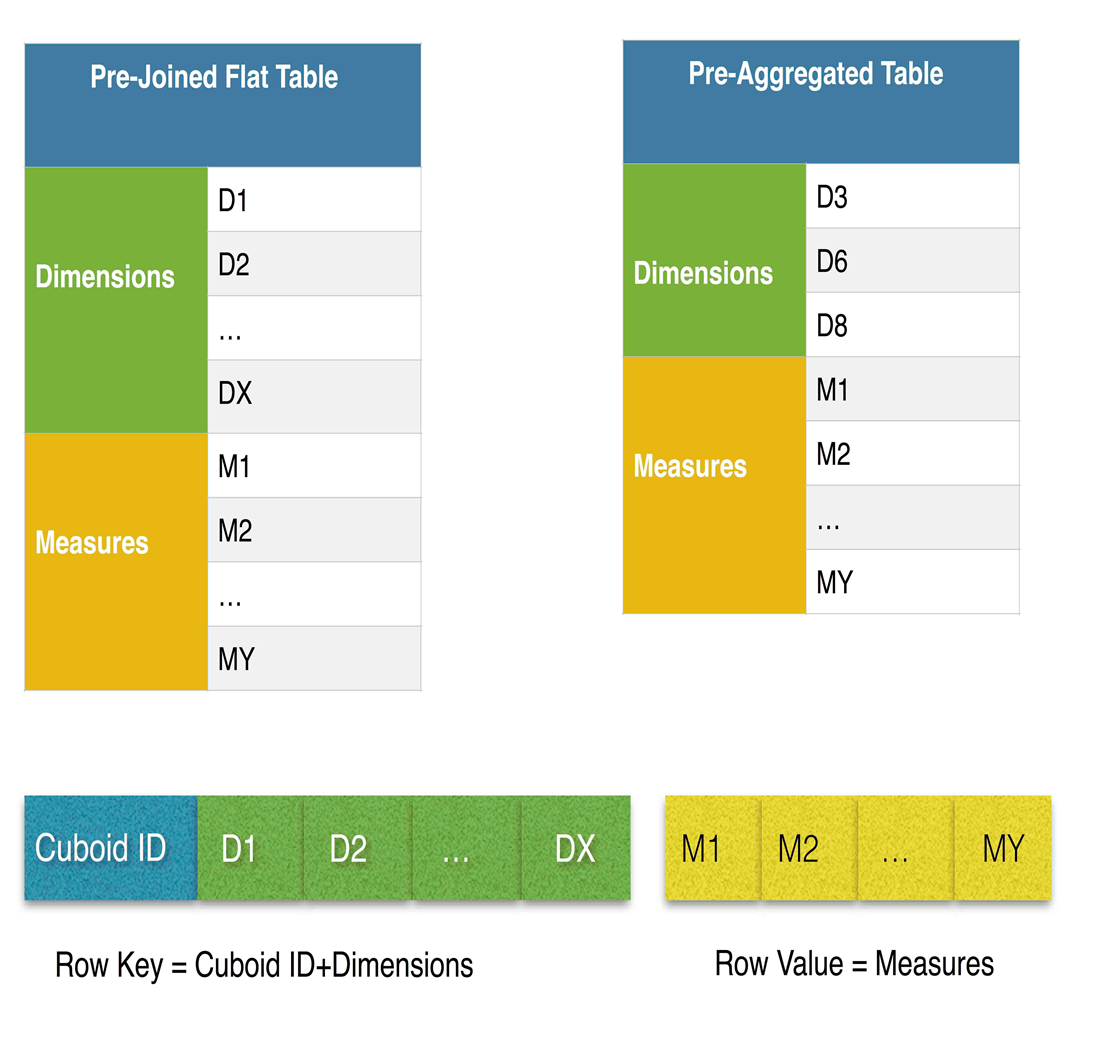
2.4 cube存储
2.5 Kylin的查询引擎:Calcite
关于Calcite的简介:http://www.infoq.com/cn/articles/new-big-data-hadoop-query-engine-apache-calcite
Calcite的apche社区:http://calcite.apache.org/
Calcite架构
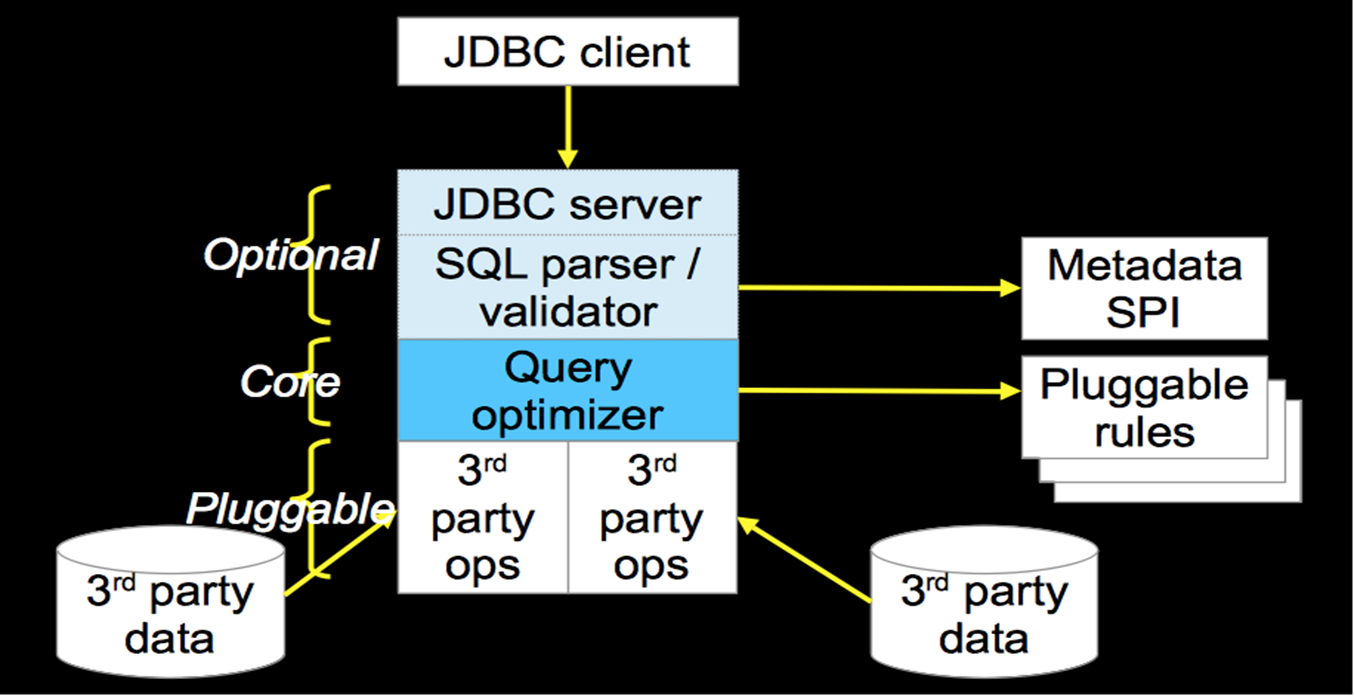
Kylin对Calcite的优化
3. 调优
3.3 增量构建
4. 1.6版本新特性
可以接入kafka数据源,可以按分钟做增量构建

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)