深度学习笔记2:反向传播算法
1、损失函数 损失函数在统计学中是一种衡量损失和误差程度的函数,它一般包括损失项(loss term)和正则项(regularization term)。 损失项 损失项比较常见的有平方损失,常用在回归问题;以及对数损失函数,常用在分类问题。 正则项 加入正则项目的是减小权重的幅度,防止过度拟合。常用的有L1-r
1、损失函数
损失函数在统计学中是一种衡量损失和误差程度的函数,它一般包括损失项(loss term)和正则项(regularization term)。

损失项
损失项比较常见的有平方损失,常用在回归问题;以及对数损失函数
,常用在分类问题。
正则项
加入正则项目的是减小权重的幅度,防止过度拟合。常用的有L1-regularization和L2-regularization。
关于损失函数发现一篇文章讲的比较详细,看一下能比较详细的了解损失函数:点击打开链接
2、BackPropagation算法
BackPropagation算法是多层神经网络的训练中举足轻重的算法,简单的理解,它就是复合函数的链式法则。由于后面我的网络中会用到对数损失函数,所以在这里我们使用平方损失函数。对于单个样例,其平方损失函数为:
对于给定一个包含m个样例的数据集,我们可以定义整体代价函数为:

和直线的拟合类似,深度学习也有一个目标函数,通过这个目标函数我们可以知道参数为何值时对我们来说才是一组“好”的参数,这个函数就是前边提到的损失函数。训练的过程就是通过每一次迭代对网络中参数进行更新,来使损失函数的值达到最小(下图中α为学习率)。

虽然一般损失函数都是非凸的,含有局部最小值,但实际使用中一般都不会下降到局部最小值。
3、利用BackPropagation算法计算偏导数
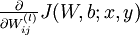

BP算法的整体思路如下:对于每个给定的训练样本,首先进行前向计算,计算出网络中每一层的激活值和网络的输出。对于最后一层(输出层),我们可以直接计算出网络的输出值与已经给出的标签值(label)直接的差距,我们将这个值定义为残差δ。对于输出层之前的隐藏层L,我们将根据L+1层各节点的加权平均值来计算第L层的残差。
插入一些我个人对BP算法的一点比较容易理解的解释(如有错误请指出):在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。不管下面的公式推导,还是后面的卷积神经网络,在反向传播的过程中,都是遵循这样的一个规律。
反向传播的具体步骤如下:
(1)根据输入,计算出每一层的激活值。
(2)对于输出层,我们使用如下公式计算每个单元的残差:

(3)对于输出层之前的每一层,按照如下公式计算每一层的残差:

(4)由残差计算每一层的偏导数:

(5)最后,使用偏导数更新权值和偏置。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)