马尔科夫链原理简介及应用
马尔科夫链原理简介及应用0 评论马尔科夫链作为解释复杂时间进程的一个简单概念,在语音识别、文本标识、路径辨识等众多人工智能领域有广泛应用。本文对离散马尔科夫链的基本原理即应用做简要介绍。马尔可夫链为状态空间中从一个状态到另一个状态转换的随机过程。该过程要求具备“无记忆”的性质:即已知现在状态,将来状态与过去状态相互独立。这种特定类型的“无记忆性”称作
马尔科夫链原理简介及应用

马尔科夫链作为解释复杂时间进程的一个简单概念,在语音识别、文本标识、路径辨识等众多人工智能领域有广泛应用。本文对离散马尔科夫链的基本原理即应用做简要介绍。
马尔可夫链为状态空间中从一个状态到另一个状态转换的随机过程。该过程要求具备“无记忆”的性质:即已知现在状态,将来状态与过去状态相互独立。这种特定类型的“无记忆性”称作马尔可夫性质。在马尔可夫链的每一步,系统根据条件概率保持现有状态或转为其他状态。状态的改变叫做转移,状态改变概率称为转移概率。
为建立直观的概念,我们考虑这样一个简单的例子: 可口、百事是某一城市的仅有的两家饮料公司。某一苏打水公司打算与其中一家建立合同关系。为了解两家公司在一个月后的市场份额占比情况,该苏打水公司做了市场调研并得到如下结论:(1)市场份额占比,目前百事的市场份额为55%,而可口的市场份额为45%;(2)客户转换率(如下图1):其中百事客户下月依旧青睐百事的概率为70%记为P(P>-P),转为可口客户的概率为30% 记为P(P>-C);可口客户下个月依旧消费可口可乐的概率为90%记为P(C>-C),而转化为百事客户的概率为10%记为P(C>-P)。这些数据可形成百事和可口的市场份额转化矩阵。在进行下个月的市场份额预测时,只需要进行如下计算:
百事市场份额(t+1)=百事目前市场份额(t)*P(P>-P)+可口目前市场份额(t)* P(C>-P)
可口市场份额(t+1)=可口目前市场份额(t)*P(C>-C)+百事目前市场份额(t)* P(P>-C)

以上计算可采用市场份额转移矩阵概念进行矩阵化运算如下式:

从计算结果看,虽然百事目前的市场份额较大,但一个月后将会被可口超越。如果市场份额转移概率并不发生改变,可按照相同方法计算未来数月百事和可口公司市场份额,例如采用下一个月的市场份额和市场份额转移矩阵来计算两个月后两公司的市场份额情况。

如果苏打水公司需要计算百事公司和可口公司的长期市场份额占有情况的差异,并制定合理供给策略,那么则需要按照以下方程来计算两公司的稳定市场份额情况。
百事稳定市场份额* P(P>-C)=可口稳定市场份额* P(C>-P)
百事稳定市场份额+可口稳定市场份额=1
除上述简单马尔科夫过程外,在实际案例中应用较多为隐马尔可夫模型(Hidden Markov Model),它用来描述一个含有隐含未知参数的马尔可夫过程。在隐马尔科夫模型中,状态并不是直接可见的,但受状态影响的某些变量可见,需要通过可见变量推测状态变化。 马尔科夫过程的应用极为广泛,从信号科学的熵编码技术到生物的增值过程,从地理统计学到网页排序法,从模仿文本生成到音乐的制作,都有马尔科夫的影子。在文章的最后,简单介绍一下Google对马尔科夫过程的应用:
-
HTTP服务请求预测:Google 依据用户即将访问某一界面的概率提前准备好该界面以提高查询速度。
-
关键词集群识别:将关键词按不同集群分类,并根据关键词集群确定用户未来搜索路径。

-
检索推荐:根据用户行为自动为用户推荐链接和检索
-
评分:根据马尔科夫链可确定权威搜索模式,判定用户的搜索行为。
隐马尔可夫(HMM)好讲,简单易懂不好讲。我想说个更通俗易懂的例子。我希望我的读者不是专家,而是对这个问题感兴趣的入门者,所以我会多阐述数学思想,少写公式。霍金曾经说过,你多写一个公式,就会少一半的读者。所以时间简史这本关于物理的书和麦当娜关于性的书卖的一样好。我会效仿这一做法,写最通俗易懂的答案。
还是用最经典的例子,掷骰子。假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。

假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
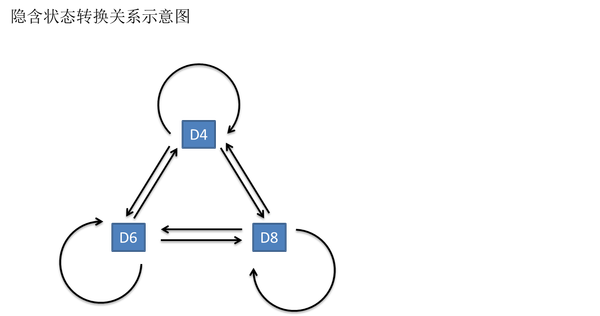
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。

其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
和HMM模型相关的算法主要分为三类,分别解决三种问题:
1)知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道每次掷出来的都是哪种骰子(隐含状态链)。
这个问题呢,在语音识别领域呢,叫做解码问题。这个问题其实有两种解法,会给出两个不同的答案。每个答案都对,只不过这些答案的意义不一样。第一种解法求最大似然状态路径,说通俗点呢,就是我求一串骰子序列,这串骰子序列产生观测结果的概率最大。第二种解法呢,就不是求一组骰子序列了,而是求每次掷出的骰子分别是某种骰子的概率。比如说我看到结果后,我可以求得第一次掷骰子是D4的概率是0.5,D6的概率是0.3,D8的概率是0.2.第一种解法我会在下面说到,但是第二种解法我就不写在这里了,如果大家有兴趣,我们另开一个问题继续写吧。
2)还是知道骰子有几种(隐含状态数量),每种骰子是什么(转换概率),根据掷骰子掷出的结果(可见状态链),我想知道掷出这个结果的概率。
看似这个问题意义不大,因为你掷出来的结果很多时候都对应了一个比较大的概率。问这个问题的目的呢,其实是检测观察到的结果和已知的模型是否吻合。如果很多次结果都对应了比较小的概率,那么就说明我们已知的模型很有可能是错的,有人偷偷把我们的骰子給换了。
3)知道骰子有几种(隐含状态数量),不知道每种骰子是什么(转换概率),观测到很多次掷骰子的结果(可见状态链),我想反推出每种骰子是什么(转换概率)。
这个问题很重要,因为这是最常见的情况。很多时候我们只有可见结果,不知道HMM模型里的参数,我们需要从可见结果估计出这些参数,这是建模的一个必要步骤。
问题阐述完了,下面就开始说解法。(0号问题在上面没有提,只是作为解决上述问题的一个辅助)
0.一个简单问题
其实这个问题实用价值不高。由于对下面较难的问题有帮助,所以先在这里提一下。
知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,根据掷骰子掷出的结果,求产生这个结果的概率。
 解法无非就是概率相乘:
解法无非就是概率相乘:

1.看见不可见的,破解骰子序列
这里我说的是第一种解法,解最大似然路径问题。
举例来说,我知道我有三个骰子,六面骰,四面骰,八面骰。我也知道我掷了十次的结果(1 6 3 5 2 7 3 5 2 4),我不知道每次用了那种骰子,我想知道最有可能的骰子序列。
其实最简单而暴力的方法就是穷举所有可能的骰子序列,然后依照第零个问题的解法把每个序列对应的概率算出来。然后我们从里面把对应最大概率的序列挑出来就行了。如果马尔可夫链不长,当然可行。如果长的话,穷举的数量太大,就很难完成了。
另外一种很有名的算法叫做Viterbi algorithm. 要理解这个算法,我们先看几个简单的列子。
首先,如果我们只掷一次骰子:


看到结果为1.对应的最大概率骰子序列就是D4,因为D4产生1的概率是1/4,高于1/6和1/8.
把这个情况拓展,我们掷两次骰子:

结果为1,6.这时问题变得复杂起来,我们要计算三个值,分别是第二个骰子是D6,D4,D8的最大概率。显然,要取到最大概率,第一个骰子必须为D4。这时,第二个骰子取到D6的最大概率是

同样的,我们可以计算第二个骰子是D4或D8时的最大概率。我们发现,第二个骰子取到D6的概率最大。而使这个概率最大时,第一个骰子为D4。所以最大概率骰子序列就是D4 D6。
继续拓展,我们掷三次骰子:

同样,我们计算第三个骰子分别是D6,D4,D8的最大概率。我们再次发现,要取到最大概率,第二个骰子必须为D6。这时,第三个骰子取到D4的最大概率是

同上,我们可以计算第三个骰子是D6或D8时的最大概率。我们发现,第三个骰子取到D4的概率最大。而使这个概率最大时,第二个骰子为D6,第一个骰子为D4。所以最大概率骰子序列就是D4 D6 D4。
写到这里,大家应该看出点规律了。既然掷骰子一二三次可以算,掷多少次都可以以此类推。我们发现,我们要求最大概率骰子序列时要做这么几件事情。首先,不管序列多长,要从序列长度为1算起,算序列长度为1时取到每个骰子的最大概率。然后,逐渐增加长度,每增加一次长度,重新算一遍在这个长度下最后一个位置取到每个骰子的最大概率。因为上一个长度下的取到每个骰子的最大概率都算过了,重新计算的话其实不难。当我们算到最后一位时,就知道最后一位是哪个骰子的概率最大了。然后,我们要把对应这个最大概率的序列从后往前推出来。
2.谁动了我的骰子?
比如说你怀疑自己的六面骰被赌场动过手脚了,有可能被换成另一种六面骰,这种六面骰掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。你怎么办么?答案很简单,算一算正常的三个骰子掷出一段序列的概率,再算一算不正常的六面骰和另外两个正常骰子掷出这段序列的概率。如果前者比后者小,你就要小心了。
比如说掷骰子的结果是:
要算用正常的三个骰子掷出这个结果的概率,其实就是将所有可能情况的概率进行加和计算。同样,简单而暴力的方法就是把穷举所有的骰子序列,还是计算每个骰子序列对应的概率,但是这回,我们不挑最大值了,而是把所有算出来的概率相加,得到的总概率就是我们要求的结果。这个方法依然不能应用于太长的骰子序列(马尔可夫链)。
我们会应用一个和前一个问题类似的解法,只不过前一个问题关心的是概率最大值,这个问题关心的是概率之和。解决这个问题的算法叫做前向算法(forward algorithm)。
首先,如果我们只掷一次骰子:
看到结果为1.产生这个结果的总概率可以按照如下计算,总概率为0.18:

把这个情况拓展,我们掷两次骰子:
看到结果为1,6.产生这个结果的总概率可以按照如下计算,总概率为0.05:

继续拓展,我们掷三次骰子:
看到结果为1,6,3.产生这个结果的总概率可以按照如下计算,总概率为0.03:

同样的,我们一步一步的算,有多长算多长,再长的马尔可夫链总能算出来的。用同样的方法,也可以算出不正常的六面骰和另外两个正常骰子掷出这段序列的概率,然后我们比较一下这两个概率大小,就能知道你的骰子是不是被人换了。
3.掷一串骰子出来,让我猜猜你是谁
(答主很懒,还没写,会写一下EM这个号称算法的方法)
上述算法呢,其实用到了递归,逆向推导,循环这些方法,我只不过用很直白的语言写出来了。如果你们去看专业书籍呢,会发现更加严谨和专业的描述。毕竟,我只做了会其意,要知其形,还是要看书的。
之前上汉语语音课准备语音识别部分时一位朋友发给我的,作为理工科白痴我也看懂了。
1.题目背景:
从前有个村儿,村里的人的身体情况只有两种可能:健康或者发烧。
假设这个村儿的人没有体温计或者百度这种神奇东西,他唯一判断他身体情况的途径就是到村头我的偶像金正月的小诊所询问。
月儿通过询问村民的感觉,判断她的病情,再假设村民只会回答正常、头晕或冷。
有一天村里奥巴驴就去月儿那去询问了。
第一天她告诉月儿她感觉正常。
第二天她告诉月儿感觉有点冷。
第三天她告诉月儿感觉有点头晕。
那么问题来了,月儿如何根据阿驴的描述的情况,推断出这三天中阿驴的一个身体状态呢?
为此月儿上百度搜 google ,一番狂搜,发现维特比算法正好能解决这个问题。月儿乐了。
2.已知情况:
隐含的身体状态 = { 健康 , 发烧 }
可观察的感觉状态 = { 正常 , 冷 , 头晕 }
月儿预判的阿驴身体状态的概率分布 = { 健康:0.6 , 发烧: 0.4 }
月儿认为的阿驴身体健康状态的转换概率分布 = {
健康->健康: 0.7 ,
健康->发烧: 0.3 ,
发烧->健康:0.4 ,
发烧->发烧: 0.6
}
月儿认为的在相应健康状况条件下,阿驴的感觉的概率分布 = {
健康,正常:0.5 ,冷 :0.4 ,头晕: 0.1 ;
发烧,正常:0.1 ,冷 :0.3 ,头晕: 0.6
}
阿驴连续三天的身体感觉依次是: 正常、冷、头晕 。
3.题目:
已知如上,求:阿驴这三天的身体健康状态变化的过程是怎么样的?
4.过程:
根据 Viterbi 理论,后一天的状态会依赖前一天的状态和当前的可观察的状态。那么只要根据第一天的正常状态依次推算找出到达第三天头晕状态的最大的概率,就可以知道这三天的身体变化情况。
传不了图片,悲剧了。。。
1.初始情况:
2.求第一天的身体情况:
P(健康) = 0.6,P(发烧)=0.4。
计算在阿驴感觉正常的情况下最可能的身体状态。
那么就可以认为第一天最可能的身体状态是:健康。
P(今天健康) = P(健康|正常)*P(健康|初始情况) = 0.5 * 0.6 = 0.3
P(今天发烧) = P(发烧|正常)*P(发烧|初始情况) = 0.1 * 0.4 = 0.04
3.求第二天的身体状况:
计算在阿驴感觉冷的情况下最可能的身体状态。
那么第二天有四种情况,由于第一天的发烧或者健康转换到第二天的发烧或者健康。
那么可以认为,第二天最可能的状态是:健康。
P(前一天发烧,今天发烧) = P(发烧|前一天)*P(发烧->发烧)*P(冷|发烧) = 0.04 * 0.6 * 0.3 = 0.0072
P(前一天发烧,今天健康) = P(健康|前一天)*P(发烧->健康)*P(冷|健康) = 0.04 * 0.4 * 0.4 = 0.0064
P(前一天健康,今天健康) = P(发烧|前一天)*P(健康->健康)*P(冷|健康) = 0.3 * 0.7 * 0.4 = 0.084
P(前一天健康,今天发烧) = P(健康|前一天)*P(健康->发烧)*P(冷|发烧) = 0.3 * 0.3 *.03 = 0.027
4.求第三天的身体状态:
计算在阿驴感觉头晕的情况下最可能的身体状态。
那么可以认为:第三天最可能的状态是发烧。
P(前一天发烧,今天发烧) = P(发烧|前一天)*P(发烧->发烧)*P(头晕|发烧) = 0.027 * 0.6 * 0.6 = 0.00972
P(前一天发烧,今天健康) = P(健康|前一天)*P(发烧->健康)*P(头晕|健康) = 0.027 * 0.4 * 0.1 = 0.00108
P(前一天健康,今天健康) = P(发烧|前一天)*P(健康->健康)*P(头晕|健康) = 0.084 * 0.7 * 0.1 = 0.00588
P(前一天健康,今天发烧) = P(健康|前一天)*P(健康->发烧)*P(头晕|发烧) = 0.084 * 0.3 *0.6 = 0.01512
5.结论
根据如上计算。这样月儿断定,阿驴这三天身体变化的序列是:健康->健康->发烧。
HMM 的应用
以上举的例子是用HMM对掷骰子进行建模与分析。当然还有很多HMM经典的应用,能根据不同的应用需求,对问题进行建模。
但是使用HMM进行建模的问题,必须满足以下条件,
-
隐性状态的转移必须满足马尔可夫性。(状态转移的马尔可夫性:一个状态只与前一个状态有关)
2. 隐性状态必须能够大概被估计。
在满足条件的情况下,确定问题中的隐性状态是什么,隐性状态的表现可能又有哪些.
HMM适用于的问题在于,真正的状态(隐态)难以被估计,而状态与状态之间又存在联系。
5.1 语音识别
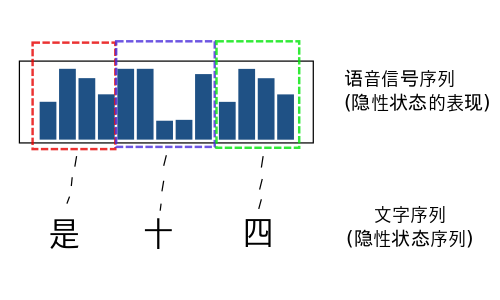
语音识别问题就是将一段语音信号转换为文字序列的过程. 在个问题里面
隐性状态就是: 语音信号对应的文字序列
而显性的状态就是: 语音信号.
HMM模型的学习(Learning): 语音识别的模型学习和上文中通过观察骰子序列建立起一个最有可能的模型不同. 语音识别的HMM模型学习有两个步骤:
1. 统计文字的发音概率,建立隐性表现概率矩阵B
2. 统计字词之间的转换概率(这个步骤并不需要考虑到语音,可以直接统计字词之间的转移概率即可)
语音模型的估计(Evaluation): 计算"是十四”,"四十四"等等的概率,比较得出最有可能出现的文字序列.
5.2 手写识别
这是一个和语音差不多,只不过手写识别的过程是将字的图像当成了显性序列.
5.3 中文分词
“总所周知,在汉语中,词与词之间不存在分隔符(英文中,词与词之间用空格分隔,这是天然的分词标记),词本身也缺乏明显的形态标记,因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序。例如,英文句子:you should go to kindergarten now 天然的空格已然将词分好,只需要去除其中的介词“to”即可;而“你现在应该去幼儿园了”这句表达同样意思的话没有明显的分隔符,中文分词的目的是,得到“你/现在/应该/去/幼儿园/了”。那么如何进行分词呢?主流的方法有三种:第1类是基于语言学知识的规则方法,如:各种形态的最大匹配、最少切分方法;第2类是基于大规模语料库的机器学习方法,这是目前应用比较广泛、效果较好的解决方案.用到的统计模型有N元语言模型、信道—噪声模型、最大期望、HMM等。第3类也是实际的分词系统中用到的,即规则与统计等多类方法的综合。”
5.4 HMM实现拼音输入法
拼音输入法,是一个估测拼音字母对应想要输入的文字(隐性状态)的过程(比如, ‘pingyin’ -> 拼音)

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)