
nagios+ganglia监控系统
nagios+ganglia监控系统简介:监控报警系统是基于已有的开源监控系统ganglia和nagios集成并做二次开发的监控系统。该系统不但实现的对原有系统功能及性能上的增强而且能够提供实时的可视化的监控数据。系统提供了多个监控指标,包括CPU、内存、网络、磁盘、及云平台的所有服务,同时可以灵活的设定报警规则,发送告警通知,以便用户能及时的了解资源的使用情况,性能问题以及云服务的健康状态。集成
nagios+ganglia监控系统
简介:
监控报警系统是基于已有的开源监控系统ganglia和nagios集成并做二次开发的监控系统。该系统不但实现的对原有系统功能及性能上的增强而且能够提供实时的可视化的监控数据。系统提供了多个监控指标,包括CPU、内存、网络、磁盘、及云平台的所有服务,同时可以灵活的设定报警规则,发送告警通知,以便用户能及时的了解资源的使用情况,性能问题以及云服务的健康状态。
集成系统架构图
:
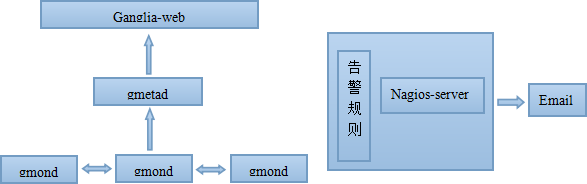
图1 监控系统集成图
工作原理
:
该云监控系统工作原理如图1所示,系统主要分为四个部分:gmond信息采集、gmetad信息汇总并处理、nagios告警通知、ganglia-web可视化显示。
云监控系统是一个分布式监控系统,在每个要监控的节点上,需要安装ganglia-gmond用于采集监控项的信息,且gmond各个节点间是能够感知的即每个gmond节点上都有所有节点的监控信息,他们之间的通信是通过组播实现的;gmetad安装在监控系统的控制节点上,它从任意一个gmond中获取采集到的数据,然后保存到rrd数据库中;nagios-server在这里主要实现告警通知,它使用check-ganglia从gmetad中拉取数据,再根据告警通知规则判断是否需要告警通知;ganglia-web是一个web应用需要Apache服务器的支持,他从gemtad中获取数据并从rrd数据库中拉取数据绘制图形显示。Ganglia-web、nagios-server、gmetad可以安装在同一个节点上也可安装在不同的节点上。
Ganglia剖析
:
Ganglia是个非常优秀分布式监控系统,它的层级结构使监控扩展到上千个节点变得很容易,它对资源的监控并可视化显示能很好的帮助我们了解资源使用情况然后进行性能调优。
系统架构
—-
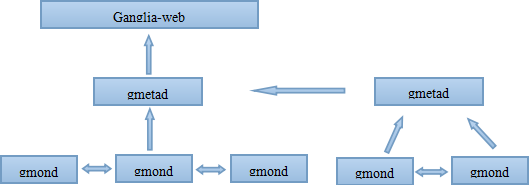
:
图2
Ganglia工作模式
:
Ganglia收集数据可以工作在单播或多播模式下,默认在多播模式。本系统采用多播模式。
单播:发送自己收集到的监控数据到特定的一台或几台服务器上,可以跨网段。
多播:发送自己收集到的监控数据到同一网段所有的服务器上,同时收集同一网段的所有服务器发送过来的监控数据。因为是以广播的形式发送,因此需要在同一网段内,但同一网段内,又可以定义不同的发送信道。
Gmond之间通过udp通信,传递的文件格式为xdl。收集的数据供gmetad读取,默认监听的端口8649,监听到gmetad的请求后发送xml格式的文件。在监控系统中gmetad会周期性的到各个datasource收集各个cluster的数据,并更新到rrd数据库中,datasource是指被监控的一个集群。
Ganglia模块扩展
:
所谓模块扩展就是增加ganglia系统中的metric,metric是被监控项在ganglia系统中的定义。向ganglia加入自定义metric有两种方法,一种是通过命令行的方式运行gmetric,另一种是通过ganglia提供的面向c和python的扩展模块,加入自定义的模块支持,本系统采用第二种方法。
安装必要的扩展模块:
在扩展ganglia插件之前,首先要确定已经安装了ganglia-gmond-python,如果没有安装,则要提前在每个gmond节点上安装该模块。安装好之后会在/usr/lib64/ganglia/目录下出现文件modpython.so和目录python_modules。
配置gmond.conf文件,添加扩展模块:
vim /etc/ganglia/gmond.conf
该文件中包含:include (‘/etc/ganglia/conf.d/*.conf’),若没有要自己添加。
**
**:
vim /etc/ganglia/conf.d/modpython.conf
modules{
module{
name=”python_module”#python主模块
path=”modpython.so”#动态库路径
params=“/usr/lib64/ganglia/python_modules”#指定编写的python插件脚本位置
}
}
include(‘/etc/ganglia/conf.d/*.pyconf’)
编写扩展模块
:
1.自定义python模块的配置文件:
vim /etc/ganglia/conf.d/random_module.pyconf
modules{
module {
name=”random_module”
language=”python”
param RandomMax{
value=10
}
param RandomMin{
value=0
}
}
}
collection_group{
collect_group=10
time_threshold=50#最大发送间隔
metric {
name=”random1”#metric在模块中的名字
title=”test random1”#图形界面上显示的标题
value_threshold=50
}
metric{
name=”random2”
title=”test random2”
value_threshold=50
}
}
2.自定义扩展模块的metric:
cd /usr/lib64/ganglia/python_modules/
vi random_module.py
import random
random_max = 100
random_min = 0
v = 0
def random1_handler(name):
global v,random_max,random_min
v = random.randint(random_min,random_max)
return v
def random2_handler(name):
global v,random_max,random_min
return random_min+random_max-v
def metric_init(params):
global random_max,random_min
if params:
if params.has_key(“RandomMin”):
random_min = int(params[“RandomMin”])
if params.has_key(“RandomMax”):
random_max = int(params[“RandomMax”])
tmp = {‘name’:’random1’,’call_back’:random1_handler,
‘value_type’:’uint’,’units’:’usage’,
‘slope’:’both’,’format’:’%u’,
‘description’:’test random plugin’,
‘groups’:’random’}
descriptors = [tmp]
tmp1 = {‘name’:’random2’,’call_back’:random2_handler,
‘value_type’:’uint’,’units’:’usage’,
‘slope’:’both’,’format’:’%u’,
‘description’:’test subs plugin’,
‘groups’:’random’}
descriptors.append(tmp1)
return descriptors
def metric_cleanup():
pass
if name==’main‘:
descriptors = metric_init(None)
for d in descriptors:
print “value for %s is %d”%(d[‘name’],d‘call_back’)
每个自定义扩展模块都必须包含三个函数:metirc_init(params)、metric_handler()、metric_cleanup(),metric_init()在模块初始化的时候会被调用,它必须要返回一个metric的字典或者字典的列表;metric_handler()可以有多个,是用来采集数据;metric_cleanup()在模块结束的时候被调用。
到这里一个扩展的插件就完整结束了,重启gmond服务就可以测试一下效果了。
Nagios剖析
:
Nagios是以一款开源的电脑系统和网络监控工具,在该云监控系统中使用的nagios的告警通知功能,当服务发生异常是,告警系统会第一时间通知服务运维人员,以便解决异常问题。
Nagios安装好之后,要使用nagios的监控功能就必须修改nagios的配置文件。
Nagios配置文件:
Nagios的配置文件在/etc/nagios/目录下,在这里我们需要关注的是nagios.cfg、resource.cfg和objects目录下的commands.cfg、contacts.cfg、hosts.cfg、service.cfg。nagios.cfg是nagios服务的主配置文件;resource.cfg是变量定义文件,又称为资源文件,该文件中定义的变量被其他文件引用;commands.cfg是命令定义配置文件,其中定义的文件可以被其他文件引用;contacts.cfg定义联系人和联系人组的配置文件;hosts.cfg是定义host和hostgroup的配置文件,需要自己定义;services.cfg是定义服务和服务组的配置文件,需要自己定义。
配置文件重点内容之间的关系:
在nagios的配置过程中涉及到的几个定义有:主机、主机组、服务、服务组、联系人、联系人组、监控时间、监控命令等,从这些定义可以看出,nagios各个配置文件之间是相互关联的,彼此引用的,所以成功部署好一个nagios系统,必须要清楚每个配置文件之间依赖与被依赖的关系、最重要有以下四点:
1.定义监控那些主机、主机组、服务和服务组;
2.定义这些监控要用什么命令实现;
3.定义监控时间段;
4.定义主机或者服务出现问题时要通知的联系人和联系人组
其中3、4是用默认定义;这里对1、2进行定义:
定义主机、主机组、服务、服务组和命令:
主机和主机组
define host {
use linux-server
host_name Nagios-Server
alias Nagios-Server
address 192.168.2.100
}
define hostgroup {
hostgroup linux-servers
alias Linux Servers
members Nagios_Server
}
服务和服务组
define servicegroup {
servicegroup_name ganglia-metrics
alias Ganglia Metrics
}
define service {
name compute-service
use generic-service
hostgroup_name compute-nodes
service_groups compute-metrics
notifications_enabled 0
register 0
}
define service {
use compute-service
service_description nova_compute
check_command check_ganglia!nova_compute!0!0
}
命令
define command {
command_name check_ganglia
command_line
USER1
/check_ganglia.py -h
HOSTNAME
-m
ARG1
-w
ARG2
-c
ARG3
}
注:告警通知发送的邮箱在contacts.cfg 修改email配置项即可。
配置正确性检查:
Nagios提供了对配置是否正确的检查:
$nagios -v /etc/nagios/nagios.cfg
执行上面命令后会提示配置是否正确,如果ERROR为0,则配置正常,若有错误则需要重新排查配置文件。
Ganglia与Nagios集成
:
如图1 ganglia的集成工作是通过check_ganglia python模块来完成的,nagios通过check_ganglia从ganglia-gmetad中拉取数据做为自己告警通知的依据,check_ganglia模块可以通过网络下载,放在nagios plugins目录下。但是nagios只支持大于某个值才发告警通知,如果需要小于某个值也发告警通知,则需要对check_ganglia的原密码的做修改。
Check_ganglia修改部分代码:
if critical == None or warning == None or metric == None or host == None:
usage()
sys.exit(3)
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
print ganglia_host, ganglia_port
s.connect((ganglia_host,ganglia_port))
print “hello world”,host,metric
parser = GParser(host, metric)
print “hello bye”
#for line in s.makefile(“r”):
# print line
value = parser.parse(s.makefile(“r”))
print “———————————————————-”
s.close()
except Exception, err:
print “CHECKGANGLIA UNKNOWN: Error while getting value \”%s\”” % (err)
sys.exit(3)
if critical > warning:
if value >= critical:
print “CHECKGANGLIA CRITICAL: %s is %.2f” % (metric, value)
sys.exit(2)
elif value >= warning:
print “CHECKGANGLIA WARNING: %s is %.2f” % (metric, value)
sys.exit(1)
else:
print “CHECKGANGLIA OK: %s is %.2f” % (metric, value)
sys.exit(0)
else:
if critical > value:
print “CHECKGANGLIA CRITICAL: %s is %.2f” % (metric, value)
sys.exit(2)
elif warning > value:
print “CHECKGANGLIA WARNING: %s is %.2f” % (metric, value)
sys.exit(1)
else:
print “CHECKGANGLIA OK: %s is %.2f” % (metric, value)
sys.exit(0)
异常错误
:
- 不能从gmetad或者gmond中获取数据
iptables 对gmetad和gmond服务的端口有限制,需要手动打开
- Gmond之间不能相互感知
gmond之间的通信使用了组播技术,需要网络通信设备支持组播技术,且要添加网关路由:route add -net 0.0.0.0 netmask 0.0.0.0 gw 网关

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)