
Linux多线程计算Pi函数(互斥没起作用???)
#include <stdio.h>#include <stdlib.h>#include <pthread.h>#include <sys/time.h>pthread_mutex_t mutexsum;#define thread_count4double sum;void* start_thread(void *rank);void* start_thread(void *ra
先上代码,求pi的公式就不贴了
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/time.h>
pthread_mutex_t mutexsum;
#define thread_count 4
double sum;
void* start_thread(void *rank);
void* start_thread(void *rank)
{
long my_rank = rank;
double factor;
long long i ;
long long my_n = 80000000/thread_count ;
long long my_first_i = my_n*my_rank;
long long my_last_i = my_first_i + my_n;
double my_sum = 0.0;
if(my_first_i % 2 == 0)
factor = 1.0;
else
factor = -1.0;
for(i = my_first_i;i<my_last_i;i++,factor = -factor)
{
my_sum += factor / (2*i+1);
}
//pthread_mutex_lock (&mutexsum);//为什么不互斥,结果也没有出问题呢???
sum += my_sum;
//pthread_mutex_unlock (&mutexsum);
return NULL;
}
int main(void)
{
long thread;
pthread_t thread_handles[thread_count];
//thread_handles = malloc(thread_count*sizeof(pthread_t));
struct timeval tpstart,tpend;
float timeuse;
gettimeofday(&tpstart,NULL);
pthread_mutex_init(&mutexsum, NULL);
for(thread=0;thread<thread_count;thread++)
{
/* Each thread works on a different set of data.
* The offset is specified by 'i'. The size of
* the data for each thread is indicated by VECLEN.
*/
pthread_create(&thread_handles[thread], NULL, start_thread, (void *)thread);
}
printf("main function\n");
/* Wait on the other threads */
for(thread=0;thread<thread_count;thread++)
{
pthread_join(thread_handles[thread], NULL);
}
gettimeofday(&tpend,NULL);
timeuse=1000000*(tpend.tv_sec-tpstart.tv_sec)+tpend.tv_usec-tpstart.tv_usec;
timeuse/=1000000;
printf("sum is:%lf,and run time is: %fs \n",4*sum,timeuse);
pthread_mutex_destroy(&mutexsum);
pthread_exit(NULL);
return 0;
}
首先采用多线程是可以提高计算速度的,具体的还要看是多核还是单核处理器,下面是仔细分析
首先是单核处理器(树莓派B+) 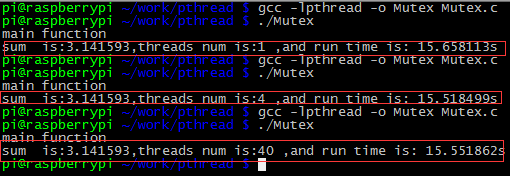
我们可以很明显的看出来,在1个线程,4个线程还有40个线程的,处理时间都是15s,在单核处理器上进行多线程优化速度是没有效果的,除非在你的程序中有无需要的等待,比如有等待输入,sleep,或者其他的浪费CPU时间的空隙,那么用多线程可以提高性能的。(PS:在看了Linux系统编程一书,在单核处理器上,线程是为那些不会写状态机的人提供的,这句话基本是正确的,因为我们可以采用状态机或者非阻塞IO实现来避免无畏的CPU空隙时间。)
然后是四核处理器(树莓派2) 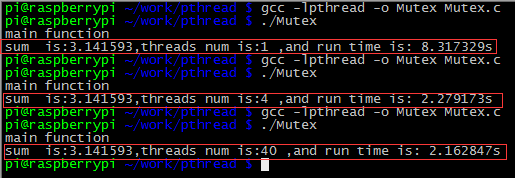
再看多核处理器上运行同样的程序,可以看出,在线程数不超过CPU核数的时候,T单线程时间/T多线程时间=线程数,也就是线程的数目就是速度提高的倍数。但是当线程超过4个(也就是CPU的核数)的时候,速度就没有提升了。
最后我在纳闷,以上程序都是在sum(全局变量,也是pi的结果)没有进行同步互斥下计算的结果,奇怪的是结果和加了互斥量的时候一样,没有出现书中提到的临界区数据混乱出错,因为在多线程下,同时去访问改变同一个全局变量,是肯定会出问题的。but why?难道树莓派可以自动优化这种竞争??继续研究
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)