
HBase Region分裂
HBase region的分裂过程如图所示,其中红色代表RegionServer和或Master的行为,绿色的代表Clients的行为。1、RegionServer决定本地的region分裂,并准备分裂工作。第一步是,在zookeeper的/hbase/region-in-reansition/region-name下穿件一个znode,并设为SPLITTING状态。2、Maste
HBase region的分裂过程如图所示,其中红色代表RegionServer和或Master的行为,绿色的代表Clients的行为。
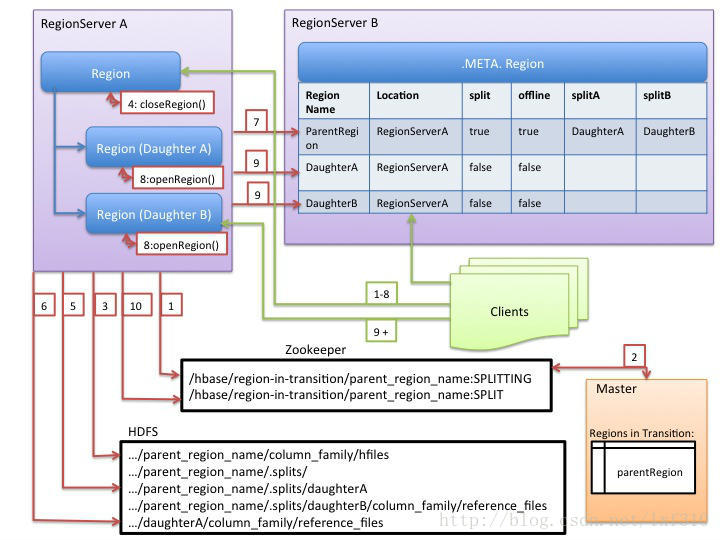
1、RegionServer决定本地的region分裂,并准备分裂工作。第一步是,在zookeeper的/hbase/region-in-reansition/region-name下创建一个znode,并设为SPLITTING状态。
2、Master通过父region-in-transition znode的watcher监测到刚刚创建的znode。
3、RegionServer在HDFS中父region的目录下创建名为“.split”的子目录。
4、RegionServer关闭父region,并强制刷新缓存内的数据,之后在本地数据结构中将标识为下线状态。此时来自Client的对父region的请求会抛出NotServingRegionException ,Client将重新尝试向其他的region发送请求。
5、RegionServer在.split目录下为子regionA和B创建目录和相关的数据结构。然后RegionServer分割store文件,这种分割是指,为父region的每个store文件创建两个Reference文件。这些Reference文件将指向父region中的文件。
6、RegionServer在HDFS中创建实际的region目录,并移动每个子region的Reference文件。
7、RegionServer向.META.表发送Put请求,并在.META.中将父region改为下线状态,添加子region的信息。此时表中并单独存储没有子region信息的条目。Client扫描.META.时回看到父region为分裂状态,但直到子region信息出现在表中,Client才直到他们的存在。如果Put请求成功,那么父region将被有效地分割。如果在这条RPC成功之前RegionServer死掉了,那么Master和打开region的下一个RegionServer会清理关于该region分裂的脏状态。在.META.更新之后,region的分裂将被Master回滚到之前的状态。
8、RegionServer打开子region,并行地接受写请求。
9、RegionServer将子region A和B的相关信息写入.META.。此后,Client便可以扫描到新的region,并且可以向其发送请求。Client会在本地缓存.META.的条目,但当她们向RegionServer或.META.发送请求时,这些缓存便无效了,他们竟重新学习.META.中新region的信息。
10、RegionServer将zookeeper中的znode /hbase/region-in-transition/region-name更改为SPLIT状态,以便Master可以监测到。如果子Region被选中了,Balancer可以自由地将子region分派到其他RegionServer上。
11、分裂之后,元数据和HDFS中依然包含着指向父region的Reference文件。这些Reference文件将在子region发生紧缩操作重写数据文件时被删除掉。Master的垃圾回收工会周期性地检测是否还有指向父region的Reference,如果没有,将删除父region。
原文:http://zh.hortonworks.com/blog/apache-hbase-region-splitting-and-merging/

权威|前沿|技术|干货|国内首个API全生命周期开发者社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)