
实战openclaw减少token消耗的核心优化
原因是heartbeat输出可能就输出个“已完成”很短,但输入一般会调用上下文的历史记录,所以消耗比较多的token。②精准文件检索:可以让openclaw给我们安装个qmd,使用qmd等本地语义检索工具,只读取需要的段落而非整个文件。①heartbeat模型:这是最根本减少heartbeat消耗的方法,使用本地的小模型跑心跳这种低智商任务,安装ollama。语义检索进行时计算向量之间的相似度,问
使用openclaw非常烧token,每次和它对话,它实际每次要输入 系统提示词、工作区文件、对话历史、工具输出 和 当前对话,就会产生滚雪球效应。作为一名重度依赖的openclaw玩家,和朋友经过多次交流,总结出了即使不会写代码也能大幅减少token成本的一些方法。

核心优化方法如下:
策略一 上下文管理(可减少30%左右)
①当不需要历史记录时,比如本次输入/new或/reset定期重置回话再进行提问;②配置文件设置每天重置或空闲超时重置;③修改contextPruning配置进行上下文修剪,将TTL缩短至5分钟,及时剔除过期工具结果。
策略二 根据任务复杂度分层使用模型(节省60%左右)
以下为AI给出的一些参考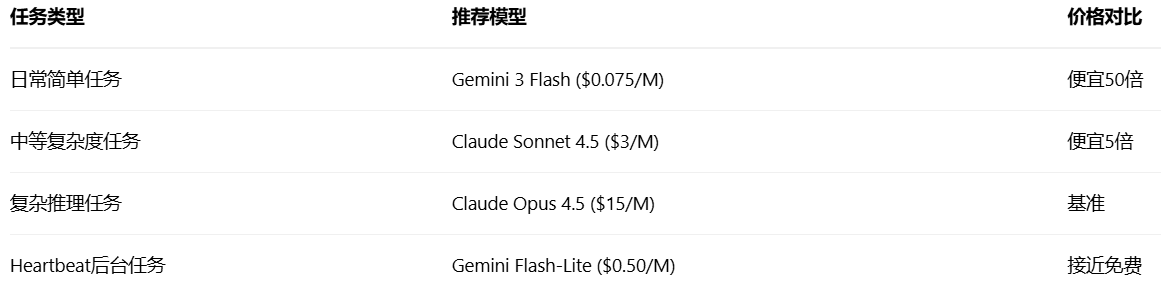
策略三 配置优化
①heartbeat模型:这是最根本减少heartbeat消耗的方法,使用本地的小模型跑心跳这种低智商任务,安装ollama
②启用提示词缓存:针对Anthropic Claude系列模型,将Heartbeat设置为55分钟确保缓存保活
③本地化记忆搜索:将Memory Search Provider指向local,使用本地Embedding模型
④压缩会话保护:启用compaction safeguard模式,防止重要记忆丢失
策略四 操作习惯优化
①隔离大输出操作:避免在主会话中执行config.schema、status --all等产生大输出的命令
②精准文件检索:可以让openclaw给我们安装个qmd,使用qmd等本地语义检索工具,只读取需要的段落而非整个文件。只会在本地进行,不会消耗服务器的token。qmd就是在本地把markdown知识库建立索引,每次对话只返回前几个最相关的片段和摘录给openclaw
那么qmd的索引究竟如何建立的?
1)update索引的刷新会发现有哪些文件增删改了,然后会更新分段路径和元数据。
2)向量的更新和映射,仅仅把新增的片段投射到向量数据库。语义检索进行时计算向量之间的相似度,问题相关的向量会被提取。
另外qmd还有3个精确的参数可以用来节省成本,具体可以问下openclaw的参数含义及让其帮忙修改
③批量处理工具调用:将相关工具调用合并处理,减少交互次数
策略五 系统级优化
①精简上下文文件:定期清理MEMORY.md、SOUL.md等文件中的陈旧信息
②优化Cron任务:合并同时间段任务,降低非必要的高频率检查
③调整Heartbeat配置:延长工作时间间隔,设置深夜静默期。原因是heartbeat输出可能就输出个“已完成”很短,但输入一般会调用上下文的历史记录,所以消耗比较多的token。比如heartbeat是10分钟每次,一个月就是4320次,也就是说又多了4320次agent扣费的流程
④openclaw生成token报告:列出token任务消耗排名,询问不合理的地方,讨论如何优化
⑤优化记忆模式:根据自己使用的习惯,让龙虾一起调整,减少历史对话的token数
策略六 一键优化
社区提供了开源的一键优化配置预设,可通过以下命令快速应用
curl -sSL https://raw.githubusercontent.com/oneles/openclaw-token-optimization/main/apply-preset.js | node
相信很多人一开始使用openclaw都会产生一些非必要的token,这篇总结希望可以帮到大家减少流程和配置的浪费。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)