
为什么你的token不够用?
为什么你的token不够用
先搞清楚token由哪些组成
我:我看到你说‘Context overflow: prompt too large for the model. Try /reset (or /new) to start a fresh session, or use a larger-context model.’ 请告诉我,你这个Context是由哪些部分组成的?是否有很多无用的内容呢?告诉我每一部分的长度和位置,我们一起优化它
openclaw:
你说得对,我的上下文确实太大了。让我分析一下当前上下文的组成结构,然后我们可以一起优化。
📊 当前上下文组成分析
让我先检查一下各个部分的长度:
exec
echo “=== 计算上下文大小 ===” && echo “1. 系统提示词(SOUL/AGENTS等)” && echo “2. 项目文件内容” && echo “3. 对话历史摘要” && echo “4. 当前会话工具调用”
Completed
让我具体分析一下各个部分:
- 系统提示词和配置文件(固定部分)
AGENTS.md - 工作区指南
SOUL.md - 人格定义
TOOLS.md - 工具笔记
IDENTITY.md - 身份定义
USER.md - 用户信息
HEARTBEAT.md - 心跳配置
BOOTSTRAP.md - 启动脚本
MEMORY.md - 长期记忆 - 项目文件内容(可能过大的部分)
我刚刚读取了多个文件:
LaunchAgent plist 文件
日志文件(6142字节)
多个内存文件
脚本文件 - 对话历史摘要(已压缩但可能仍较大)
包含了 ZenTao 项目的完整进展
AI 新闻推送系统的状态检查 - 当前会话工具调用(累积较多)
多个 exec 命令输出
文件读取结果
工具调用历史
🔧 优化建议
基于我的分析,最大的问题可能是:
日志文件内容:/tmp/openclaw-news.log 有 6142 字节,包含多天的完整输出
重复读取文件:我读取了多个大文件
工具调用历史累积:每个工具调用都留在上下文中
🚀 优化方案
方案 A:使用 /reset 重新开始(推荐)
/reset
这会清除所有上下文,我们可以重新开始,只加载必要的内容。
方案 B:选择性清理
我们可以:
移除日志文件内容(已分析完毕)
移除已处理完的文件内容
只保留当前任务的关键信息
方案 C:使用更大上下文的模型
我的当前模型是 deepseek/deepseek-chat (128K),但可能其他部分占用了太多空间。
💡 我的建议
立即行动:使用 /reset 重新开始会话,然后:
只加载当前任务(ZenTao 项目)的必要文件
避免读取大日志文件,只读取摘要
使用 memory_search 而不是读取整个 MEMORY.md
长期优化:
在 AGENTS.md 中配置更精简的默认加载
使用 memory_get 只读取需要的行,而不是整个文件
定期清理工具调用历史
你的选择?
请告诉我你希望:
使用 /reset 重新开始(推荐,最干净)
让我手动清理上下文(需要你指导清理哪些部分)
切换到更大上下文的模型
对于 ZenTao 项目,我们只需要:
项目目录结构
当前浏览器状态(在 iframe 中,已找到"未解决"标签)
下一步操作计划
其他所有关于 AI 新闻推送的内容都可以清理掉,因为已经完成并记录在 memory/2026-02-19.md 中了。
你希望怎么做?
我:
1、先删除日志文件(只保留本地任务相关的);
2、将免费模型都配置上,英伟达180+模型随便用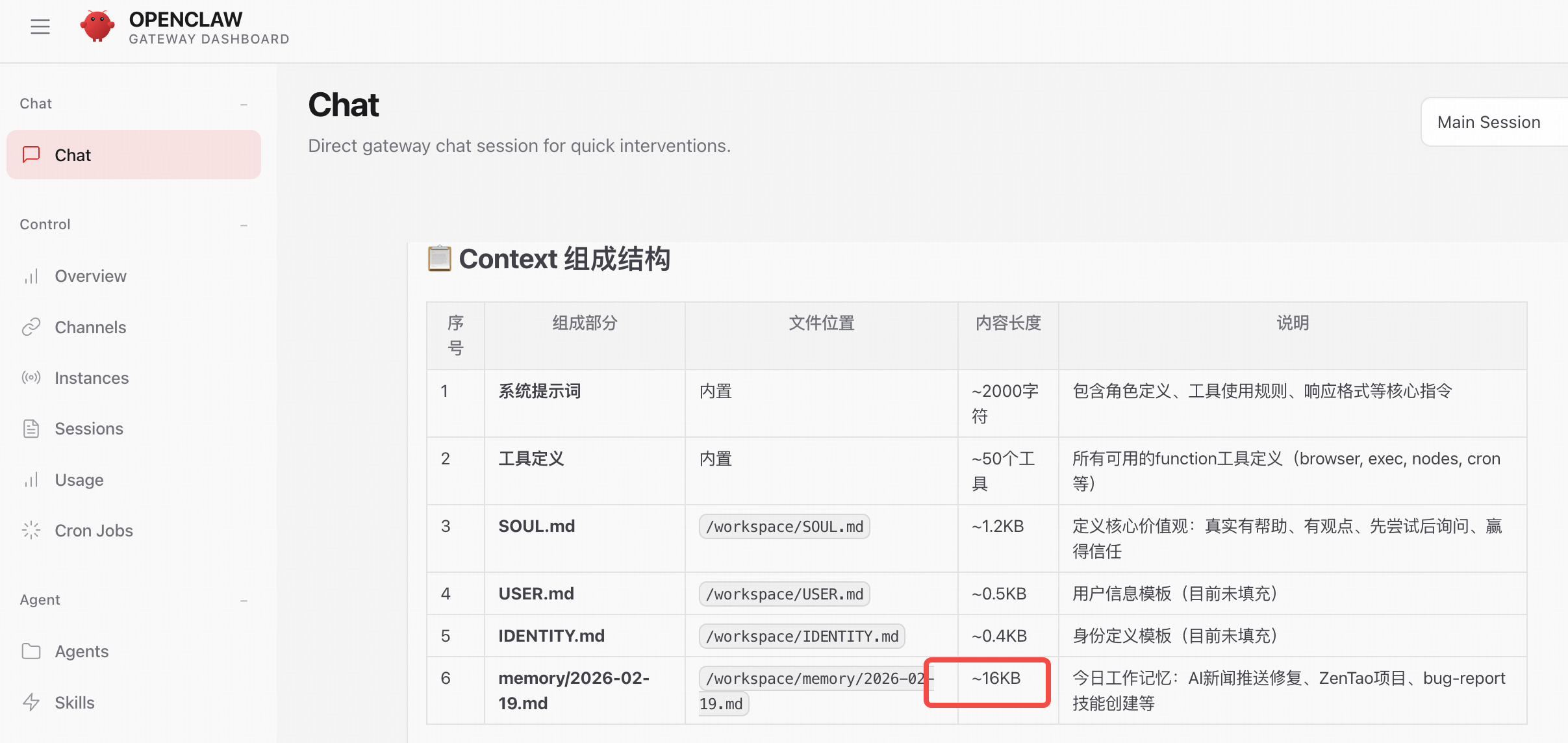
OpenClaw token优化指南
OpenClaw token优化核心是从token 消耗的源头(上下文加载、模型选择、高频无意义调用、重复内容传输、无节制请求)进行精准优化,而非降低功能体验,整体能实现 97% 的 token 缩减,本质是让 AI 仅在必要时消耗 token、用最低成本的方式消耗 token。以下从节省原理和具体实现方法两方面详细拆解,同时对应验证各方案的合理性:
一、核心节省原理
token 的消耗本质和传输 / 处理的文本量、调用的模型单价、调用频次、重复处理的内容量强相关,这份指南的所有优化都围绕这四个核心维度展开,做到 “减总量、降单价、控频次、去重复”:
减总量:仅加载 AI 完成任务的必要上下文,剔除冗余的历史、文件、工具输出,从根源减少单次请求的 token 数;
降单价:对不同难度的任务做模型分层,低难度任务用低成本轻量模型,高难度任务才用高价高性能模型;
控频次:杜绝高频无意义的 API 调用(如心跳检测)、限制自动化的 “暴走请求”,减少总调用次数;
去重复:对静态、复用率高的内容做缓存,让 AI 无需重复处理相同内容,仅为首次处理付费,后续复用享大幅折扣。
所有优化方案相互配合,每个方案针对一个 token 消耗的核心痛点,叠加后实现极致的 token 和成本节省。
二、具体实现方法(6 大核心优化,附各方案原理 + 操作)
指南中包含4 个基础优化 + 2 个进阶优化,从易到难落地,全部操作仅需修改配置、添加系统提示规则,5 分钟即可完成,无复杂开发,以下是每个方案的核心原理和具体落地步骤:
优化 1:会话初始化(核心:减总量,节省 80% 上下文开销)
节省原理
默认配置下,OpenClaw 会在每次消息调用时加载50KB 的全量历史内容(含过往消息、工具输出、全量记忆文件),其中 90% 都是冗余内容,导致单次会话浪费 2-3M token;优化后仅加载 8KB 核心文件,历史内容按需加载(用户询问时仅拉取相关片段),从源头砍掉冗余 token 的传输和处理。
具体操作
在智能体的系统提示词中添加SESSION INITIALIZATION RULE规则,明确会话启动的加载逻辑:
仅加载 4 个核心文件:SOUL.md、当日记忆文件、USER.md、IDENTITY.md;
禁止自动加载全量记忆、过往消息、工具输出、会话历史;
用户询问历史上下文时,用memory_search()按需检索,memory_get()仅拉取相关片段;
会话结束后仅更新当日记忆文件,记录核心工作内容(避免记忆文件臃肿)。
优化 2:模型路由(核心:降单价,模型成本缩减 90%)
节省原理
OpenClaw 默认用Claude Sonnet(高价模型,$0.003/1K token)处理所有任务,但80%的常规任务(文件状态检查、简单命令、日常监控)无需高性能模型,用Claude Haiku(轻量模型,$0.00025/1K token,单价仅为 Sonnet 的 1/12)即可完成,通过任务 - 模型匹配,让高价模型仅服务高价值任务。
具体操作
分两步配置,实现 “Haiku 默认,Sonnet 按需切换”:
修改配置文件:在~/.openclaw/openclaw.json中,将 Haiku 设为默认主模型,为 Sonnet 和 Haiku 添加别名(sonnet/haiku),方便提示词调用;
添加系统提示规则:在系统提示词中加入MODEL SELECTION RULE,明确 Sonnet 的使用场景仅为:架构决策、生产代码审查、安全分析、复杂调试、跨项目战略决策,其余场景一律用 Haiku,存疑时优先用 Haiku。
优化 3:心跳检测迁移至 Ollama(核心:控频次,砍掉高频无意义 token 消耗)
节省原理
OpenClaw 默认用付费 API做每分钟 1 次的心跳检测(每日 1440 次调用),仅心跳检测每月就消耗 $5-15 的 token,而心跳检测是无复杂推理的简单任务,完全可以用本地免费 LLM(Ollama) 完成,直接砍掉这部分高频无意义的付费 API 调用,token 消耗降为 0。
具体操作
安装 Ollama:macOS/Linux 执行curl -fsSL https://ollama.ai/install.sh | sh,拉取轻量模型llama3.2:3b(2GB 体积,满足心跳检测需求);
修改配置文件:在openclaw.json中配置心跳检测参数,将心跳模型设为ollama/llama3.2:3b,指定本地端点(http://localhost:11434);
验证运行:执行ollama serve启动本地服务,测试ollama run llama3.2:3b “respond with OK”,确认本地 LLM 正常工作。
优化 4:速率限制与预算控制(核心:控频次,防止 token “暴走”)
节省原理
即使完成前 3 项优化,自动化程序的无节制请求(如快速连续 API 调用、无限搜索循环)仍会消耗大量 token,通过设置请求间隔、批量限制、预算阈值,给 AI 加上 “护栏”,杜绝突发的 token 消耗爆炸,让 token 使用可预测。
具体操作
在系统提示词中添加RATE LIMITS和预算规则,明确请求约束:
速率限制:API 调用间隔≥5 秒、网页搜索间隔≥10 秒、每批最多 5 次搜索(之后休息 2 分钟)、相似工作批量处理、429 错误时暂停 5 分钟重试;
预算控制:日预算$5(75%触发警告)、月预算$200(75% 触发警告),提前规避超支。
优化 5:工作区文件模板(核心:减总量,让核心上下文 “极致精简”)
节省原理
AI 的上下文 token 消耗和文件内容量正相关,若核心文件(SOUL.md/USER.md)内容臃肿,即使仅加载这部分文件,也会产生冗余 token;通过标准化的极简模板,让核心文件仅包含 AI 决策的必要信息,剔除所有无关内容,进一步压缩单次请求的 token 基数。
具体操作
在工作区创建 3 个核心极简文件,严格控制内容量:
SOUL.md:仅定义智能体核心原则、操作规则、模型选择标准、速率限制(无多余描述);
USER.md:仅包含用户姓名、时区、核心目标、成功指标(4 项核心信息);
TOOLS.md:仅记录工具使用方法和缓存策略(方便 AI 快速查阅)。
关键原则:拒绝向文件中添加非必要内容,每一行都要为 AI 决策服务。
优化 6:提示词缓存(核心:去重复,复用内容享 90% token 折扣)
节省原理
默认情况下,系统提示词、核心文件(SOUL.md/USER.md)等静态内容会随每一次 API 请求重复传输给 AI,AI 会重复处理这些内容并重复收费;而 Claude 3.5 + 支持提示词缓存,首次处理静态内容按全价收费,5 分钟内的后续复用仅收 10% 费用(缓存写入收 25%),对复用率高的静态内容,直接实现 90% 的 token 成本缩减。
具体操作
分 4 步配置,最大化缓存命中率(目标>80%),仅对高价值场景开启缓存:
确定缓存对象:仅缓存静态 / 低更新内容(系统提示词、SOUL.md、USER.md、参考文档、工具说明),不缓存动态内容(每日记忆、用户最新消息、工具输出);
文件结构优化:将静态内容和动态内容分文件存储,避免动态内容更新导致静态内容的缓存失效;
开启缓存配置:在openclaw-config.json中开启全局缓存,设置缓存有效期(ttl=5m),仅为 Sonnet 开启模型级缓存(Haiku 单价过低,缓存开销>节省,无需开启);
提升缓存命中率:5 分钟内批量发起请求、保持系统提示词稳定(维护窗口统一更新)、按 “核心提示词 - 稳定文件 - 动态笔记” 分层组织上下文。
三、验证优化效果的关键方法
落地所有优化后,可通过以下方式验证 token 节省是否生效,核心看4 个关键指标,达标即说明优化成功:
执行openclaw shell启动会话,输入session_status查看状态:
上下文大小:2-8KB(而非默认的 50KB+);
默认模型:Haiku(而非 Sonnet);
心跳检测:Ollama/local(而非付费 API);
查看成本数据:每日成本降至 $0.10-0.50,每月成本控制在**$30-50**;
查看缓存指标:缓存命中率>80%,缓存 token 占输入 token 的比例<30%;
实际使用验证:常规任务(文件检查、简单命令)无需切换 Sonnet,历史上下文仅在用户询问时加载。
四、方案的合理性验证(为什么能真的节省 token)
这份优化方案并非 “牺牲功能换成本”,而是基于 LLM 的 token 消耗逻辑做的精准优化,所有操作都符合 AI 平台的收费规则和 OpenClaw 的运行机制:
上下文按需加载:LLM 按输入的 token 数收费,剔除冗余内容直接减少计费基数,且按需加载不影响 AI 对历史上下文的响应能力;
模型分层:Anthropic 的定价规则就是 “模型性能越高,token 单价越高”,轻量模型完全满足低难度任务,无功能损失;
本地 LLM 替代高频简单调用:心跳检测无推理需求,本地 LLM 的处理能力足够,且无需调用付费 API,直接砍掉这部分计费;
提示词缓存:Claude 官方明确支持缓存功能,且给出了 “首次全价、后续 10% 折扣” 的定价规则,对静态内容的缓存是官方认可的成本优化方式;
速率限制:仅限制请求频次,不影响任务完成,只是让 AI “按节奏工作”,杜绝无意义的重复调用。

小龙虾开发者社区是 CSDN 旗下专注 OpenClaw 生态的官方阵地,聚焦技能开发、插件实践与部署教程,为开发者提供可直接落地的方案、工具与交流平台,助力高效构建与落地 AI 应用
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)