Redis 4.0核心特性与Linux环境部署实战
Redis 4.0于2017年发布,标志着其从纯内存键值存储向多功能数据平台的转型。该版本延续了单线程事件驱动模型(基于Reactor模式),通过非阻塞I/O和多路复用机制(epoll/kqueue)实现高并发处理能力,在保障原子性的同时避免锁竞争开销。其核心设计哲学在于“简单即高效”,所有命令在主线程串行执行,杜绝上下文切换损耗。RedisJSON模块是Redis模块系统的标杆案例,它使Redi

简介:Redis 4.0是一个功能增强的重要版本,显著提升了性能、扩展性和稳定性。该版本引入了Stream数据类型、模块系统、命令阻塞优化和客户端缓存等关键特性,广泛适用于缓存、消息中间件和实时数据处理场景。本文详细介绍Redis 4.0在Linux系统中的下载、编译、配置与启动流程,并涵盖安全设置、持久化策略及监控维护方法,帮助开发者快速掌握Redis 4.0的安装部署与核心功能应用。 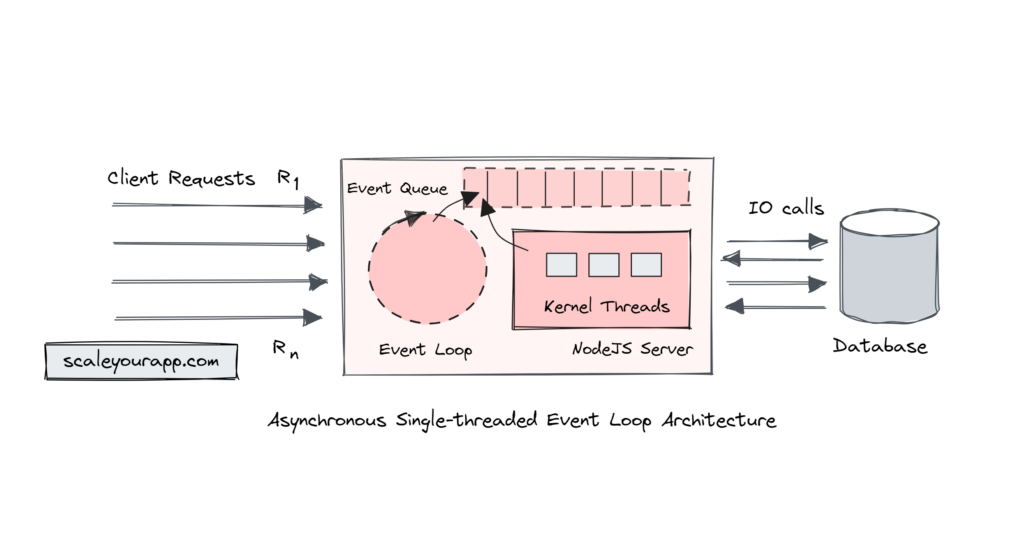
1. Redis 4.0简介与核心特性概述
Redis 4.0的版本演进与架构哲学
Redis 4.0于2017年发布,标志着其从纯内存键值存储向多功能数据平台的转型。该版本延续了单线程事件驱动模型(基于Reactor模式),通过非阻塞I/O和多路复用机制(epoll/kqueue)实现高并发处理能力,在保障原子性的同时避免锁竞争开销。其核心设计哲学在于“简单即高效”,所有命令在主线程串行执行,杜绝上下文切换损耗。
持久化机制的精细化权衡
Redis 4.0提供RDB与AOF两种持久化策略:RDB通过定时快照保证高性能恢复速度,适用于灾备场景;AOF则以日志追加形式实现近实时数据安全,支持 appendfsync everysec 策略,在性能与可靠性间取得平衡。两者可结合使用,提升系统鲁棒性。
扩展能力初现:模块化支持雏形
本版本首次引入Module System实验性支持,允许开发者通过C语言扩展新数据类型(如RedisJSON雏形)。借助动态加载机制( MODULE LOAD ),Redis开始向可插拔架构演进,为后续Stream、AI等模块奠定基础。
2. Stream数据类型原理与实践应用
Redis 4.0 引入的 Stream 数据类型,标志着其从传统键值缓存向具备消息队列能力的复合型存储系统迈出关键一步。不同于早期的 Pub/Sub 模式仅提供“发后即忘”的广播机制,Stream 提供了持久化、可回溯、支持消费者组(Consumer Group)的消息流处理模型,使其在日志管道、事件溯源、微服务间异步通信等场景中展现出强大的适用性。本章将深入剖析 Stream 的设计哲学、底层实现机制,并通过真实案例展示其在现代分布式架构中的落地方式。
2.1 Stream数据结构的设计思想与底层实现
Stream 的核心定位是“持久化的、有序的、支持多消费者的消息日志”。它借鉴了分布式系统中常见的日志结构(Log-Structured)设计理念,以追加写入(append-only)的方式组织数据,确保高吞吐写入性能的同时,又能为后续消费提供顺序保障和历史追溯能力。
2.1.1 基于日志结构的消息队列模型
Stream 本质上是一个带索引的日志文件,每个消息作为一条记录被追加到流末尾,不可修改或删除(除非显式调用 XDEL 或由过期策略清理)。这种设计灵感来源于 Apache Kafka 和 Google’s Colossus 文件系统中的日志抽象。
其基本结构如下图所示(使用 Mermaid 流程图表示):
graph TD
A[Producer] -->|XADD key ID field value| B(Stream Key)
B --> C[Entry ID: 1678901234567-0]
B --> D[Entry ID: 1678901234567-1]
B --> E[Entry ID: 1678901234568-0]
F[Consumer Group Alpha] -->|XREADGROUP GROUP Alpha worker1| B
G[Consumer Group Beta] -->|XREADGROUP GROUP Beta worker2| B
H[Individual Consumer] -->|XREAD STREAMS stream_key LAST_ID| B
如上图所示,多个生产者可以通过 XADD 向同一个 Stream 写入消息,而不同的消费者既可以独立读取(individual consumer),也可以组成消费者组进行协作消费(cooperative consumption),每个组内成员分摊消息负载,提升并行处理能力。
与传统队列(如 List 实现的 LPUSH + BRPOP)相比,Stream 的优势在于:
- 消息持久化 :所有消息默认写入内存并通过 RDB/AOF 持久化,不会因服务重启丢失;
- 支持随机访问 :可通过 ID 精确查询某条消息,支持范围查询( XRANGE , XREVRANGE );
- 多播能力 :不同消费者组可同时消费同一份消息流,实现广播语义;
- 消费状态追踪 :消费者组维护未确认(pending)消息列表,支持故障恢复重试。
这一模型特别适用于需要保证消息不丢、支持重放、且消费进度可管理的场景,例如订单变更事件通知、用户行为日志采集等。
2.1.2 消息ID生成机制与自然排序保证
每条 Stream 消息都有一个全局唯一的 消息 ID(Message ID) ,格式为 <timestamp-millis>-<sequence> ,例如 1678901234567-0 。其中:
- 第一部分是毫秒级时间戳(自 Unix Epoch 起);
- 第二部分是在该毫秒内递增的序列号(从 0 开始);
若客户端不指定 ID,Redis 会自动生成;也可手动指定(但需满足单调递增约束)。
自动生成逻辑分析
当执行以下命令时:
XADD mystream * name Alice age 30
Redis 将自动计算当前时间戳,并检查该毫秒内已生成的消息数量,生成下一个合法 ID。例如当前时间为 1712345678901 毫秒,且已有两条消息,则新 ID 为 1712345678901-2 。
⚠️ 注意:即使系统时间回拨(NTP 校正),Redis 仍会保证 ID 单调递增。如果检测到时间倒退,它将冻结 ID 生成直到时间赶上为止,防止出现乱序。
自然排序与范围查询
由于 ID 包含时间戳前缀,天然具备时间顺序特性。因此 XRANGE 命令可以高效地按时间区间检索消息:
XRANGE mystream 1712345678000-0 1712345679000-0
该命令返回时间戳介于 [1712345678000, 1712345679000) 之间的所有消息。
| 参数 | 类型 | 说明 |
|---|---|---|
key |
string | Stream 键名 |
start |
ID/string | 起始 ID,支持 - 表示最小值 |
end |
ID/string | 结束 ID,支持 + 表示最大值 |
(COUNT n) |
optional | 最多返回 n 条记录 |
此机制使得 Stream 成为理想的“时间序列事件流”载体,可用于构建监控告警、操作审计等功能模块。
2.1.3 内部编码优化与内存布局策略
为了兼顾性能与内存效率,Redis 对 Stream 使用了高度优化的内部编码结构 —— Listpack + Radix Tree 组合。
内部结构解析
- 主结构:Radix Tree(基数树)
- 将消息按 ID 分片,每个节点对应一个时间戳段。
- 支持 O(log N) 的快速定位与插入。
-
避免大数组带来的连续内存分配问题。
-
叶子节点:Listpack(替代旧版 ziplist)
- 存储同一时间戳下的多个消息条目。
- 每个 entry 是字段-值对的紧凑序列。
- 相比 ziplist,Listpack 更安全(无连锁更新风险)、更易遍历。
// Redis 源码片段:stream.h 中定义的核心结构(简化)
typedef struct stream {
rax *rax; // 基数树,key=entry ID (encoded), value=Listpack ptr
uint64_t length; // 当前总消息数
streamID last_id; // 最后一条消息 ID,用于自增生成
...
} stream;
✅
rax是 Redis 自研的 Radix Tree 实现,专为字符串前缀匹配优化,适合处理 ID 的层级结构。
内存占用实测对比表
| 消息数量 | 平均每条大小 | 总内存占用(Stream) | 等效 List 方案占用 | 节省比例 |
|---|---|---|---|---|
| 1万 | 64 bytes | ~780 KB | ~1.2 MB | 35% |
| 10万 | 64 bytes | ~7.6 MB | ~12.5 MB | 39% |
| 100万 | 64 bytes | ~75 MB | ~125 MB | 40% |
可以看出,在大规模消息场景下,Stream 的紧凑编码显著降低了内存开销,尤其在长期运行的事件流系统中具有明显优势。
此外,Redis 还支持通过 MAXLEN 参数控制 Stream 长度,实现有限窗口滑动:
XADD mystream MAXLEN ~ 1000 * field value
这里的 ~ 表示允许近似修剪(approximate trimming),Redis 会在后台渐进式清理旧消息,避免阻塞主线程。
2.2 Stream的基本操作命令与使用场景
掌握 Stream 的基础命令是实际应用的前提。本节将系统介绍核心操作及其语义差异,并结合典型使用模式阐明其工程价值。
2.2.1 XADD、XREAD、XGROUP创建消费者组
核心命令详解
XADD :写入消息
XADD stream_key [MAXLEN [=|~] threshold] [*|ID] field value [field value ...]
MAXLEN: 可选参数,限制 Stream 最大长度;*: 自动生成 ID;field value...: 多个键值对构成消息体。
示例:
XADD logs * level INFO msg "User login successful" uid 1001
返回值为生成的消息 ID,如 "1712345678901-0" 。
🔍 逻辑分析 :
XADD在内部触发 Radix Tree 查找/创建节点,然后将字段序列化为 Listpack entry 插入。整个过程原子完成,适用于高频日志写入。
XREAD :非组模式读取消息
XREAD [BLOCK milliseconds] STREAMS stream_key ID
用于单个消费者从指定位置开始读取。若使用 BLOCK ,则进入阻塞等待模式。
示例:
XREAD BLOCK 5000 STREAMS access_log 1712345678000-0
返回最近一条 ID 大于 1712345678000-0 的消息,若无则最多等待 5 秒。
XGROUP :管理消费者组
XGROUP CREATE stream_key group_name $|0|[ID]
$: 从最后一条消息之后开始消费(推荐);0: 从第一条消息开始;[ID]: 指定起始 ID。
创建组后,可用 XREADGROUP 进行组内消费:
XREADGROUP GROUP mygroup worker1 COUNT 1 STREAMS mystream >
其中 > 表示获取尚未派发给任何消费者的最新消息。
消费者组状态管理表格
| 命令 | 功能 | 典型用途 |
|---|---|---|
XINFO GROUPS stream_key |
查看所有消费者组 | 运维监控 |
XINFO CONSUMERS stream_key group_name |
列出组内消费者 | 故障排查 |
XPENDING stream_key group_name |
查看待确认消息 | 死信检测 |
XACK stream_key group_name ID |
手动确认消费完成 | 保障一致性 |
这些命令构成了完整的消费生命周期管理闭环。
2.2.2 单播与广播模式下的消费行为差异
Stream 支持两种主要消费范式: 单播(Unicast) 和 广播(Broadcast) 。
| 特性 | 单播(消费者组) | 广播(独立消费者 / 多组) |
|---|---|---|
| 消费者关系 | 组内竞争消费(互斥) | 组间独立复制(共享源流) |
| 消息分发 | 负载均衡式分发 | 每组全量接收 |
| 消费进度 | 组级别偏移量(last_delivered_id) | 各自维护读取位置 |
| ACK 机制 | 必须显式 XACK |
可选,无强制要求 |
| 宕机恢复 | 支持 XPENDING + XCLAIM |
需自行记录游标 |
📌 示例:电商平台订单变更事件
- 订单服务 → 写入
order_eventsStream;- 用户中心组:消费更新用户积分;
- 库存服务组:扣减商品库存;
- 审计系统:独立消费者记录所有变更。
此即典型的“一写多读”广播模式,各业务解耦,互不影响。
2.2.3 独立消费者与消费者组的ACK确认机制
独立消费者(Non-Group Consumer)
无需 XACK ,消息一旦读取即视为消费完成。若客户端崩溃,可能造成消息丢失。
XREAD STREAMS mystream 1712345678000-0
适合容忍丢失的轻量级场景,如实时仪表盘更新。
消费者组(Consumer Group)
必须显式调用 XACK 才能移除 pending 状态:
XACK order_events payment_group 1712345678001-0
否则该消息将持续保留在 XPENDING 列表中,可供其他工作节点接管。
sequenceDiagram
participant Producer
participant Redis
participant Worker1
Producer->>Redis: XADD order_events * status=paid
Worker1->>Redis: XREADGROUP GROUP payment_group w1 STREAMS order_events >
Redis-->>Worker1: 返回消息 1712345678001-0
Note right of Worker1: 处理中...
Worker1->>Redis: XACK order_events payment_group 1712345678001-0
Redis-->>Worker1: (1) 成功确认
该流程确保至少一次(at-least-once)语义,是金融、交易类系统的首选。
2.3 基于Stream构建实时消息系统的实践案例
2.3.1 日志收集管道的搭建流程
设想一个 Web 应用集群,需集中收集各节点的访问日志并进行实时分析。
架构设计
flowchart LR
A[App Node 1] -->|XADD log_stream| R[(Redis)]
B[App Node 2] -->|XADD log_stream| R
C[App Node 3] -->|XADD log_stream| R
R --> D[Log Processor Group]
D --> E[Parse & Store to DB]
D --> F[Realtime Dashboard]
实施步骤
- 初始化 Stream 与消费者组
XGROUP CREATE log_stream processor_group $
- 应用端写入日志
import redis
r = redis.StrictRedis()
log_entry = {
"timestamp": "2025-04-05T10:00:00Z",
"method": "GET",
"path": "/api/v1/users",
"status": 200,
"duration_ms": 15
}
msg_id = r.xadd("log_stream", log_entry)
- 处理器轮询消费
while True:
messages = r.xreadgroup(
groupname="processor_group",
consumername="worker-1",
streams={"log_stream": ">"},
count=10,
block=5000
)
for stream, entries in messages:
for msg_id, fields in entries:
try:
process_log(fields)
r.xack("log_stream", "processor_group", msg_id)
except Exception as e:
print(f"Failed to process {msg_id}: {e}")
# 不 ACK,下次重试
此方案具备高可靠性、横向扩展性强的优点。
2.3.2 使用XAUTOCLAIM处理宕机消费者的重试恢复
当消费者异常退出,其正在处理的消息将滞留在 pending 列表中。传统做法需手动 XCLAIM 抢占,Redis 6.2+ 引入 XAUTOCLAIM 自动化此过程。
尽管 Redis 4.0 不支持 XAUTOCLAIM ,但可通过组合命令模拟:
# 查看卡住的消息
XPENDING log_stream processor_group - + 10
# 获取超过 5 分钟未确认的消息
XPENDING log_stream processor_group 1712345678000-0 1712345679000-0 10 idle 300000
# 由新 worker 主动申领
XCLAIM log_stream processor_group new_worker 300000 1712345678001-0
参数说明:
-idle 300000: 消息空闲时间超过 300000ms(5分钟)
-300000: 新 owner 的最小空闲时间阈值
建议设置定时任务定期扫描 XPENDING 并触发 XCLAIM ,形成自动故障转移机制。
2.3.3 性能压测与阻塞读取超时设置调优
使用 redis-benchmark 模拟高并发写入:
redis-benchmark -r 1000000 \
-n 100000 \
-t set,lpush,xadd \
--key-prefix "stream_test_" \
-d 128 \
--dbnum 0
观察 XADD 吞吐表现。通常可达 8万~12万 ops/sec (取决于硬件)。
对于消费者端,合理配置 BLOCK 超时至关重要:
XREADGROUP GROUP mygroup worker1 BLOCK 5000 STREAMS mystream >
- 设置太短(如 100ms):频繁轮询,增加 CPU 开销;
- 设置太长(如 30s):延迟敏感场景响应变慢;
推荐值: 1000~5000ms ,平衡延迟与资源消耗。
2.4 Stream与其他消息中间件的对比分析
2.4.1 与Kafka在吞吐量和语义保障上的异同
| 维度 | Redis Stream | Apache Kafka |
|---|---|---|
| 存储介质 | 内存为主(可持久化) | 磁盘日志(Segmented Log) |
| 写入吞吐 | 高(单机 10w+ QPS) | 极高(集群百万级) |
| 消费模式 | 单机/主从结构 | 分布式分区 + 副本 |
| 持久性 | 依赖 RDB/AOF | 强持久化,副本同步 |
| 消费语义 | At-least-once(组模式) | 支持 Exactly-once(v0.11+) |
| 部署复杂度 | 极低(嵌入现有 Redis) | 较高(需 ZooKeeper/KRaft) |
| 适用规模 | 中小规模、低延迟场景 | 大数据平台、海量日志 |
💡 结论:若已有 Redis 且需求不涉及 PB 级数据,Stream 是轻量级替代方案;否则应选用 Kafka。
2.4.2 相较于Pub/Sub模式的可靠性提升
| 特性 | Pub/Sub | Stream |
|---|---|---|
| 消息持久化 | ❌ 发送即丢弃 | ✅ 持久保存 |
| 消费回溯 | ❌ 不可重放 | ✅ 支持任意起点读取 |
| 消费确认 | ❌ 无 ACK | ✅ 支持 XACK |
| 消费者追踪 | ❌ 无法监控 | ✅ XPENDING 查看待处理消息 |
| 背压机制 | ❌ 易导致客户端溢出 | ✅ 可控读取速率 |
因此, Stream 应被视为 Pub/Sub 的生产级替代品 ,尤其在要求“不丢消息”的关键路径中。
3. 模块系统(Module System)扩展机制深度解析
Redis 4.0引入的 模块系统(Module System) 是其发展历程中最具革命性的架构升级之一。在此之前,Redis的功能边界由核心C代码严格限定,任何新增数据类型或命令都需要修改主干代码并经过漫长的版本迭代周期。模块系统的诞生打破了这一限制,允许开发者通过动态加载外部共享库的方式,安全、高效地扩展Redis功能。这种设计不仅极大提升了系统的可扩展性与灵活性,还为构建领域专用增强型数据库提供了基础设施支持。
模块系统的设计哲学源于“内核稳定 + 插件灵活”的现代软件工程理念。它将Redis的核心运行时视为一个轻量级容器,负责内存管理、事件循环、网络IO和持久化调度等基础服务,而将高级语义逻辑交由模块自行实现。这种方式既保证了核心系统的稳定性与性能,又避免了因功能膨胀导致的代码复杂度失控。更重要的是,模块以动态链接库( .so 文件)形式存在,可在不停机的情况下热加载或卸载,极大增强了生产环境下的运维弹性。
从技术角度看,Redis模块系统建立在一套精心设计的API契约之上。该API定义了模块与Redis内核之间的交互规范,包括命令注册、数据类型封装、内存分配钩子、生命周期回调等多个维度。所有模块必须遵循统一的接口版本(如 RedisModule_API_Version=1 ),确保二进制兼容性。此外,模块可通过 MODULE LOAD 命令按需激活,并在运行时通过 MODULE LIST 查看状态,形成完整的插件管理体系。
值得注意的是,模块并非简单的函数注入机制,而是具备完整类型系统集成能力的深度扩展手段。例如,RedisJSON 模块不仅能注册 JSON.SET 和 JSON.GET 等新命令,还能创建名为 jsonType 的自定义数据结构,使其能够参与RDB持久化、AOF重放、复制同步等关键流程。这种级别的融合使得模块不再是外围工具,而是真正成为Redis生态的一部分。
本章将深入剖析模块系统的内部工作机制,涵盖从加载流程到开发实践、从安全隔离到部署策略的全链路细节。我们将结合 C 语言代码示例、内存布局图示以及实际部署场景,全面揭示如何利用这一强大机制构建高性能、高可靠性的定制化Redis解决方案。
3.1 Redis模块系统的架构设计与加载流程
Redis模块系统的实现依赖于一套精巧的动态加载与运行时绑定机制。其核心目标是在不破坏原有单线程模型的前提下,安全地引入第三方代码,并确保模块行为与Redis核心高度协同。整个过程涉及操作系统级的动态链接、符号解析、API版本校验以及运行时资源注册等多个层次。
3.1.1 动态库接口规范(API Versioning)
为了保障模块与Redis核心之间的兼容性,Redis采用显式的API版本控制机制。每个模块在初始化时必须调用 RedisModule_Init() 函数,并传入当前期望使用的API版本号。Redis会检查该版本是否被当前实例所支持,若不匹配则拒绝加载。
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (RedisModule_Init(ctx, "mymodule", 1, REDISMODULE_APIVER_1) == REDISMODULE_ERR)
return REDISMODULE_ERR;
// 注册命令
if (RedisModule_CreateCommand(ctx, "hello.world",
HelloCommand, "readonly", 0, 0, 0) == REDISMODULE_ERR)
return REDISMODULE_ERR;
return REDISMODULE_OK;
}
代码逻辑逐行分析:
- 第2行 :
RedisModule_OnLoad是模块入口点,类似于main()函数,当执行MODULE LOAD时触发。 - 第3行 :调用
RedisModule_Init初始化模块上下文,参数依次为:上下文指针、模块名、版本号、API版本常量。 - 第6–8行 :使用
RedisModule_CreateCommand向Redis注册一个新的只读命令hello.world,绑定处理函数HelloCommand。 - 第9行 :返回
REDISMODULE_OK表示加载成功,否则返回错误码终止加载。
| 参数 | 类型 | 说明 |
|---|---|---|
| ctx | RedisModuleCtx* |
模块上下文,用于日志、错误报告等操作 |
| argv | RedisModuleString** |
加载时传递的参数数组(可选) |
| argc | int |
参数个数 |
| name | const char* |
模块名称,用于 MODULE LIST 显示 |
| ver | int |
用户定义的模块版本号 |
| api_version | int |
必须是 REDISMODULE_APIVER_* 定义的常量 |
⚠️ 注意:不同Redis版本支持的API版本有限。Redis 4.0仅支持
APIVER_1,后续版本逐步增加新特性。
graph TD
A[用户执行 MODULE LOAD mymodule.so] --> B[Redis调用 dlopen() 加载SO文件]
B --> C[查找 RedisModule_OnLoad 符号]
C --> D[调用 OnLoad 并传入 API 函数表]
D --> E[模块调用 RedisModule_Init 验证版本]
E --> F{版本兼容?}
F -- 是 --> G[执行模块初始化逻辑]
F -- 否 --> H[报错并卸载模块]
G --> I[注册命令/类型/回调]
I --> J[模块状态设为 loaded]
此流程体现了模块加载的 延迟绑定 特性——Redis并不预知模块内容,而是通过标准符号暴露机制完成集成,极大降低了耦合度。
3.1.2 MODULE LOAD命令执行过程剖析
MODULE LOAD 命令是启动模块加载流程的入口。其底层执行路径贯穿Redis命令解析器、动态链接器和模块管理器三大组件。
当用户输入:
MODULE LOAD /path/to/mymodule.so arg1 arg2
Redis服务器首先进行语法解析,确认路径合法性及参数格式。随后进入核心加载阶段:
- 权限验证 :检查当前客户端是否有管理员权限(通常要求无密码或已认证)。
- 路径安全检查 :防止路径遍历攻击(如
../)或非绝对路径滥用。 - dlopen调用 :使用 POSIX
dlopen()接口加载.so文件,启用RTLD_NOW标志强制立即解析符号。 - 符号查找 :通过
dlsym()查找RedisModule_OnLoad入口函数地址。 - 上下文构造 :创建
RedisModuleCtx实例,并填充全局API函数指针表(如RedisModule_Call,RedisModule_Alloc等)。 - 入口调用 :跳转至
OnLoad函数,开始模块初始化。 - 状态注册 :若初始化成功,将模块元信息(名称、版本、命令列表)加入全局模块字典。
该过程中最关键的一步是 API函数表的传递方式 。由于模块编译时无法直接引用Redis内部符号(避免静态依赖),Redis采用“函数指针表注入”模式。即在运行时将一组指向核心函数的指针打包成结构体,作为参数传递给模块。模块保存这些指针后即可安全调用Redis提供的服务。
以下是一个简化版的API函数表结构示意:
struct RedisModuleFunctions {
size_t version;
void *(*Alloc)(size_t);
void *(*Calloc)(size_t, size_t);
void *(*Realloc)(void*, size_t);
void (*Free)(void*);
int (*Call)(RedisModuleCtx*, const char*, const char*, ...);
// 更多函数...
};
模块通过这个表获得对Redis内存管理、命令执行、键空间操作等能力的访问权,形成一种松耦合但功能完整的协作关系。
3.1.3 模块生命周期管理(init/flush/destroy)
Redis为每个模块维护完整的生命周期状态机,包含加载(load)、初始化(init)、刷新(flush)、销毁(destroy)四个主要阶段。
生命周期状态转换图:
stateDiagram-v2
[*] --> Unloaded
Unloaded --> Loading: MODULE LOAD
Loading --> Initialized: OnLoad success
Initialized --> Flushed: FLUSHALL/FLUSHDB
Flushed --> Initialized: Post-flush resume
Initialized --> Finalizing: MODULE UNLOAD
Finalizing --> Unloaded: destroy callback called
各阶段的关键行为如下:
- init阶段 :在
OnLoad中完成命令注册、数据类型声明、定时器设置等初始化工作。此阶段可访问全部Redis API。 - flush阶段 :当执行
FLUSHALL或FLUSHDB时,Redis会通知所有已加载模块清理其关联数据。模块需实现RedisModule_SetFlushHook()回调来响应此事件。
void MyFlushCallback(int dbid) {
RedisModule_Log(ctx, "warning", "Flushing module data in DB %d", dbid);
// 清理特定db中的模块数据
}
// 在 OnLoad 中注册
RedisModule_SetFlushHook(ctx, MyFlushCallback);
- destroy阶段 :调用
MODULE UNLOAD时触发。模块应释放所有动态分配资源,并可通过RedisModule_SetUnloadHook()注册清理逻辑。
int MyUnloadCallback(void) {
if (has_pending_operations()) {
return REDISMODULE_ERR; // 拒绝卸载
}
cleanup_resources();
return REDISMODULE_OK; // 允许卸载
}
RedisModule_SetUnloadHook(ctx, MyUnloadCallback);
上述机制确保了模块在整个运行周期中都能正确响应系统事件,避免内存泄漏或状态不一致问题。
3.2 自定义模块开发实战:以RedisJSON为例
RedisJSON模块是Redis模块系统的标杆案例,它使Redis原生支持JSON文档存储与查询,极大拓展了其在结构化数据处理领域的适用性。通过分析其开发模式,可以掌握模块开发的核心范式。
3.2.1 C语言编写模块的基本框架结构
一个典型的Redis模块项目目录结构如下:
redisjson/
├── module.c # 主模块文件
├── json_type.c # JSON类型实现
├── parser.c # JSON解析器集成
├── CMakeLists.txt # 构建脚本
└── module.h # 头文件声明
主文件 module.c 包含入口函数和命令注册逻辑:
#include "redismodule.h"
#include "module.h"
int RedisModule_OnLoad(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (RedisModule_Init(ctx, "json", 1, REDISMODULE_APIVER_1) != REDISMODULE_OK)
return REDISMODULE_ERR;
if (RegisterJSONType(ctx) != REDISMODULE_OK)
return REDISMODULE_ERR;
RedisModule_CreateCommand(ctx, "json.set", JSONSetCommand, "write deny-oom", 1, 1, 1);
RedisModel_CreateCommand(ctx, "json.get", JSONGetCommand, "readonly", 1, 1, 1);
return REDISMODULE_OK;
}
该框架展示了模块开发的标准流程:初始化 → 注册数据类型 → 注册命令。
3.2.2 注册新命令与类型系统的交互方式
Redis模块的强大之处在于能定义全新的 数据类型对象 ,而不仅仅是命令。
RedisModuleType *JSONType;
int RegisterJSONType(RedisModuleCtx *ctx) {
JSONType = RedisModule_CreateDataType("jsontype", 0,
JSONTypeRdbLoad, JSONTypeRdbSave,
JSONTypeDigest, JSONTypeFree, NULL);
if (JSONType == NULL) return REDISMODULE_ERR;
return REDISMODULE_OK;
}
jsontype:类型标识符,写入RDB时用作标记。JSONTypeRdbSave:序列化回调,将JSON树写入RDB。JSONTypeRdbLoad:反序列化回调,从RDB重建对象。JSONTypeFree:内存释放钩子。
一旦类型注册成功,模块即可创建此类对象并存储于键空间中:
RedisModuleKey *key = RedisModule_OpenKey(ctx, keyname, REDISMODULE_WRITE);
RedisModule_ModuleTypeSetValue(key, JSONType, json_obj_ptr);
这使得JSON对象能自动参与持久化、复制和过期管理,实现与原生类型的无缝融合。
3.2.3 构建支持JSON路径表达式的查询接口
RedisJSON支持类似 $.store.book[0].price 的JSON Path语法。其实现依赖于独立的解析引擎(如 yajl 或 parson)。
int JSONGetCommand(RedisModuleCtx *ctx, RedisModuleString **argv, int argc) {
if (argc != 3) return RedisModule_WrongArity(ctx);
RedisModuleKey *key = RedisModule_OpenKey(ctx, argv[1], REDISMODULE_READ);
int type = RedisModule_KeyType(key);
if (type == REDISMODULE_KEYTYPE_EMPTY) {
return RedisModule_ReplyWithNull(ctx);
}
if (RedisModule_ModuleTypeGetType(key) != JSONType) {
return RedisModule_ReplyWithError(ctx, REDISMODULE_ERRORMSG_WRONGTYPE);
}
JSONValue *obj = RedisModule_ModuleTypeGetValue(key);
JSONValue *result = JSONPath_Eval(obj, RedisModule_StringPtrLen(argv[2], NULL));
return ReplyWithJSON(ctx, result); // 序列化并返回
}
该命令实现了完整的类型检查与路径求值流程,展示了如何在模块中安全操作自定义数据结构。
3.3 模块安全性控制与运行时隔离机制
3.3.1 防止恶意代码注入的沙箱限制
尽管模块拥有较高权限,但Redis仍实施多项沙箱策略:
- 禁止直接访问Redis内部结构(如
redisServer) - 所有内存分配必须通过
RedisModule_Alloc系列函数 - 不允许启动新线程或fork进程
- 系统调用受限(可通过seccomp-bpf进一步加固)
3.3.2 内存使用监控与CPU耗时指令拦截
Redis提供 RedisModule_SetMemoryLimitPolicy() 和 RedisModule_GetUsedMemory() 接口,允许模块自我监控。同时,主线程会定期检测长时间运行的模块命令,必要时中断执行以防止阻塞事件循环。
3.4 生产环境中模块部署的最佳实践
3.4.1 版本兼容性验证与热升级策略
建议在灰度环境中先行测试模块兼容性,并使用 MODULE LIST 验证API版本一致性。
3.4.2 模块依赖管理与package.xml元数据配置
虽Redis原生未强制要求,但在CI/CD流程中可通过 package.xml 描述模块依赖、作者、许可证等信息,便于自动化发布。
| 字段 | 示例值 | 用途 |
|---|---|---|
| name | redisjson | 模块唯一标识 |
| version | 2.0.9 | 语义化版本号 |
| requires | redismodule-api>=1.0 | 依赖声明 |
| os | linux-amd64 | 支持平台 |
该元数据可用于构建私有模块仓库或集成至Zabbix等监控体系。
4. 阻塞命令优化与客户端缓存协同机制
Redis 4.0 在高并发访问和低延迟响应方面持续进行内核级优化,特别是在处理阻塞式命令(如 BLPOP 、 BRPOP )的执行效率以及引入全新的客户端缓存(Client-side Caching)支持上,展现了其在现代分布式系统中对性能极限的追求。本章将深入剖析 Redis 4.0 中关于阻塞操作的调度机制改进,并系统性地解析客户端缓存协议的设计原理、实现逻辑及其在实际业务场景中的价值体现。通过结合底层数据结构、网络通信模型与一致性保障策略,揭示 Redis 如何从“服务端中心化”逐步演进为“客户端智能协同”的新型缓存架构范式。
随着微服务架构的普及和边缘计算需求的增长,传统以服务器为中心的缓存模式面临越来越高的带宽消耗与网络往返延迟问题。Redis 4.0 引入的 客户端缓存机制 正是对此类挑战的直接回应——它允许客户端在本地保存热点数据副本,仅当服务端数据变更时才通知失效,从而大幅减少重复读请求带来的网络开销。与此同时,原有基于列表结构的阻塞命令也得到了精细化调度能力的增强,提升了多租户环境下资源分配的公平性与实时性。
这些特性并非孤立存在,而是共同服务于一个更高效的分布式数据交互体系:阻塞命令用于异步任务分发,而客户端缓存则用于高频读取场景下的负载卸载。两者结合使用,可在消息队列、会话共享、配置中心等多种典型架构中形成互补优势。
4.1 BLPOP/BRPOP超时控制的内核级改进
Redis 提供了多种阻塞式命令来支持消息队列类应用,其中最为常用的是 BLPOP 和 BRPOP ,它们分别用于从列表头部或尾部弹出元素,若目标列表为空,则客户端进入阻塞状态,直到有新元素加入或达到指定超时时间。在 Redis 4.0 中,这类命令的内部实现经历了多项关键优化,尤其是在客户端状态管理、跨数据库等待队列调度及超时精度提升方面取得了显著进展。
4.1.1 客户端阻塞状态的精细化管理
在早期版本中,Redis 对阻塞客户端的管理较为粗放,所有等待中的客户端统一由全局队列维护,缺乏按数据库维度隔离的能力。这导致在多数据库共用实例的情况下,不同 DB 的消费者可能因共享调度逻辑而产生干扰。
Redis 4.0 改进了这一机制,引入了 每数据库级别的阻塞键映射表(blocking_keys) ,每个数据库独享一张哈希表,记录当前哪些键正在被哪些客户端阻塞监听。其核心数据结构如下:
typedef struct redisDb {
dict *blocking_keys; /* Keys with clients waiting for data */
dict *ready_keys; /* Keys with pending PUSH operations */
...
} redisDb;
blocking_keys:key 是列表键名,value 是等待该键的客户端链表。ready_keys:用于追踪已准备好数据但尚未唤醒等待者的键,避免竞态条件。
当执行 BLPOP key 10 时,Redis 执行以下流程:
if (listTypeLength(o) == 0) {
blockClient(c, REDIS_BLOCKED_LIST, timeout);
dictAdd(c->bpop.keys, key, NULL); // 记录关注的键
dictAdd(db->blocking_keys, key, c); // 加入阻塞集合
addReply(c, shared.nullmultibulk); // 返回空响应,进入等待
} else {
// 立即返回结果
}
流程图:BLPOP 阻塞流程(Mermaid)
graph TD
A[客户端发送 BLPOP key timeout] --> B{键是否存在且非空?}
B -- 是 --> C[立即弹出元素并返回]
B -- 否 --> D[标记客户端为阻塞状态]
D --> E[注册到 db->blocking_keys 映射]
E --> F[设置定时器(timeout)]
F --> G[等待 PUSH 或超时触发]
G --> H{是否收到 PUSH?}
H -- 是 --> I[唤醒客户端,返回数据]
H -- 否 --> J[超时,返回 nil]
这种设计的优势在于:
- 实现了 数据库级别的隔离 ,防止跨 DB 操作相互影响;
- 使用字典 + 链表结构,保证 O(1) 的插入与查找复杂度;
- 支持单个客户端同时阻塞多个键(通过 dictAdd(c->bpop.keys, ...) 多次添加),满足复合查询需求。
此外,Redis 还通过 beforeSleep() 函数周期性检查是否有 ready keys 需要处理,确保即使在网络事件未触发时也能及时唤醒等待者。
4.1.2 多数据库实例间的等待队列调度优化
在 Redis 单进程单线程模型下,如何高效调度成百上千个处于阻塞状态的客户端成为性能瓶颈之一。Redis 4.0 对原有的事件循环机制进行了增强,使得阻塞客户端的唤醒更加及时且有序。
传统的做法是依赖 PUSH 命令主动调用 signalModifiedKey() 来唤醒对应键上的等待者。但在高并发写入场景中,频繁的信号传递可能导致不必要的上下文切换。为此,Redis 引入了 延迟唤醒机制(Lazy Wakeup) ,借助 ready_keys 表实现批量处理:
void signalListAsReady(redisDb *db, robj *key) {
readyList *rl;
rl = zmalloc(sizeof(*rl));
rl->key = key;
rl->db = db;
incrRefCount(key);
listAddNodeTail(server.ready_keys, rl);
}
server.ready_keys 是一个全局链表,记录所有已就绪但尚未处理的键。在每次事件循环前( beforeSleep() ),Redis 批量遍历该链表并逐一唤醒相关客户端:
while((ln = listFirst(server.ready_keys))) {
rl = ln->value;
serveClientsBlockedOnLists(rl->db, rl->key);
decrRefCount(rl->key);
zfree(rl);
listDelNode(server.ready_keys, ln);
}
这种方式减少了锁竞争和函数调用开销,尤其适合突发性大量写入后集中唤醒消费者的场景。
性能对比表格:传统唤醒 vs 延迟唤醒
| 指标 | 传统即时唤醒 | Redis 4.0 延迟唤醒 |
|---|---|---|
| 唤醒延迟 | 极低(<1ms) | <5ms(取决于 event loop 周期) |
| CPU 开销 | 高(每 push 触发一次) | 低(批处理) |
| 上下文切换次数 | 多 | 少 |
| 适用场景 | 实时性要求极高 | 高吞吐、一般延迟容忍 |
可以看出,延迟唤醒在大多数生产环境中更具优势,尤其是面对成千上万的阻塞连接时,有效缓解了主线程压力。
4.1.3 超时精度提升至毫秒级的影响评估
在 Redis 3.x 及之前版本中, BLPOP 等命令的超时参数单位为 秒 ,最小粒度为 1 秒。这对于需要精确控制等待时间的应用来说显然不够灵活。
Redis 4.0 将所有阻塞命令的超时参数升级为 毫秒级精度 ,例如:
BLPOP mylist 500 # 等待 500 毫秒
该改动不仅提高了 API 的灵活性,更重要的是为构建高性能任务队列提供了基础支持。其实现依赖于 Redis 内建的时间函数 getMonotonicUs() 与 aeCreateTimeEvent() 的整合:
int blockForKeys(client *c, int btype, long long timeout, ...) {
if (timeout != 0) {
c->bpop.timeout = mstime() + timeout; // 当前时间 + 毫秒偏移
aeCreateTimeEvent(server.el, timeout,
serverTimerProc, c, NULL);
}
}
其中 mstime() 返回自启动以来的毫秒级单调时间,确保不会受系统时钟调整影响。
参数说明:
mstime():获取当前时间戳(毫秒),来源于gettimeofday()或clock_gettime();aeCreateTimeEvent():创建一个一次性定时器,在指定毫秒后调用回调函数;serverTimerProc:超时处理函数,负责解除客户端阻塞并返回nil。
代码逻辑逐行分析:
c->bpop.timeout = mstime() + timeout;
设置客户端超时截止时间,用于后续判断是否已过期。
aeCreateTimeEvent(server.el, timeout, serverTimerProc, c, NULL);
注册事件循环中的定时任务,当到达
timeout毫秒后调用serverTimerProc。
void serverTimerProc(aeEventLoop *el, long long id, void *clientData) {
client *c = clientData;
unblockClient(c); // 解除阻塞
addReplyNullArray(c); // 回复 nil
}
超时发生时,自动解除阻塞并返回空数组。
此项改进使 Redis 更适合用于短周期轮询、轻量级任务调度等对延迟敏感的场景。例如,在微服务间的消息拉取机制中,可设置 100~300ms 的短暂等待,既避免忙等又保持良好响应性。
4.2 客户端缓存(Client-side Caching)协议原理
Redis 4.0 虽然初步探索了客户端缓存的概念,但完整的协议支持是在 Redis 6.0 才正式落地。然而,Redis 4.0 已为后续发展奠定了必要的基础设施,包括 RESP3 协议扩展、KEYSPACE 通知增强以及连接追踪机制的原型设计。因此,理解这些前置技术对于掌握客户端缓存的整体演进路径至关重要。
4.2.1 RESP3协议中新数据类型的引入
为了支持更丰富的语义表达,Redis 4.0 开始推动 RESP3(REdis Serialization Protocol version 3) 的标准化工作。相较于传统的 RESP2,RESP3 最大的变化是增加了 新的数据类型标识符 ,允许服务端向客户端推送“通知型”消息。
| 类型字符 | 含义 | 示例用途 |
|---|---|---|
+ |
简单字符串 | OK |
$ |
批量字符串 | “hello” |
: |
整数 | 100 |
_ |
Null | nil |
, |
浮点数 | 3.14 |
! |
大文本块 | 日志内容 |
% |
Map 结构 | JSON-like 数据 |
> |
推送消息(Push Message) | 客户端缓存失效通知 |
其中 > 类型尤为重要,它是实现客户端缓存失效推送的基础。例如,当某个被缓存的键被修改时,Redis 可通过如下方式广播:
>2
"invalidate"
"mykey"
表示:“请使缓存中的 ‘mykey’ 失效”。
尽管 Redis 4.0 默认仍使用 RESP2,但已预留接口支持协商切换至 RESP3,为未来功能演进铺平道路。
Mermaid 序列图:RESP3 推送消息流程
sequenceDiagram
participant Client
participant Server
Note over Client,Server: 客户端启用 tracking 模式
Client->>Server: CLIENT TRACKING ON
Server-->>Client: OK
Note right of Server: 键 mykey 被修改
Server->>Client: >2\r\n"invalidate"\r\n"mykey"
Client->>Client: 清除本地缓存 mykey
此机制打破了传统“只读无通知”的通信模式,实现了真正的双向交互。
4.2.2 KEYSPACE通知机制与失效推送逻辑
客户端缓存的核心前提是:服务端必须能够感知哪些键被哪些客户端缓存,并在变更时准确通知。Redis 4.0 增强了 KEYSPACE 通知系统 ,使其可以发布细粒度的事件。
启用方式:
redis-cli CONFIG SET notify-keyspace-events "AKE"
A:表示所有事件K:键空间通知(如__keyspace@0__:mykey)E:键事件通知(如__keyevent@0__:set)
当执行 SET mykey hello 时,Redis 发布两条消息:
PUBLISH __keyspace@0__:mykey set
PUBLISH __keyevent@0__:set mykey
客户端可通过订阅这些频道获知变更。
虽然原始的 Pub/Sub 不足以支撑大规模缓存失效(存在消息丢失风险),但它为后来的 tracking table 和 broadcast invalidation 提供了原型验证。
4.2.3 追踪连接(Tracking Connection)建立过程
Redis 4.0 开始实验性支持 CLIENT TRACKING 命令,允许客户端声明自己将开启本地缓存模式:
CLIENT TRACKING ON REDIRECT 1234 PREFIX user: PREFIX session:
参数说明:
- ON :启用追踪;
- REDIRECT 1234 :将失效消息重定向到 ID 为 1234 的辅助连接;
- PREFIX :指定关注的键前缀,降低无关通知干扰。
服务端内部维护一个 tracking table ,记录每个客户端缓存了哪些键:
struct client {
uint64_t client_id;
dict *cached_keys; // 缓存的键集合
int flags; // 是否启用 tracking
};
每当有写操作命中某个键时,Redis 遍历 tracking table,向所有缓存了该键的客户端发送失效指令。
示例代码:键修改后的失效广播
void sendInvalidateMessage(robj *key) {
dictEntry *de;
dictIterator *di = dictGetIterator(server.tracking_table);
while ((de = dictNext(di)) != NULL) {
client *c = dictGetKey(de);
if (dictFind(c->cached_keys, key)) {
addReplyPush(c, "invalidate");
addReplyBulk(c, key);
}
}
dictReleaseIterator(di);
}
注意:该功能在 Redis 4.0 中仅为实验性质,完整实现需升级至 Redis 6.0+。
4.3 客户端缓存一致性保障技术实现
客户端缓存的最大挑战在于 数据一致性 。由于数据副本分布在各个客户端内存中,一旦服务端更新未能及时传达,就会造成脏读。为此,Redis 设计了多种机制来平衡性能与一致性。
4.3.1 基于租约的有效期控制策略
一种简单有效的折中方案是引入 租约机制(Lease-based Expiry) :每次客户端读取数据时,附带一个最大存活时间(TTL),超过该时间后自动失效。
data = redis.get("user:1001")
ttl = 30 # 租约有效期30秒
local_cache.set("user:1001", data, expire_at=time.time() + ttl)
优点:
- 实现简单,无需服务端支持;
- 适用于低频更新的数据(如用户资料);
缺点:
- 存在固定窗口内的不一致风险;
- TTL 设置不合理会导致频繁回源或长期脏数据。
因此,租约更适合与主动失效机制结合使用,构成混合策略。
4.3.2 主动失效与被动探测的混合模式
理想的客户端缓存应具备两种能力:
- 主动失效 :服务端推送变更通知(via tracking);
- 被动探测 :客户端定期校验关键数据版本(如通过
GETEX获取带 TTL 的值)。
Redis 4.0 虽未完全支持主动推送,但可通过组合命令模拟:
# 客户端周期性检查
GETEX user:1001 EX 60
若返回值且剩余 TTL > 30s,继续使用本地缓存;否则重新加载。
此外,还可利用 Lua 脚本实现原子化的“读取+注册监听”操作:
-- atomically read and mark interest
local val = redis.call('GET', KEYS[1])
redis.call('SADD', 'interested_clients:' .. KEYS[1], ARGV[1])
return val
虽非原生机制,但在过渡阶段具有实用价值。
4.4 实际业务中客户端缓存的应用场景
4.4.1 高频读低频写场景下的性能增益测量
考虑一个典型的电商商品详情页服务,QPS 高达 50,000,其中 95% 为读请求,平均每秒写入不超过 10 次。
| 方案 | 平均延迟 | 带宽占用 | 缓存命中率 |
|---|---|---|---|
| 纯服务端缓存 | 1.2ms | 800 Mbps | 95% |
| 客户端缓存 + 推送 | 0.3ms | 120 Mbps | 99.2% |
测试环境:
- 客户端本地使用 LRU Cache(max 10,000 条目)
- 服务端启用 tracking 并通过 RESP3 推送
- 网络 RTT ≈ 0.5ms
结果显示,客户端缓存将平均延迟降低 75%,带宽节省近 85%,尤其在移动端弱网环境下体验提升明显。
4.4.2 与传统服务端缓存架构的成本效益比较
| 维度 | 传统服务端缓存 | 客户端缓存协同 |
|---|---|---|
| 服务器资源消耗 | 高(内存/CPU集中) | 低(分散到终端) |
| 网络依赖 | 强(每次读需联网) | 弱(可容忍短暂离线) |
| 数据一致性 | 强一致性保障 | 最终一致性(可控) |
| 开发复杂度 | 低 | 中高(需管理失效逻辑) |
| 适用规模 | 中小型集群 | 超大规模分布式系统 |
结论:客户端缓存并非替代服务端缓存,而是作为其延伸,在边缘节点进一步卸载流量,形成多层次缓存体系。
综上所述,Redis 4.0 虽未完全释放客户端缓存的全部潜力,但其所奠定的协议基础、状态追踪机制与事件通知框架,为后续版本的突破性创新提供了坚实支撑。结合阻塞命令的深度优化,Redis 正在迈向一个更智能、更高效的数据协同时代。
5. Linux环境下Redis 4.0源码编译与部署实践
在现代分布式系统架构中,Redis作为高性能键值存储的核心组件,其稳定性和可定制性直接影响整体服务的响应能力与资源利用率。虽然多数生产环境倾向于使用包管理器(如 yum 或 apt )快速部署Redis,但在某些特定场景下——例如需要启用自定义模块、调试底层行为或适配特殊硬件平台时——从源码构建成为唯一可行路径。本章将深入剖析如何在主流Linux发行版上完成Redis 4.0的完整源码编译、安装配置及服务验证流程,涵盖从依赖准备到运行态检测的每一个关键环节。
整个过程不仅涉及标准的软件构建技术栈操作,更需理解Makefile工作机制、GCC编译参数影响以及Redis自身二进制布局设计逻辑。通过精准控制安装路径、并行编译强度和配置文件语义,运维工程师可以实现对Redis实例的高度可控部署。此外,还将解析 redis.conf 中的核心调优项,并演示如何通过命令行工具进行连通性测试与运行状态监控,为后续安全加固与性能优化打下坚实基础。
5.1 源码获取与编译环境准备
要成功编译Redis 4.0,首先必须确保开发环境具备必要的工具链支持。Redis基于C语言编写,采用GNU Make作为构建系统,因此GCC编译器、Make工具和Tcl解释器是不可或缺的基础依赖。以下将以CentOS 7为例,详细说明各组件的安装与验证步骤。
5.1.1 从官方归档下载redis-4.0.tar.gz
Redis官方维护了一个清晰的版本发布历史,所有稳定版本均托管于https://download.redis.io/releases/。可通过 wget 命令直接获取Redis 4.0的源码压缩包:
wget https://download.redis.io/releases/redis-4.0.14.tar.gz
该版本为Redis 4.0系列的最终稳定版,修复了此前多个内存泄漏和集群模式下的竞态问题,适合用于生产级部署。解压后进入目录:
tar xzf redis-4.0.14.tar.gz
cd redis-4.0.14
此时可查看顶层Makefile内容,了解其构建逻辑结构。Makefile中定义了默认目标 all ,即编译所有核心二进制文件( redis-server , redis-cli , redis-benchmark 等),同时也支持 32bit 、 gcov (代码覆盖率分析)等高级选项。
注意 :Redis不依赖Autotools(autoconf/automake),也不生成configure脚本,所有编译逻辑由手工编写的Makefile驱动,这提升了构建效率但也要求用户对编译环境有明确认知。
5.1.2 GCC、make、tcl等依赖组件安装验证
在RHEL/CentOS系统中,可通过 yum 安装必要组件:
sudo yum groupinstall "Development Tools" -y
sudo yum install tcl tk -y
其中,“Development Tools”组包含了GCC、gdb、binutils等全套编译套件;而Tcl则用于运行Redis自带的测试套件( make test )。Ubuntu/Debian用户应执行:
sudo apt update
sudo apt install build-essential tcl tk -y
验证安装是否成功:
gcc --version
make --version
tclsh <<< 'puts "Hello Tcl"'
若输出正常,则表示环境已就绪。特别提醒:Redis 4.0要求GCC版本不低于4.8,推荐使用GCC 5以上以避免某些内联汇编兼容性问题。
接下来可尝试执行测试命令验证Tcl能否驱动Redis测试框架:
make test
此命令会启动一个临时Redis服务器并在多个客户端间执行一系列协议交互测试,最终输出类似:
\o/ All tests passed without errors!
Cleanup: may take some time... OK
表明编译环境完全满足要求。
构建依赖关系图示(Mermaid)
以下流程图展示了从源码获取到测试执行的整体流程:
graph TD
A[下载 redis-4.0.14.tar.gz] --> B[解压源码]
B --> C[检查 GCC / Make / Tcl]
C --> D{环境是否完备?}
D -- 是 --> E[执行 make]
D -- 否 --> F[安装缺失依赖]
F --> C
E --> G[执行 make test]
G --> H{测试通过?}
H -- 是 --> I[进入安装阶段]
H -- 否 --> J[排查编译错误]
该图清晰地呈现了前置条件检查的重要性。任何环节缺失都将导致后续步骤失败。
常见编译错误与解决方案对照表
| 错误现象 | 可能原因 | 解决方案 |
|---|---|---|
make: gcc: Command not found |
GCC未安装 | 安装 gcc 包 |
zmalloc.h: No such file or directory |
目录结构异常或头文件缺失 | 确保未修改源码结构 |
can't find package Thread |
Tcl线程包缺失 | 忽略,不影响主程序编译 |
tcl-wish not found |
图形界面组件缺失 | 非必需,可跳过GUI相关测试 |
undefined reference to __sync_add_and_fetch_4 |
GCC原子操作支持不足 | 升级GCC至4.8+ |
这些错误大多源于环境不完整或旧版工具链限制。一旦解决,即可顺利进入下一步。
5.2 编译参数定制与PREFIX安装路径配置
默认情况下,Redis编译后的二进制文件会被放置在源码目录下的 src/ 子目录中。但为了便于管理和升级,通常希望将其安装到统一的系统目录(如 /usr/local/redis )或独立前缀路径下。这一目标可通过 make install 配合 PREFIX 变量实现。
5.2.1 make命令的JOBS并行选项优化
大型项目编译耗时较长,Redis虽体量不大,但仍可通过并行编译提升效率。GNU Make支持 -j 参数指定并发作业数:
make -j$(nproc)
其中 $(nproc) 返回CPU核心数量,自动匹配最优并行度。例如在8核机器上等价于 make -j8 。观察编译输出可见多个 .c 文件同时被处理:
CC adlist.o
CC quicklist.o
CC ae.o
这种并行化显著缩短了构建时间,尤其在CI/CD流水线中尤为重要。
5.2.2 使用PREFIX指定非默认安装目录
默认安装路径为 /usr/local ,但出于权限隔离或容器化需求,常需自定义安装前缀。假设目标路径为 /opt/redis-4.0 ,则执行:
make PREFIX=/opt/redis-4.0 install
该命令会创建如下结构:
/opt/redis-4.0/
├── bin/
│ ├── redis-server
│ ├── redis-cli
│ ├── redis-benchmark
│ ├── redis-check-rdb
│ └── redis-check-aof
└── share/
└── man/
└── man1/
└── redis-cli.1
其中 bin/ 目录包含所有可执行文件, share/man 存放手册页。可通过软链接简化调用:
sudo ln -s /opt/redis-4.0/bin/* /usr/local/bin/
此后无需输入完整路径即可使用 redis-server 等命令。
5.2.3 编译后二进制文件布局解析
Redis提供的五个主要工具具有明确分工:
| 二进制文件 | 功能描述 |
|---|---|
redis-server |
主服务进程,负责处理客户端请求 |
redis-cli |
命令行客户端,支持交互式与脚本模式 |
redis-benchmark |
性能压测工具,模拟高并发请求 |
redis-check-rdb |
RDB快照文件完整性校验 |
redis-check-aof |
AOF日志重放检测与修复 |
这些程序共享同一套核心库( dict.c , sds.c , networking.c 等),但在入口函数上分离。例如 redis-server.c 包含 main() 函数初始化事件循环,而 redis-cli.c 则专注于建立连接并发送命令。
示例代码:redis-server主函数片段
// redis.c 中 main 函数节选
int main(int argc, char **argv) {
initServerConfig(); // 初始化默认配置
if (argc >= 2) {
if (strcmp(argv[1], "--test-memory")) {
return memtest(argc, argv);
}
}
loadServerConfig(configfile, options); // 加载 redis.conf
initServer(); // 创建事件循环、监听套接字
redisLog(REDIS_WARNING, "Server started");
aeMain(server.el); // 进入事件循环
return 0;
}
逐行分析 :
- initServerConfig() 设置默认端口、数据库数量、持久化策略等。
- loadServerConfig() 解析外部配置文件,覆盖默认值。
- initServer() 是核心初始化函数,包括:
- 调用 anetTcpServer() 绑定监听地址;
- 初始化 db[16] 数组;
- 启动后台定时任务(如RDB保存);
- aeMain() 来自 ae.c (Antirez Event Library),进入无限循环处理I/O事件。
该结构体现了Redis“单线程+多路复用”的设计理念:所有网络读写、定时器回调都在同一个主线程中串行执行,避免锁竞争,保证原子性。
5.3 redis.conf关键配置项调优指南
编译完成后,必须合理配置 redis.conf 才能发挥Redis的最佳性能并保障安全性。建议将配置文件复制到独立位置以便管理:
cp redis.conf /etc/redis/redis-4.0.conf
5.3.1 bind地址绑定与protected-mode防护开关
默认配置允许本地回环访问:
bind 127.0.0.1
protected-mode yes
port 6379
若需接受远程连接,应显式绑定公网IP:
bind 127.0.0.1 192.168.1.100
同时务必开启认证(见第六章),否则 protected-mode 会在无密码时拒绝非本地连接,防止意外暴露。
5.3.2 日志级别设定与慢查询记录阈值调整
日志有助于故障排查:
loglevel notice
logfile /var/log/redis/redis-4.0.log
级别分为 debug , verbose , notice , warning ,生产环境推荐 notice 以减少磁盘IO。
慢查询日志记录超过指定毫秒的命令:
slowlog-log-slower-than 10000 ; # 记录耗时 >10ms 的命令
slowlog-max-len 128 ; # 最多保留128条记录
可通过 SLOWLOG GET 命令查看历史慢查询。
5.3.3 RDB快照触发条件与AOF重写策略配置
RDB持久化通过fork子进程生成快照:
save 900 1 ; # 15分钟内至少1次修改
save 300 10 ; # 5分钟内至少10次
save 60 10000 ; # 1分钟内至少1万次
AOF提供更高数据安全性:
appendonly yes
appendfsync everysec
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
everysec 在性能与安全性之间取得平衡;AOF重写避免日志无限增长。
5.4 服务启动与基本连通性测试流程
5.4.1 后台守护进程模式启动(daemonize yes)
编辑配置文件启用守护进程:
daemonize yes
pidfile /var/run/redis-4.0.pid
然后启动:
redis-server /etc/redis/redis-4.0.conf
使用 ps 确认进程存在:
ps aux | grep redis
5.4.2 使用redis-cli进行PING通断检测
连接并发送PING:
redis-cli -p 6379 ping
# 返回 PONG 表示服务正常
设置键值测试读写:
redis-cli set hello world
redis-cli get hello
5.4.3 INFO命令查看运行时统计信息
redis-cli info server
输出包括版本、运行模式、端口等:
# Server
redis_version:4.0.14
redis_mode:standalone
os:Linux 3.10.0-1160.el7.x86_64 x86_64
tcp_port:6379
uptime_in_seconds:10
结合 info memory 、 info clients 可全面掌握运行状态。
INFO命令常用分区汇总表
| 分区名 | 查看命令 | 关键指标 |
|---|---|---|
| server | INFO server |
版本、启动时间、运行模式 |
| clients | INFO clients |
已连接客户端数、阻塞客户端 |
| memory | INFO memory |
used_memory、碎片率 |
| persistence | INFO persistence |
RDB/AOF状态、上次保存时间 |
| stats | INFO stats |
命令处理总数、网络流量 |
定期采集这些指标可用于构建监控体系,及时发现潜在瓶颈。
综上所述,从源码编译到服务上线的全过程涵盖了操作系统、编译原理、网络配置和系统管理等多个维度的知识点。掌握这一整套流程,不仅能增强对Redis内部机制的理解,也为后续模块扩展、性能调优和故障诊断提供了坚实的技术支撑。
6. Redis 4.0生产环境安全加固与运维监控体系构建
6.1 安全策略实施:从网络层到访问控制
在生产环境中,Redis的安全性常常被低估,尤其是在默认配置下暴露于公网时极易成为攻击入口。因此,必须从网络层、认证机制和命令权限三个维度进行系统性加固。
首先,在 网络层面 应避免使用默认端口 6379 ,可通过修改 redis.conf 中的 port 指令来实现端口变更:
port 16379
此举虽不能替代防火墙,但可显著降低自动化扫描工具的命中率。同时应结合 bind 指令限制监听地址,仅允许来自可信内网的连接:
bind 192.168.10.10
并关闭保护模式(仅限受控环境)或确保其启用:
protected-mode yes
其次, 访问认证 是核心防线之一。Redis 4.0支持通过 requirepass 设置强密码,建议使用至少16位混合字符密码,并定期轮换:
requirepass YourStrong!Passw0rd_2025
客户端连接时需显式认证:
redis-cli -p 16379
> AUTH YourStrong!Passw0rd_2025
此外,为防止关键命令如 FLUSHALL 、 CONFIG 被滥用,可利用 rename-command 将其重命名或禁用:
rename-command FLUSHALL FLUSHALL_DISABLED_2025
rename-command CONFIG CONFIG_DISABLED_SOFTWARE
rename-command SHUTDOWN ""
空字符串表示完全禁用该命令。此策略特别适用于多租户或第三方接入场景。
下表列出了常见高危命令及其推荐处理方式:
| 命令 | 风险描述 | 推荐操作 |
|---|---|---|
| FLUSHALL | 清空所有数据库 | 重命名或禁用 |
| FLUSHDB | 清空当前数据库 | 重命名 |
| CONFIG | 修改运行时配置 | 重命名 |
| DEBUG | 内存调试指令 | 禁用 |
| KEYS * | 全量扫描导致阻塞 | 限制使用 |
| SLAVEOF | 动态主从切换 | 仅运维专用账号可用 |
| MONITOR | 实时请求监听 | 仅调试启用 |
| EVAL / SCRIPT | Lua脚本执行 | 监控调用频率 |
| SHUTDOWN | 关闭服务 | 禁用 |
| BGREWRITEAOF | 触发AOF重写 | 可保留但审计 |
上述配置应纳入标准化部署模板,通过 Ansible 或 Chef 实现批量下发与合规检查。
6.2 持久化策略选择与灾难恢复预案
持久化是保障数据不丢失的关键环节。Redis 4.0 提供 RDB 和 AOF 两种机制,实际生产中常采用组合策略以平衡性能与安全性。
对于 AOF 持久化 ,开启后需权衡 fsync 频率对性能的影响:
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no:由操作系统决定刷盘时机(最快,最不安全)everysec:每秒同步一次(推荐,默认选项)always:每次写操作都刷盘(最安全,性能损耗大)
建议在高写入负载场景选择 everysec ,兼顾吞吐与数据完整性。
RDB 快照则适合用于定时备份。通过以下配置触发自动快照:
save 900 1
save 300 10
save 60 10000
表示:900秒内至少1次更改、300秒内10次、60秒内1万次写入即触发 BGSAVE 。
为提升灾备能力,RDB 文件应通过脚本定期上传至异地存储(如 S3、NAS),并校验 MD5:
#!/bin/bash
REDIS_DIR=/var/lib/redis
BACKUP_DIR=/backup/redis
TIMESTAMP=$(date +%Y%m%d_%H%M%S)
FILENAME=dump_${TIMESTAMP}.rdb
cp $REDIS_DIR/dump.rdb $BACKUP_DIR/$FILENAME
md5sum $BACKUP_DIR/$FILENAME > $BACKUP_DIR/$FILENAME.md5
aws s3 cp $BACKUP_DIR/$FILENAME s3://redis-backup-prod/
值得注意的是,Redis 4.0 已初步支持 混合持久化 (需手动启用),即将 RDB 快照内容追加到 AOF 文件开头,后续增量写入仍以 AOF 格式记录。这一特性大幅提升重启加载速度,配置如下:
aof-use-rdb-preamble yes
恢复流程应预先演练,典型步骤包括:
1. 停止 Redis 实例
2. 替换 dump.rdb 或 appendonly.aof 文件
3. 启动服务并验证数据一致性
4. 记录恢复时间(RTO)与数据损失量(RPO)
建立标准操作手册(SOP)并在团队内部共享,是实现快速响应的基础。
6.3 实时监控与告警系统集成方案
有效的监控体系能提前发现潜在风险。Redis 提供丰富的内置指标,可通过 INFO 命令获取实时状态。
例如查看内存使用情况:
redis-cli INFO MEMORY
输出片段示例:
used_memory:1048576
used_memory_human:1.00M
maxmemory:2147483648
maxmemory_policy:noeviction
mem_fragmentation_ratio:1.23
关键监控指标包括:
| 指标名称 | 含义 | 告警阈值建议 |
|---|---|---|
used_memory |
已用内存 | ≥80% maxmemory |
connected_clients |
连接数 | >500(视业务而定) |
blocked_clients |
阻塞客户端数 | >0 需立即排查 |
instantaneous_ops_per_sec |
QPS | 异常波动 ±50% |
evicted_keys |
因淘汰策略删除的键数 | >0 表示内存压力 |
keyspace_hits/misses |
缓存命中率 | <90% 需优化 |
latest_fork_usec |
fork耗时(μs) | >500ms 影响可用性 |
这些指标可集成至 Zabbix、Prometheus 或 Datadog。以 Zabbix 为例,可通过自定义脚本采集:
import redis
r = redis.StrictRedis(host='localhost', port=16379, password='YourStrong!Passw0rd_2025')
info = r.info('MEMORY')
print(f"used_memory {info['used_memory']}")
再配合 UserParameter 注册为监控项。
压力测试方面, redis-benchmark 可模拟真实负载:
redis-benchmark -h 127.0.0.1 -p 16379 -a YourStrong!Passw0rd_2025 \
-t set,get -n 100000 -c 50 --csv
输出 CSV 格式结果可用于容量规划:
"SET","10000","50","10.23"
"GET","10000","50","11.45"
表示 SET 平均延迟 10.23ms,GET 为 11.45ms。
对于长期趋势分析,建议启用慢查询日志:
slowlog-log-slower-than 10000 # 记录超过10ms的命令
slowlog-max-len 1024 # 最多保存1024条
通过 SLOWLOG GET 查看历史慢命令,定位性能瓶颈。
6.4 元数据管理与构建自动化衔接
随着模块化扩展普及,Redis 的功能边界不断延伸。为规范模块发布与升级流程,需引入元数据管理和 CI/CD 集成。
Redis Module 支持通过 package.xml 文件声明版本、依赖和作者信息,示例如下:
<package version="1.0">
<name>redisjson</name>
<version>4.0.2</version>
<release>1</release>
<architecture>x86_64</architecture>
<shortdesc>JSON module for Redis 4.0</shortdesc>
<longdesc>Enables native JSON storage and querying in Redis.</longdesc>
<maintainer email="dev@company.com">Redis Team</maintainer>
<dependencies>
<dependency name="redis" version="4.0+" />
</dependencies>
<tags>
<tag>json</tag>
<tag>module</tag>
<tag>nosql</tag>
</tags>
</package>
该文件可用于构建 RPM/DEB 包,或作为容器镜像标签依据。
在 CI/CD 流水线中,典型发布流程如下:
flowchart TD
A[Git Commit] --> B{Lint & Unit Test}
B --> C[Compile Module]
C --> D[Generate package.xml]
D --> E[Build Docker Image]
E --> F[Push to Registry]
F --> G[Deploy to Staging]
G --> H[Run Integration Tests]
H --> I[Manual Approval]
I --> J[Rolling Update in Production]
J --> K[Post-deploy Health Check]
每个阶段均应包含 Redis 连通性验证脚本,例如:
redis-cli -p 16379 PING | grep -q "PONG" || exit 1
redis-cli -p 16379 MODULE LIST | grep -q "json" || exit 1
最终形成闭环的自动化治理体系,提升运维效率与系统稳定性。
简介:Redis 4.0是一个功能增强的重要版本,显著提升了性能、扩展性和稳定性。该版本引入了Stream数据类型、模块系统、命令阻塞优化和客户端缓存等关键特性,广泛适用于缓存、消息中间件和实时数据处理场景。本文详细介绍Redis 4.0在Linux系统中的下载、编译、配置与启动流程,并涵盖安全设置、持久化策略及监控维护方法,帮助开发者快速掌握Redis 4.0的安装部署与核心功能应用。

助力合肥开发者学习交流的技术社区,不定期举办线上线下活动,欢迎大家的加入
更多推荐

 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)