
程序员必藏:大模型全生命周期开源框架指南:微调、训练、部署一站式解决方案
文章系统梳理了11个关键开源框架,覆盖大语言模型全生命周期。从微调工具(Hugging Face Transformers、DeepSpeed、LLaMA Factory、Unsloth)到推理服务器(VLLM、LiteLLM),再到部署平台(OpenLLM、SkyPilot),全面介绍各框架特点与优势。这些工具可降低显存消耗、加速训练、提供API服务,支持多种硬件与云环境,帮助开发者选择最适合的

大语言模型(Large Language Models, LLMs)推动了人工智能的革命,但将模型从预训练状态转化为可用于生产的应用,过程极为复杂。
本文系统梳理了11个关键的开源框架,覆盖了LLM全生命周期的各个环节,从微调到服务再到部署。
我们将深入探讨如Hugging Face Transformers等基础工具,DeepSpeed与Unsloth等内存优化利器,以及LLaMA Factory等综合工具包。
在部署方面,文章涵盖了高性能推理服务器(如VLLM与LiteLLM),以及简化多云环境部署的平台(如OpenLLM与SkyPilot)。
无论你需要降低显存(VRAM)消耗、利用LoRA加速训练,还是以OpenAI兼容API服务模型,本文都将帮助你梳理技术脉络,选出最适合你项目的框架。

1. Hugging Face Transformers:通用语言模型微调的主流框架

Hugging Face Transformers 提供了 Trainer API,具备丰富的训练功能,可对Hub上的任意模型进行微调。
Trainer 是专为Transformers模型设计的优化训练循环,无需手写训练代码即可快速上手。其TrainingArguments支持梯度累积、混合精度、训练指标报告与日志等多种功能。
2. DeepSpeed:微软推出的内存优化与多GPU微调框架

DeepSpeed 让ChatGPT类模型训练“一键启动”,在所有规模下实现15倍于SOTA RLHF系统的加速与显著成本降低。
DeepSpeed 是一套易用的深度学习优化软件,兼顾训练与推理的极致规模与速度。其主要特性包括:

- 支持数十亿乃至万亿参数的稠密/稀疏模型训练与推理
- 实现卓越的系统吞吐量,轻松扩展至数千GPU
- 支持资源受限GPU系统的训练/推理
- 推理延迟极低、吞吐极高
- 极致压缩,实现推理延迟与模型体积的双重降低,成本极低
3. LLaMA Factory:支持多种加速方法、适配器、分布式训练与量化的完整微调工具包

LLaMA Factory 是一款高效易用的大模型训练与微调平台。无需编写代码,即可在本地微调数百种预训练模型。其主要功能包括:
- 模型支持:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi等
- 训练器:增量预训练、多模态/指令微调、奖励模型训练、PPO、DPO、KTO、ORPO等
- 计算精度:16位全参数微调、冻结微调、LoRA微调,以及基于AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ的2/3/4/5/6/8位QLoRA微调
- 优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ、PiSSA等
- 加速算子:FlashAttention-2、Unsloth
- 推理引擎:Transformers、vLLM
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab等
4. Unsloth:专注于低显存高效微调,号称速度提升2倍、内存节省70–80%

Unsloth 让你在本地或Google Colab、Kaggle等平台轻松训练Llama 3等模型。其涵盖了模型加载、量化、训练、评估、运行、保存、导出及与Ollama、llama.cpp、vLLM等推理引擎的集成。
Unsloth的核心优势在于其深度参与主流模型的关键bug修复,与Mistral(Devstral)、Qwen3、Meta(Llama 4)、Google(Gemma 1–3)、微软(Phi-3/4)等团队直接合作,推动了准确率、稳定性与prompt处理的提升。
修复内容包括Llama 4准确率提升2%、RoPE与chat模板修正、Gemma 3未初始化权重识别等,并持续维护与更新模型模板/分词器。
5. Colossal AI:通过强大的并行训练策略与内存优化,让LLM更便宜、更快、更易用

Colossal-AI 提供了丰富的并行组件,旨在让分布式深度学习模型的编写如同在本地笔记本上一样简单。用户可通过友好工具,几行代码即可启动分布式训练与推理。
6. Axolotl:通过YAML配置文件实现后训练调整,支持全量微调与多种适配器
Axolotl 致力于简化各类AI模型的后训练流程。其主要特性包括:
- 多模型支持:支持LLaMA、Mistral、Mixtral、Pythia等多种模型,兼容HuggingFace transformers因果语言模型
- 训练方法:全量微调、LoRA、QLoRA、GPTQ、QAT、偏好微调(DPO、IPO、KTO、ORPO)、强化学习(GRPO)、多模态、奖励建模(RM/PRM)
- 易用配置:单一YAML文件贯穿数据预处理、训练、评估、量化与推理
- 性能优化:Multipacking、Flash Attention、Xformers、Flex Attention、Liger Kernel、Cut Cross Entropy、序列并行(SP)、LoRA优化、多GPU训练(FSDP1/2、DeepSpeed)、多节点训练(Torchrun、Ray)等
- 灵活数据集处理:支持本地、HuggingFace及云端(S3、Azure、GCP、OCI)数据集加载
- 云原生:官方提供Docker镜像与PyPI包,适配云平台与本地硬件
7. LiteLLM:轻量级高性能推理与服务框架,支持Flash Attention等技术
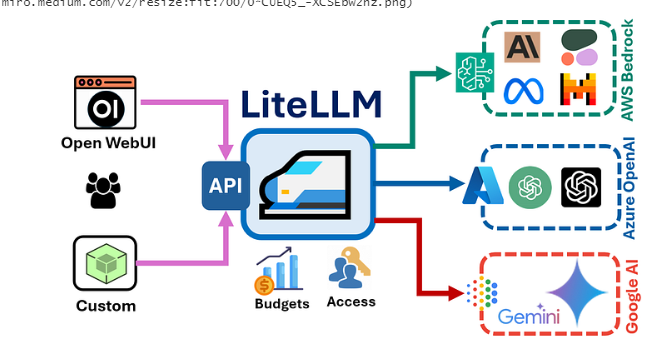
LiteLLM 是一款开源LLM网关,GitHub Star数超2.4万,被Rocket Money、Samsara、Lemonade、Adobe等公司采用。LiteLLM 提供开源Python SDK与FastAPI服务器,支持以OpenAI格式调用100+ LLM API(Bedrock、Azure、OpenAI、VertexAI、Cohere、Anthropic等)。
8. VLLM:支持轻量推理、OpenAI风格API与高级内存管理的推理引擎
vLLM 是一款高效易用的LLM推理与服务库。最初由加州大学伯克利分校Sky Computing Lab开发,现已成为学术与工业界共同推动的社区项目。
vLLM的主要优势:
- 业界领先的服务吞吐量
- 通过PagedAttention高效管理注意力KV内存
- 持续批处理请求
- CUDA/HIP图加速模型执行
- 支持GPTQ、AWQ、INT4、INT8、FP8等量化
- 集成FlashAttention、FlashInfer等优化CUDA内核
- 支持推测解码、分块预填充
vLLM的灵活性与易用性:
- 与HuggingFace模型无缝集成
- 高吞吐推理,支持并行采样、束搜索等多种解码算法
- 支持张量并行与流水线并行的分布式推理
- 支持流式输出
- OpenAI兼容API服务器
- 支持NVIDIA GPU、AMD CPU/GPU、Intel CPU、Gaudi®加速器、IBM Power CPU、TPU、AWS Trainium/Inferentia等多种硬件
- 支持前缀缓存、多LoRA
9. OpenLLM:统一API(REST/gRPC)与BentoML无缝集成的模型服务与部署平台

OpenLLM 让开发者可通过单条命令,将任意开源LLM(如Llama 3.3、Qwen2.5、Phi3等,详见支持模型列表)或自定义模型以OpenAI兼容API形式运行。
其特性包括内置聊天UI、业界领先的推理后端,以及通过Docker、Kubernetes与BentoCloud实现企业级云部署的简化流程。
10. FastChat:端到端的聊天型大模型训练与服务框架
FastChat 是一款开放平台,支持聊天型大模型的训练、服务与评测。
- FastChat 驱动了Chatbot Arena(lmarena.ai),为70+ LLM提供超千万次聊天服务
- Chatbot Arena已收集150万+人类投票,形成在线LLM Elo排行榜
FastChat核心特性包括:
- 支持SOTA模型(如Vicuna、MT-Bench)的训练与评测代码
- 分布式多模型服务系统,配备Web UI与OpenAI兼容RESTful API
11. SkyPilot:通过统一接口在AWS、GCP、Azure与Kubernetes等多云环境运行AI任务

SkyPilot 是一款开源框架,支持在任意基础设施上运行AI与批量作业。其对AI用户极为友好:
- 可在自有基础设施上快速启动计算资源
- 环境与作业即代码——简单且可移植
- 作业管理便捷:队列、运行、自动恢复
SkyPilot统一多集群、多云与多硬件:
- 单一接口管理预留GPU、Kubernetes集群及16+云平台
- 灵活调度GPU、TPU、CPU,支持自动重试
- 团队部署与资源共享
SkyPilot助力降本增效,提升GPU可用性:
- Autostop:自动清理空闲资源
- Spot实例支持:节省3–6倍成本,支持抢占自动恢复
- 智能调度:自动选择最便宜、最可用的基础设施运行作业
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
更多推荐

 26
26 0
0- 0



 已为社区贡献186条内容
已为社区贡献186条内容

所有评论(0)