Go语言中切片和数组的关系
切片是基于数组实现的,它的底层是数组,可以理解为对底层数组的抽象。在 Go 语言中,切片确实是一个结构体,它包含指向底层数组的指针、切片的长度和切片的容量这三个字段。当你将一个切片赋值给另一个切片时,它们共享相同的底层数组,因此它们的指针、长度和容量都会相同。slice占用24个字节array:指向底层数组的指针,占用8个字节len:切片的长度,占用8个字节cap:切片的容量,cap总是大于等于l
1. Go slice的底层实现原理
切片是基于数组实现的,它的底层是数组,可以理解为对底层数组的抽象。
在 Go 语言中,切片确实是一个结构体,它包含指向底层数组的指针、切片的长度和切片的容量这三个字段。当你将一个切片赋值给另一个切片时,它们共享相同的底层数组,因此它们的指针、长度和容量都会相同。
源码包中src/runtime/slice.go定义了slice的数据结构:
type slice struct {
array unsafe.Poiner
len int
cap int
}
slice占用24个字节
array:指向底层数组的指针,占用8个字节
len:切片的长度,占用8个字节
cap:切片的容量,cap总是大于等于len的,占用8个字节
slice有4种初始化方式
//初始化方式1:直接声明
var slice1 []int
//初始化方式2︰使用字面量
slice2 := []int{1,2,3,4}
//初始化方式3:使用make创建
sliceslice3 := make( []int,3,5)
//初始化方式4:从切片或数组"截取"
slcie4 := arr[1:3]
通过一个简单程序,看下slice初始化调用的底层函数
package main
import "fmt"
func main() {
slice := make( []int,0)
slice = append(slice,1)
fmt.Println(slice,len(slice), cap(slice))
}
通过go tool compile -s test.go | grep CALL得到汇编代码
0x0042 00066 (test.go:6) CALL runtime. makeslice(SB)
0x006d 00109 (test.go: 7) CALL runtime.growslice(SB)
0x00a4 00164 (test.go:8) CALL runtime.convTslice(SB)
0x00c0 00192 (test.go:8) CALL runtime. convT64(SB)
0x00d8 00216 (test.go:8) CALL runtime.convT64(SB)
0x0166 00358 ($GOROOT/src/fmt/print.go:274) CALL fmt.Fprintln(SB)
0x018000384 (test.go: 5) CALL runtime.morestack_noctxt(SB)
0x0079 00121 (<autogenerated>: 1) CALL runtime.efaceeq( SB)
0×00a0 00160 (<autogenerated> : 1) CALL runtime. morestack_noctxt(SB)
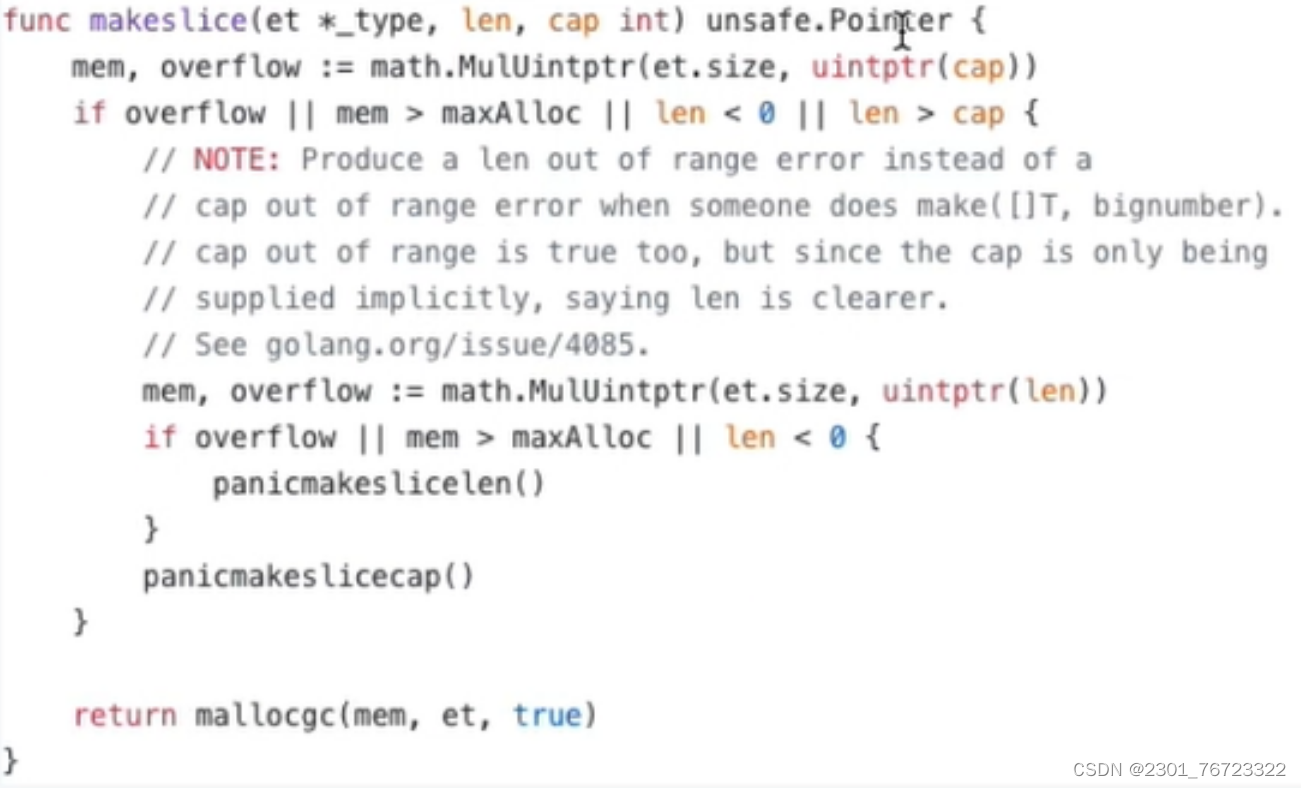
初始化slice调用的是runtime.makeslice,makeslice函数的工作主要就是计算slice所需内存大小,然后调用mallocgc进行内存的分配所需内存大小=切片中元素大小*切片的容量

2. 深拷贝和浅拷贝
深拷贝︰拷贝的是数据本身,创造一个新对象,新创建的对象与原对象不共享内存,新创建的对象在内存中开辟一个新的内存地址,新对象值修改时不会影响原对象值
实现深拷贝的方式:
1.copy(slice2, slice1)
func main() {
slice1 :=[inti1,2,3,4,5}
slice2 := make( []int,5,5)
fmt.Printf(""slice1: %v,%p" , slice1, slice1)
copy(slice2, slice1)
fmt.Printf(""slice2: %v,%p", slice2, slice2)
slice3 := make( []int,0,5)
for _, v := range slice1 {
slice3 = append(slice3, v)
}
fmt.Printf(""slice3: %v,%sp", slice3,slice3)
}
slice1: [1 2 3 4 5], 0xc0000b0030
slice2: [1 2 3 4 5], 0xc0000b0060
slice3: [1 2 34 5], 0xc0000b0090
浅拷贝∶拷贝的是数据地址,只复制指向的对象的指针,此时新对象和老对象指向的内存地址是一样的,新对象值修改时老对象也会变化
实现浅拷贝的方式:
引用类型的变量,默认赋值操作就是浅拷贝
1.slice2 := slice1
当 slice2 发生扩容时,会分配一个新的底层数组,并且 slice2 的底层数组会指向这个新的数组,而 slice1 的底层数组不受影响,仍然指向原来的数组。因此,slice1 的容量不会跟着改变。
func main() {
slice1 := []int{1,2,3,4,5}
fmt.Printf(""slice1: %v,%部pslice1, slice1)
slice2 := slice1
fmt.Printf(""slice2: %v,%部p", slice2, slice2)
}
slice1: [1 2 34 5], 0xc00001a120
slice2: [1 2 3 4 5],0xc00001a120
3. Go slice的扩容机制
扩容会发生在slice append的时候,当slice的cap不足以容纳新元素,就会进行扩容,扩容规则如下
·如果新申请容量比两倍原有容量大,那么扩容后容量大小为新申请容量
·如果原有slice长度小于1024,那么每次就扩容为原来的2倍
·如果原slice长度大于等于1024,那么每次扩容就扩为原来的1.25倍
func main() {
slice1 := []int{1,2,3}
for i := 0; i < 16; i++ {
slice1 = append(slice1,1)
fmt.Printf("addr: %p, len: %v, cap:%V
", slice1,len(slice1),cap(slice1))
}
addr: 0xc00001a120 len: 4, cap: 6
addr: 0xc00001a120,len: 5, cap: 6
addr: 0xc00001a120,len: 6, cap: 6
addr: 0xc000060060,len: 7, cap: 12
addr: 0xc000060060,len: 8, cap: 12
addr: 0xc000060060,len: 9, cap: 12
addr: 0xc000060060,len: 10, cap: 12
addr: 0xc000060060,len: 11, cap: 12
addr: 0xc000060060,len: 12, cap: 12
addr: 0xc00007c000,len: 13, cap: 24
addr: 0xc00007c000,len: 14, cap: 24
addr: 0xc00007c000,len: 15, cap: 24
addr: 0xc00007c000,len: 16, cap: 24
addr: 0xc00007c000,len: 17, cap: 24
addr: 0xc00007c000,len: 18, cap: 24
addr: 0xc00007c000,len: 19, cap: 24
4. Go slice为什么不是线程安全的
先看下线程安全的定义:
多个线程访问同一个对象时,调用这个对象的行为都可以获得正确的结果,那么这个对象就是线程安全的。
若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
再看Go语言实现线程安全常用的几种方式:
1.互斥锁
2.读写锁3.原子操作4. sync.once5.sync.atomic6. channel
slice底层结构并没有使用加锁等方式,不支持并发读写,所以并不是线程安全的,使用多个goroutine对类型为sice的变量进行操作,每次输出的值大概率都不会一样,与预期值不一致; slice在并发执行中不会报错,但是数据会丢失
/**
*切片非并发安全
*多次执行,每次得到的结果都不一样
*可以考虑使用channel本身的特性(阻塞)来实现安全的并发读写
*/
func TestsliceConcurrencySafe(t *testing.T) {
a := make([]int,0)
var wg sync.waitGroup
for i := 0; i < 10000; i++ {
wg.Add(1)
go func(i int) {
a = append(a,i)
wg.Done()
}(i)
}
wg.wait()
t.Log(len(a))
// not equal 10000
5. 示例
package main
import "fmt"
func main() {
diySlice := make([]int, 0, 2)
diySlice = append(diySlice, 8)
//观察diySlice3
diySlice3 := append(diySlice, 1)
//diySlice 变化
//查看输出切片的变化,为什么和直接输出结果不一样
fmt.Println("diySlice内容下标", diySlice[0:2])
//查看输出切片的变化
fmt.Println("diySlice 内容", diySlice)
//查看长度和容量
fmt.Printf("diySlice-->容量%d 长度%d\n", cap(diySlice), len(diySlice))
fmt.Println("diySlice3 内容", diySlice3)
fmt.Printf("diySlice3-->容量%d 长度%d\n", cap(diySlice3), len(diySlice3))
//观察diySlice2
diySlice2 := append(diySlice, 1, 2)
fmt.Println("diySlice2 内容", diySlice2)
fmt.Printf("diySlice2-->容量%d 长度%d\n", cap(diySlice2), len(diySlice2))
}
执行结果:

diySlice内容下标 [8 1] :
因为 diySlice3 := append(diySlice, 1) 这行代码属于浅拷贝,拷贝的是数据地址,只复制指向的对象的指针,这两个指针在内存中的地址是不同的,但他们指向的内存地址却是一样的,都是指向底层数组的起始地址,所以两个添加的数据都会在底层数组中存储,而diySlice[0:2]又是直接截取的底层数组里面的元素,所以结果是 [8 1]。
diySlice 内容 [8] :
因为 diySlice 和 diySlice3 指向的底层数组是同一个。所以 diySlice 和 diySlice3 两个变量存储的是两个不同的指针,占用不同的内存,同时在代码中只给diySlice添加了一个元素8,diySlice的len为1,所以diySlice中的内容只有8。
diySlice–>容量2 长度1 :
初始化diySlice时,为其分配的len 是 0, cap 是 2,而diySlice中只有一个数据,没有超出cap,不会引发扩容,所以其容量为2,长度为1。
diySlice3 内容 [8 1] :
因为diySlice中原本就有一个元素8,然后又添加了一个1,给diySlice,并把它赋值给了diySlice3,diySlice的len为2,所以diySlice3的内容有两个元素8和2。
diySlice3–>容量2 长度2 :
同理,初始化diySlice时,为其分配的len 是 0, cap 是 2,而diySlice3中有2个数据,没有超出cap,不会引发扩容,所以其容量为2,长度为2。
diySlice2 内容 [8 1 2] :
diySlice中原本就有一个元素,然后又添加了两个元素,并赋值给了diySlice2,diySlice2的len为3,所以其内容为 [8 1 2]。
diySlice2–>容量4 长度3 :
diySlice中原本就有一个元素,然后又添加了两个元素,超过了cap的值2,所以引发了扩容机制,因为原有diySlice长度为2小于1024,那么就扩容为原来的2倍,cap变为4,又因为有三个元素,所以len等于3。但此时diySlice2指向的底层数组发生了变化,指向了cap为4的底层数组,而diySlice和diySlice3仍然指向cap为2的底层数组,因为切片发生扩容时,会分别一个新的底层数组。
若有错误,请各位大佬多多指出,万分感谢!

欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)