

将json文件转化成yolov8训练格式
json
适用于现代 C++ 的 JSON。
项目地址:https://gitcode.com/gh_mirrors/js/json
·
前期条件:已经使用labelme做好json文件。可以看以下博客。
转化过程:1、将json文件转化成txt文件
2、将文件分成训练集、验证集、测试集
以下代码将json文件转化成txt文件
import json
import os
import argparse
from tqdm import tqdm
def convert_label_json(json_dir, save_dir, classes):
json_paths = os.listdir(json_dir)
classes = classes.split(',')
for json_path in tqdm(json_paths):
# for json_path in json_paths:
path = os.path.join(json_dir, json_path)
try:
with open(path, 'r', encoding='utf-8') as load_f:
json_dict = json.loads(load_f.read())
except json.JSONDecodeError:
print(f"Error decoding file {path}. Skipping.")
continue
# with open(path, 'r', encoding='utf-8') as load_f:
# json_dict = json.load(load_f)
h, w = json_dict['imageHeight'], json_dict['imageWidth']
# save txt path
txt_path = os.path.join(save_dir, json_path.replace('json', 'txt'))
txt_file = open(txt_path, 'w')
for shape_dict in json_dict['shapes']:
label = shape_dict['label']
label_index = classes.index(label)
points = shape_dict['points']
points_nor_list = []
for point in points:
points_nor_list.append(point[0] / w)
points_nor_list.append(point[1] / h)
points_nor_list = list(map(lambda x: str(x), points_nor_list))
points_nor_str = ' '.join(points_nor_list)
label_str = str(label_index) + ' ' + points_nor_str + '\n'
txt_file.writelines(label_str)
if __name__ == "__main__":
"""
python json2txt_nomalize.py --json-dir my_datasets/color_rings/jsons --save-dir my_datasets/color_rings/txts --classes "duck"
"""
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1json/',
help='json path dir')
parser.add_argument('--save-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1txt/',
help='txt save dir')
parser.add_argument('--classes', type=str, default='eggbox', help='classes')
args = parser.parse_args()
json_dir = args.json_dir
save_dir = args.save_dir
classes = args.classes
convert_label_json(json_dir, save_dir, classes)
以下路径是自己json文件的路径
parser = argparse.ArgumentParser(description='json convert to txt params')
parser.add_argument('--json-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1json/',
help='json path dir')
parser.add_argument('--save-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1txt/',
help='txt save dir')
parser.add_argument('--classes', type=str, default='eggbox', help='classes')
--json-dir:json的文件夹;--save-dir:生成txt的文件夹;--classes:类别
生成文件夹如下:
json
适用于现代 C++ 的 JSON。
项目地址:https://gitcode.com/gh_mirrors/js/json
以下代码将文件分成训练集、验证集、测试集
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os
import argparse
# 检查文件夹是否存在
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
def main(image_dir, txt_dir, save_dir):
# 创建文件夹
mkdir(save_dir)
images_dir = os.path.join(save_dir, 'images')
labels_dir = os.path.join(save_dir, 'labels')
img_train_path = os.path.join(images_dir, 'train')
img_test_path = os.path.join(images_dir, 'test')
img_val_path = os.path.join(images_dir, 'val')
label_train_path = os.path.join(labels_dir, 'train')
label_test_path = os.path.join(labels_dir, 'test')
label_val_path = os.path.join(labels_dir, 'val')
mkdir(images_dir);
mkdir(labels_dir);
mkdir(img_train_path);
mkdir(img_test_path);
mkdir(img_val_path);
mkdir(label_train_path);
mkdir(label_test_path);
mkdir(label_val_path);
# 数据集划分比例,训练集75%,验证集15%,测试集15%,按需修改
train_percent = 0.85
val_percent = 0.14
test_percent = 0.01
total_txt = os.listdir(txt_dir)
num_txt = len(total_txt)
list_all_txt = range(num_txt) # 范围 range(0, num)
num_train = int(num_txt * train_percent)
num_val = int(num_txt * val_percent)
num_test = num_txt - num_train - num_val
train = random.sample(list_all_txt, num_train)
# 在全部数据集中取出train
val_test = [i for i in list_all_txt if not i in train]
# 再从val_test取出num_val个元素,val_test剩下的元素就是test
val = random.sample(val_test, num_val)
print("训练集数目:{}, 验证集数目:{},测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))
for i in list_all_txt:
name = total_txt[i][:-4]
srcImage = os.path.join(image_dir, name + '.jpg')
srcLabel = os.path.join(txt_dir, name + '.txt')
if i in train:
dst_train_Image = os.path.join(img_train_path, name + '.jpg')
dst_train_Label = os.path.join(label_train_path, name + '.txt')
shutil.copyfile(srcImage, dst_train_Image)
shutil.copyfile(srcLabel, dst_train_Label)
elif i in val:
dst_val_Image = os.path.join(img_val_path, name + '.jpg')
dst_val_Label = os.path.join(label_val_path, name + '.txt')
shutil.copyfile(srcImage, dst_val_Image)
shutil.copyfile(srcLabel, dst_val_Label)
else:
dst_test_Image = os.path.join(img_test_path, name + '.jpg')
dst_test_Label = os.path.join(label_test_path, name + '.txt')
shutil.copyfile(srcImage, dst_test_Image)
shutil.copyfile(srcLabel, dst_test_Label)
if __name__ == '__main__':
"""
python split_datasets.py --image-dir my_datasets/color_rings/imgs --txt-dir my_datasets/color_rings/txts --save-dir my_datasets/color_rings/train_data
"""
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggboximage1/',
help='image path dir')
parser.add_argument('--txt-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1txt/',
help='txt path dir')
parser.add_argument('--save-dir', default='H:/labelImg-master/labelImg-master/datas/data/eggbox1split', type=str,
help='save dir')
args = parser.parse_args()
image_dir = args.image_dir
txt_dir = args.txt_dir
save_dir = args.save_dir
main(image_dir, txt_dir, save_dir)
改变以下路径
parser = argparse.ArgumentParser(description='split datasets to train,val,test params')
parser.add_argument('--image-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggboximage1/',
help='image path dir')
parser.add_argument('--txt-dir', type=str, default='H:/labelImg-master/labelImg-master/datas/data/eggbox1txt/',
help='txt path dir')
parser.add_argument('--save-dir', default='H:/labelImg-master/labelImg-master/datas/data/eggbox1split', type=str,
help='save dir')
--image-dir:图像文件夹内容如下所示(有图像就可)
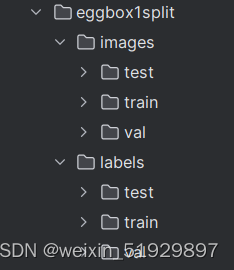
生成如下文件:
阅读全文
AI总结
适用于现代 C++ 的 JSON。
最近提交(Master分支:6 个月前 )
51a77f1d
3 天前
756ca22e
3 天前

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容
相关推荐
查看更多
json
适用于现代 C++ 的 JSON。
json
An efficient JSON decoder
json
pretty-printed JSON response middleware

所有评论(0)