
[大模型]ollama本地部署自然语言大模型
大模型已经发布很久,网络上的大模型形形色色,现在已然是群英荟萃,那么,如何在本地运行一个大模型?本文采用ollama,简单运行本地大模型,不需要写代码。测试机器:i5 840016G内存1060 6G安装ollama安装,下载,运行模型。Chatbox作为桌面程序,用来更方便的调用大模型。经测试,gemma:2b模型可流畅运行。
一键AI生成摘要,助你高效阅读
问答
·
大模型已经发布很久,网络上的大模型形形色色,现在已然是群英荟萃,那么,如何在本地运行一个大模型?
本文采用ollama,简单运行本地大模型,不需要写代码。
测试机器:
i5 8400
16G内存
1060 6G
安装ollama安装,下载,运行模型。Chatbox作为桌面程序,用来更方便的调用大模型。
经测试,gemma:2b模型可流畅运行
ollama
下载地址
githup
https://github.com/ollama/ollama/releases
百度云
https://pan.baidu.com/s/1kETzxfpJEDm0LovVRf4AFg?pwd=anan
模型默认安装位置
C:\Users\用户名\.ollama
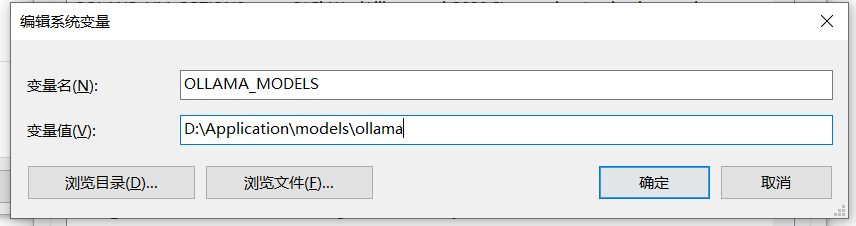
修改模型默认安装位置
模型的默认下载路径为
C:\Users\<username>\.ollama\models
如果不想保存在C盘,需要修改,择需要添加环境变量,并重启ollama
OLLAMA_MODELS
修改完毕后需要重启ollama,在任务栏右键退出。之后再window中双击运行

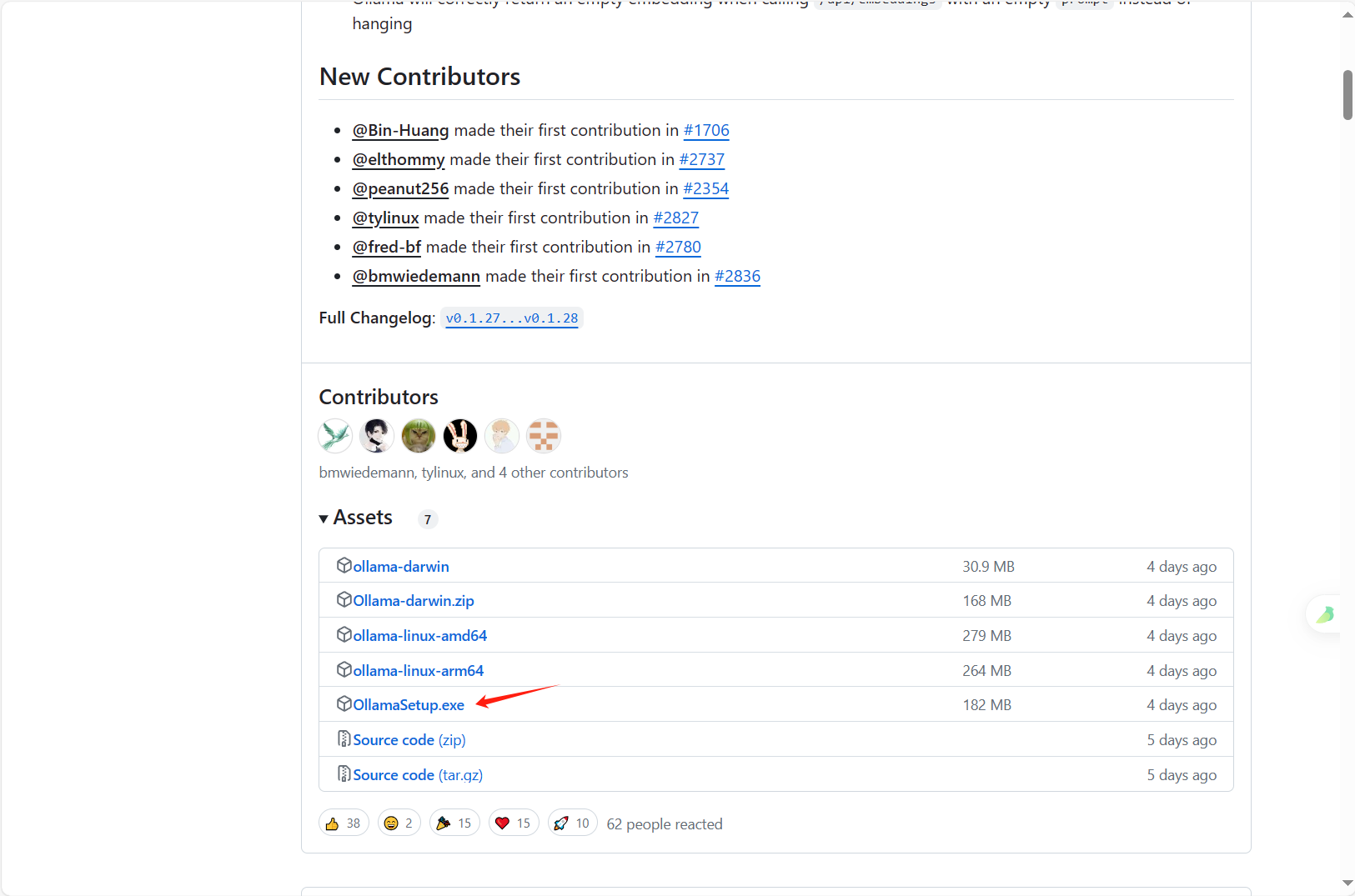
最后可以看到在我们的设置页面中出现了一个新的文件夹,这就表示设置成功了
可下载模型
执行以上命令后,Ollama 将开始初始化,并自动从 Ollama 模型库中拉取并加载所选模型。一旦准备就绪,就可以向它发送指令,它会利用所选模型来进行理解和回应。
记得将modelname名称换成要运行的模型名称,常用的有:
| 模型 | 参数 | 大小 | 安装命令 | 发布组织 |
|---|---|---|---|---|
| Llama 2 | 7B | 3.8GB | ollama run llama2 | Meta |
| Code Llama | 7B | 3.8GB | ollama run codellama | Meta |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b | Meta |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b | Meta |
| Mistral | 7B | 4.1GB | ollama run mistral | Mistral AI |
| mixtral | 8x7b | 26GB | ollama run mixtral:8x7b | Mistral AI |
| Phi-2 | 2.7B | 1.7GB | ollama run phi | Microsoft Research |
| LLaVA | 7B | 4.5GB | ollama run llava | Microsoft Research |
| Columbia University | ||||
| Wisconsin | ||||
| Gemma 2B | 2B | 1.4GB | ollama run gemma:2b | |
| Gemma 7B | 7B | 4.8GB | ollama run gemma:7b | |
| Qwen 4B | 4B | 2.3GB | ollama run qwen:4b | Alibaba |
| Qwen 7B | 7B | 4.5GB | ollama run qwen:7b | Alibaba |
| Qwen 14B | 14B | 8.2GB | ollama run qwen:14b | Alibaba |
运行 7B 至少需要 8GB 内存,运行 13B 至少需要 16GB 内存。
相关命令
# 查看本地已经下载的模型
ollama list
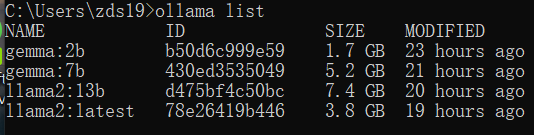
# 下载模型 例如gemma:2b
ollama run gemma:2b
下载完毕后

可通过命令行输出与之对话

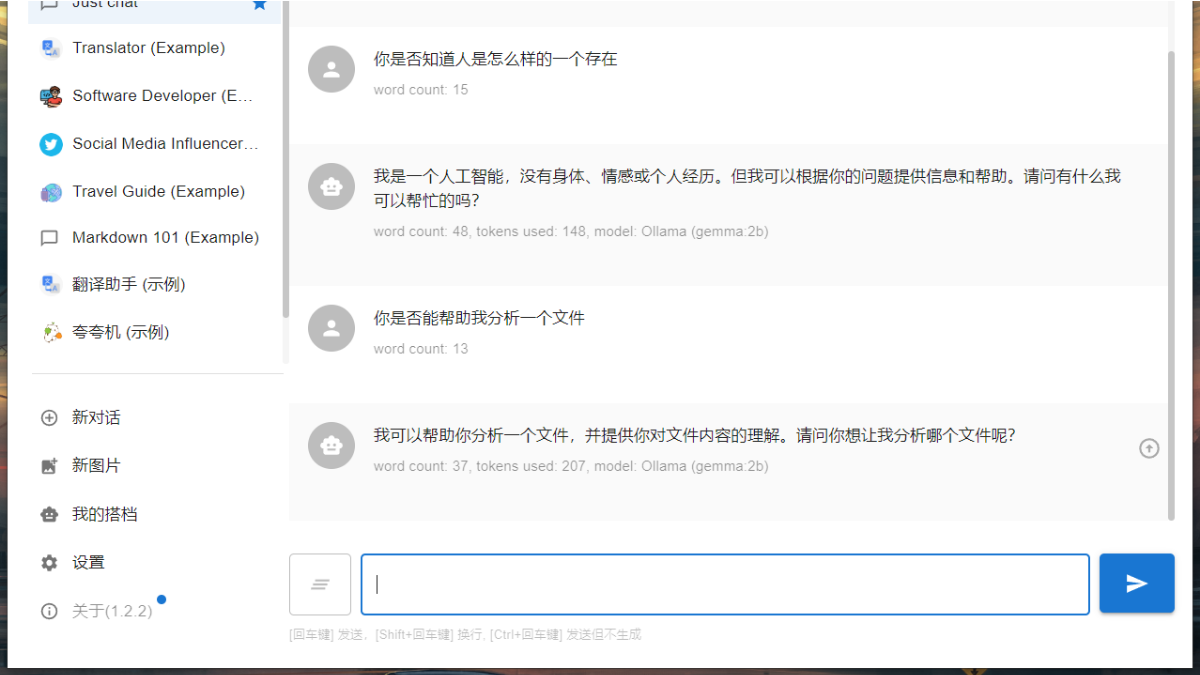
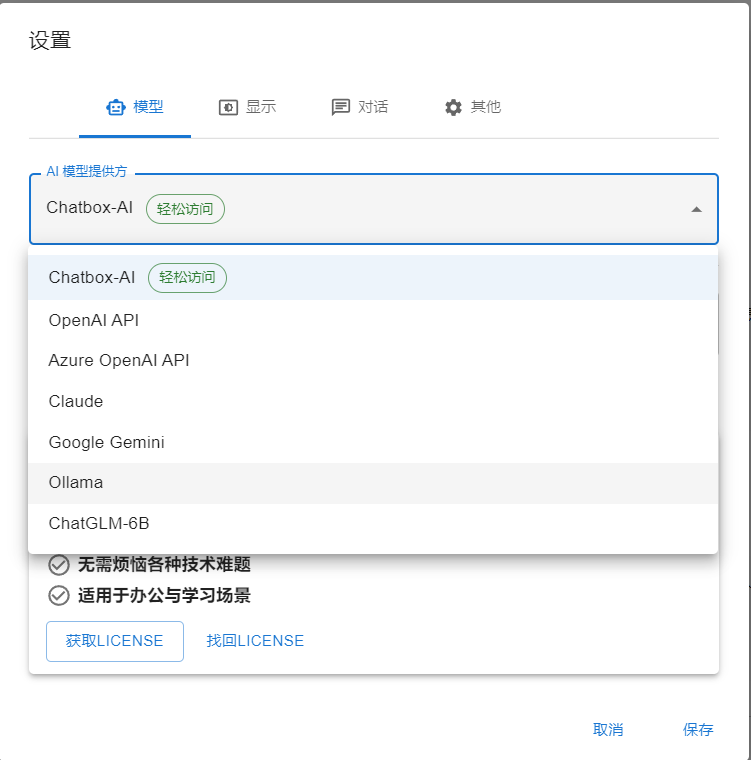
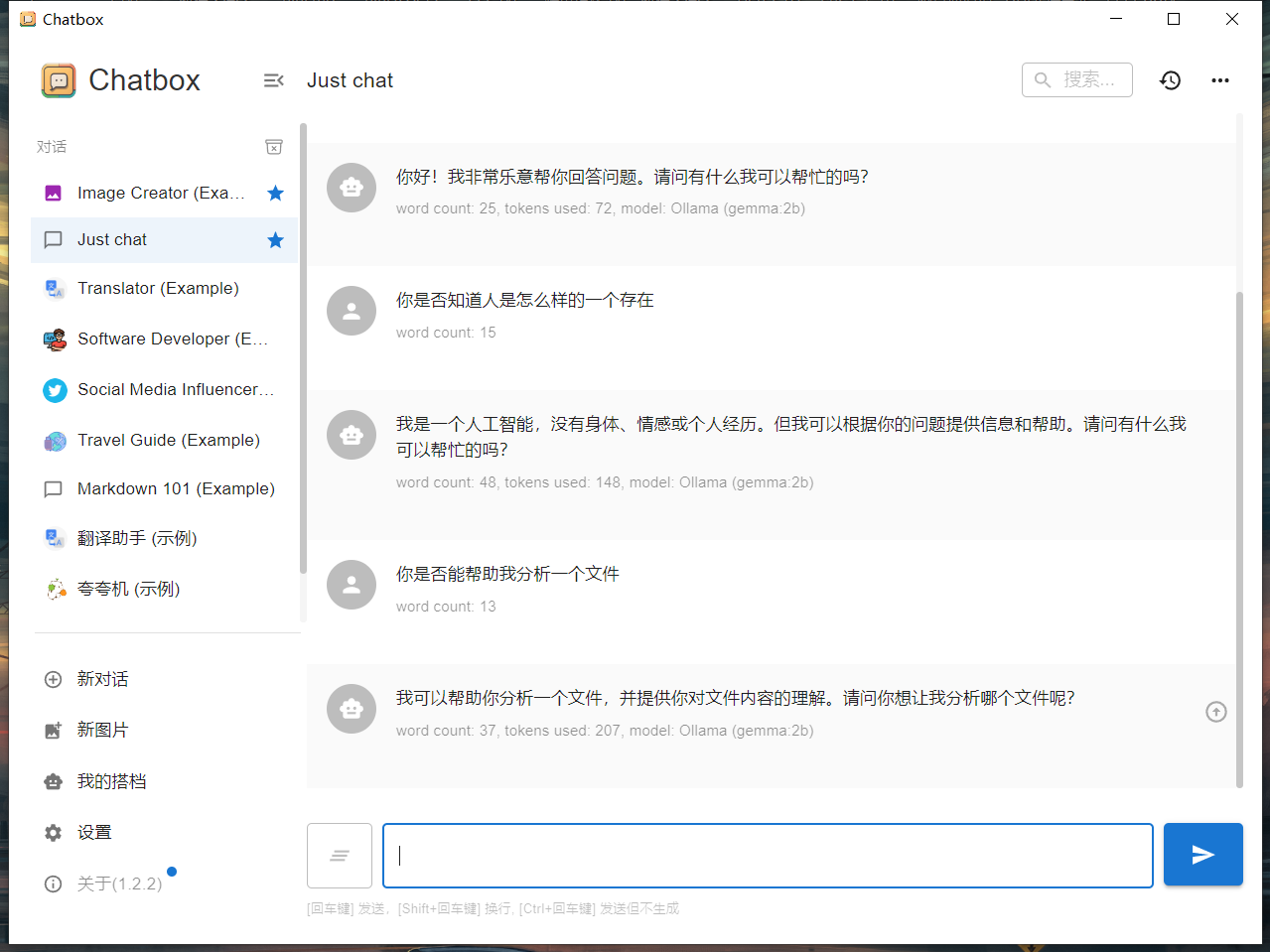
Chatbox客户端
Chatbox 支持 ollama,可以使用图形化的对话方式。
下载地址
githup
https://github.com/Bin-Huang/chatbox/releases
百度云
https://pan.baidu.com/s/11mUtHDAN-nvfk0L_3ZE26Q?pwd=anan
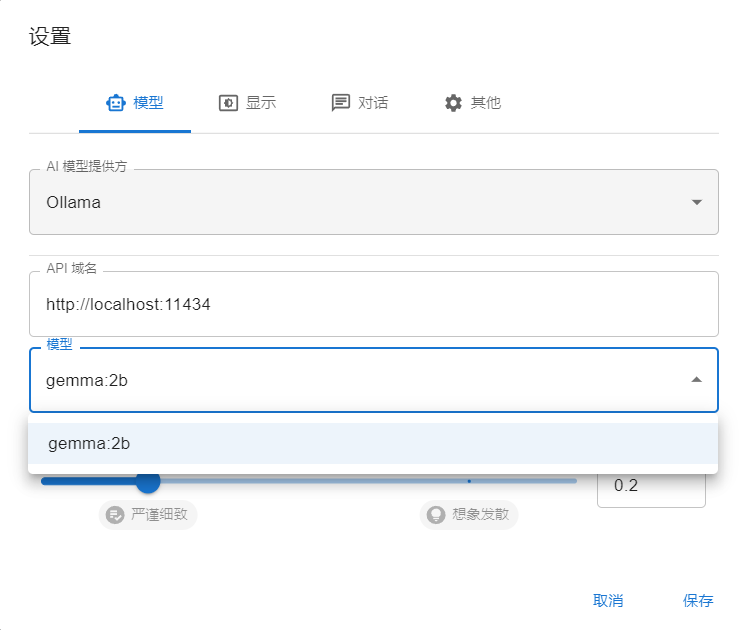
设置ollama模型并运行

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)