

yolov8的指标
检测精度检测速度前传耗时每秒帧数 FPS(Frames Per Sencond)P-R curve浮点运算量(FLOPS)AP、mAP。
指标总结
| 检测精度 | 检测速度 |
|---|---|
| Precision,Recall,F1 score | 前传耗时 |
| IoU(Intersection over Union) | 每秒帧数 FPS(Frames Per Sencond) |
| P-R curve | 浮点运算量(FLOPS) |
| AP、mAP,Cls,Loc,Both, Dupe,Bkg,Miss |
检测速度
1.前传耗时(ms)
从输入一张图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)
2.每秒帧数FPS (Frames Per Second)
每秒钟能处理的图像数量
3.浮点运算量(FLOPS)
处理一-张图像所需要的浮点运算数量,跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速度
这里主要的指标为FPS,(在模型轻量化中十分重要)
FPS的计算一共有两种方法
第一种,是只计算推理时间
第二种,是处理时间加上推理时间

此图为yolov8运行后的输出结果(如何在yolov8中添加FPS,后续更新)
检测精度
1.混淆矩阵
混淆矩阵是对分类问题预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,显示了分类模型进行预测时会对哪一部分产生混淆。通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了,把一个类错认成了另一个。
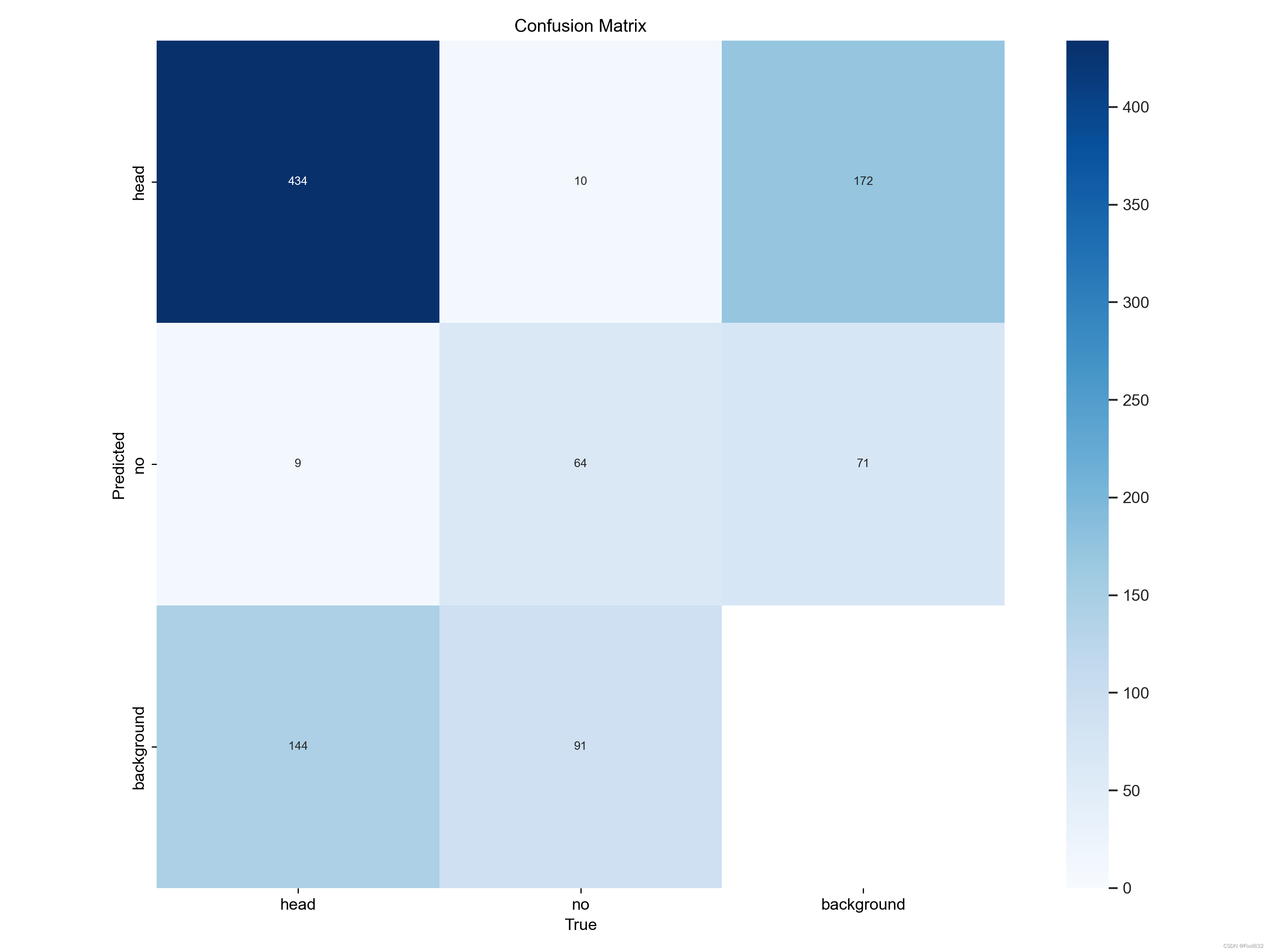
主要看中间的4个格子

TP(True Positive): 将正类预测为正类数 即正确预测,真实为0,预测也为0
FN (False Negative):将正类预测为负类 即错误预测,真实为0,预测为1
FP(False Positive):将负类预测为正类数 即错误预测, 真实为1,预测为0
TN (True Negative):将负类预测为负类数,即正确预测,真实为1,预测也为1
2.精确率和召回率
精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重
3.F1曲线
F1曲线,被定义为查准率和召回率的调和平均数
一些多分类问题的竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,其中1是最好,0是最差。
一般来说,置信度阈值(该样本被判定为某一类的概率阈值)较低的时候,很多置信度低的样本被认为是真,召回率高,精确率低;置信度阈值较高的时候,置信度高的样本才能被认为是真,类别检测的越准确,即精准率较大(只有confidence很大,才被判断是某一类别),所以前后两头的F1分数比较少。

4.P_curve.png(单一类准确率)
即置信度阈值 - 准确率曲线图
当判定概率超过置信度阈值时,各个类别识别的准确率。当置信度越大时,类别检测越准确,但是这样就有可能漏掉一些判定概率较低的真实样本。
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。可以看到,当置信度越大的时候,类别检测的越准确。这也很好理解,只有confidence很大,才被判断是某一类别。但也很好想到,这样的话,会漏检一些置信度低的类别。

5.PR_curve.png(精确率和召回率的关系图)
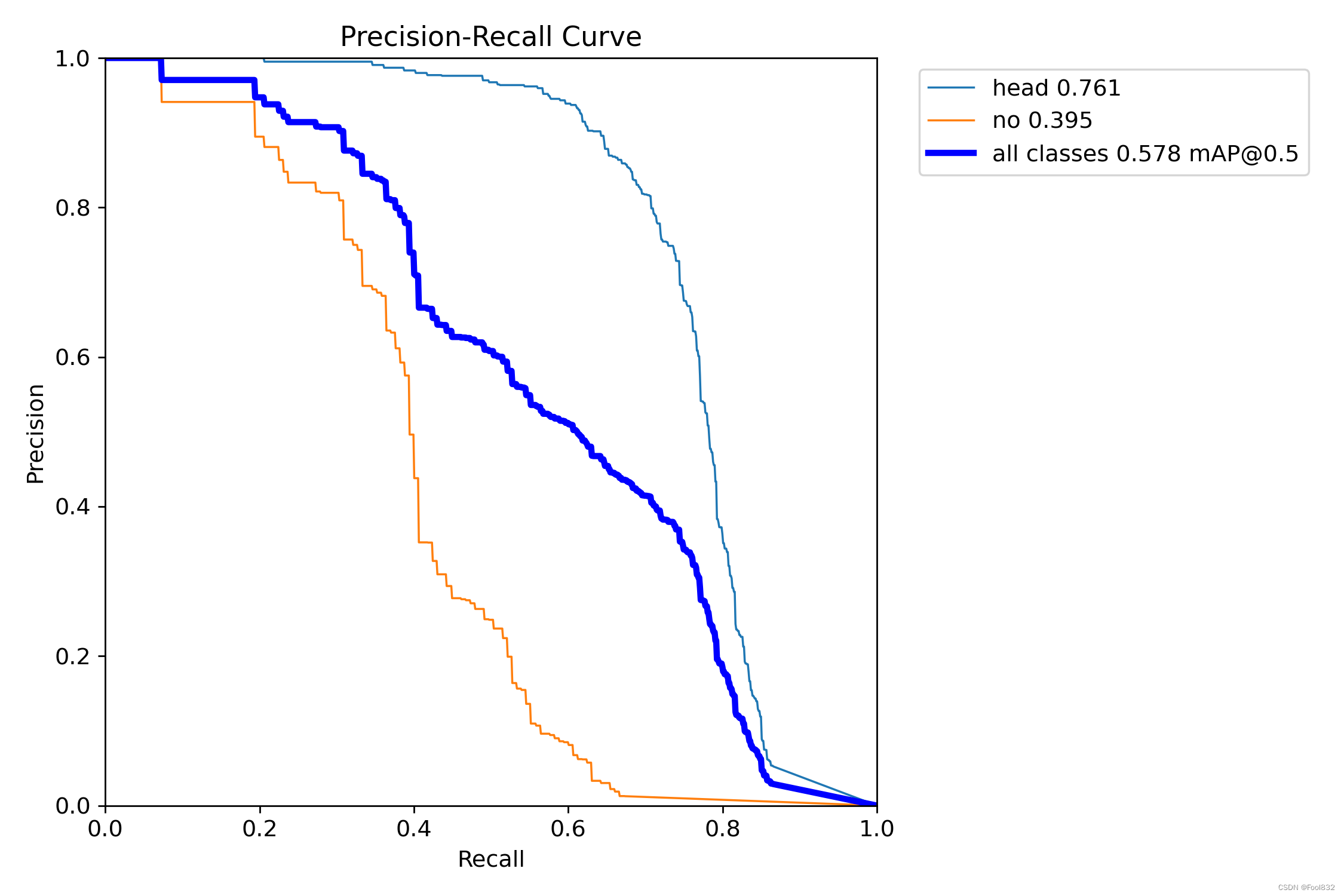
PR曲线体现精确率和召回率的关系。
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
Precision和Recall往往是一对矛盾的性能度量指标;及一个的值越高另一个就低一点;
提高Precision < == > 提高二分类器预测正例门槛 < == > 使得二分类器预测的正例尽可能是真实正例;
提高Recall < == > 降低二分类器预测正例门槛 < == >使得二分类器尽可能将真实的正例挑选
6.mAP50,与mAP50-95
mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。(是比较重要的指标)
因此我们希望:在准确率很高的前提下,尽可能的检测到全部的类别。因此希望我们的曲线接近(1,1),即希望mAP曲线的面积尽可能接近1。
mAP50:是预测框与标注框有50%的重合就认为预测成功的前提下,的均值平均精度
mAP50-95:是预测框与标注框有50%-95%的重合(每次增加5%),就认为预测成功的前提下,所有值平均后的均值平均精度
就是:
在程序中的结果如图:

在yolov8中保存的最好的配置文件(best,py)就是根据,P,R,MAP50,MAP50-95四个指标的比例进行保存,因此我们可以修改程序来保存侧重不同指标的最好配置文件,方法可参考
7.Cls,Loc,Both,Dupe,Bkg,Miss
mAP有几个缺点,其中最重要的是它的复杂性。它被定义为在一个特定的交并比(IoU)阈值处检测到的精确召回率曲线下的面积,并具有一个正确分类的标签(GT),平均于所有类别,因为错误类型变得相互交织,很难衡量每种错误类型对mAP的影响有多大,因此出现了一类新的指标,分别为以下六种
1.类错误:对于错误分类的,IoUmax ≥ tf(即定位正确但分类错误)。
2.定位错误:对于正确分类的,tb ≤ IoUmax ≤ tf(即分类正确但定位错误)。
3.分类和定位都错误:对于错误分类的,tb ≤ IoUmax ≤ tf (即分类错误并且定位错误)。
4.重复检测错误:分类正确且GTIoUmax ≥ tf ,但另一个较高得分的检测已经匹配了该GT(即,如果不是有较高得分的检测,则是正确的)。
5.背景错误:对所有的GT都IoUmax ≤ tb(将背景检测为前景)。
6.未检测到GT错误:未被分类或定位错误覆盖的所有未被检测到的ground truth(fn)。

在程序中的显示结果如下:(如何使yolov8中显示如下指标以后跟新)

未完,以后更新
参考文章链接:https://blog.csdn.net/weixin_45277161/article/details/131046636
https://blog.csdn.net/Q1u1NG/article/details/109814528

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)