

语义分割新SOTA:80.5mIoU+62.8FPS! 华科与美团联合提出单分支推理分割架构SCTNet,已开源!
本文首发于最新的实时语义分割方法通常。然而,。为了消除这一困境,。SCTNet在保留轻量级单分支CNN高效性的同时,还拥有语义分支的丰富语义表示。考虑到transformer提取长距离上下文的卓越能力,SCTNet将transformer作为仅用于训练的语义分支。。在推理过程中,只需要部署单分支CNN。我们在Cityscapes,ADE20K和COCO-Stuff-10K上进行了广泛的实验,结果表
本文首发于AIWalker,谢谢关注~
最新的实时语义分割方法通常采用额外的语义分支来追求丰富的长距离上下文。然而,额外的分支会带来不必要的计算开销,并减缓推理速度。为了消除这一困境,我们提出了SCTNet,一种带有transformer语义信息的单分支CNN用于实时分割。
https://arxiv.org/abs/2312.17071
https://github.com/xzz777/SCTNet
SCTNet在保留轻量级单分支CNN高效性的同时,还拥有语义分支的丰富语义表示。考虑到transformer提取长距离上下文的卓越能力,SCTNet将transformer作为仅用于训练的语义分支。借助于提出的transformer类CNN块CFBlock和语义信息对齐模块,SCTNet可以在训练中从transformer分支捕获丰富的语义信息。在推理过程中,只需要部署单分支CNN。我们在Cityscapes,ADE20K和COCO-Stuff-10K上进行了广泛的实验,结果表明,我们的方法达到了新的最先进水平。

本文贡献主要包含以下三点:
- 我们提出了一种新的单支实时分割网络SCTNet。通过学习从Transformer到CNN的语义信息对齐来提取丰富的语义信息,SCTNet在保持轻量级单支CNN快速推理速度的同时,具有Transformer的高准确性。
- 为了缓解CNN特征和Transformer特征之间的语义鸿沟,我们设计了CFBlock(ConvFormer Block),它可以仅使用卷积操作捕获长距离上下文。此外,我们提出了SIAM(语义信息对齐模块),以更有效地对齐特征。
- 在Cityscapes、ADE20K和COCO-Stuff-10K上的大量实验结果表明,所提的SCTNet在实时语义分割方面优于现有的最新方法. SCTNet为提高实时语义切分的速度和性能提供了一个新的视角
本文方案

降低计算成本的同时,获得丰富的语义信息,我们将现在流行的两个分支架构拆解为:
- 一个CNN分支进行推断;
- 一个Transformer分支用于训练阶段语义对齐。
Backbone 为了提高推理速度,SCTNet采用了典型的分层CNN骨干。 SCTNet的Stem模块由两个3×3卷积构成; 前两个阶段是由堆叠的残积模块组成的;后两个阶段则是由所提CFBlock构成。 CFBlock采用了几个精心设计的卷积操作来执行类似于Transformer块的远程上下文捕获功能。
Decoder Head 解码头由DAPPM与分割头构成,为进一步丰富上下文信息,作者在Stage4后面添加了DAPPM。然后,作者将S2和S4输出进行拼接并送入分割头。
Training Phase 众所周知,Transformer在捕获全局语义上下文方面表现出色。 另一方面,CNN已被证明比变换器更适合于对分层局部信息进行建模。 受Transformer和CNN优点的启发,我们探索配备一个具有这两种优点的实时分割网络。 我们提出了一个单分支CNN,它学习将其特征与强大的Transformer的特征对齐。 这种特征对齐使单分支CNN能够提取丰富的全局上下文和详细的空间信息。 具体而言,SCTNet采用了一个仅作用在训练阶段的Transformer作为语义分支来提取强大的全局语义上下文,语义信息对齐模块监督卷积分支以对齐来自Transformer的高质量全局上下文。
Inference Phase 为了避免两个分支的巨大计算成本,在推理阶段只部署了CNN分支。 利用transformer对齐的语义信息,单分支CNN可以生成准确的分割结果,而无需额外的语义或昂贵的密集融合。 更具体地说,输入图像被送入到单分支层次卷积主干中,解码器头拾取主干中的特征并进行简单的拼接进行像素分类.
本文实验
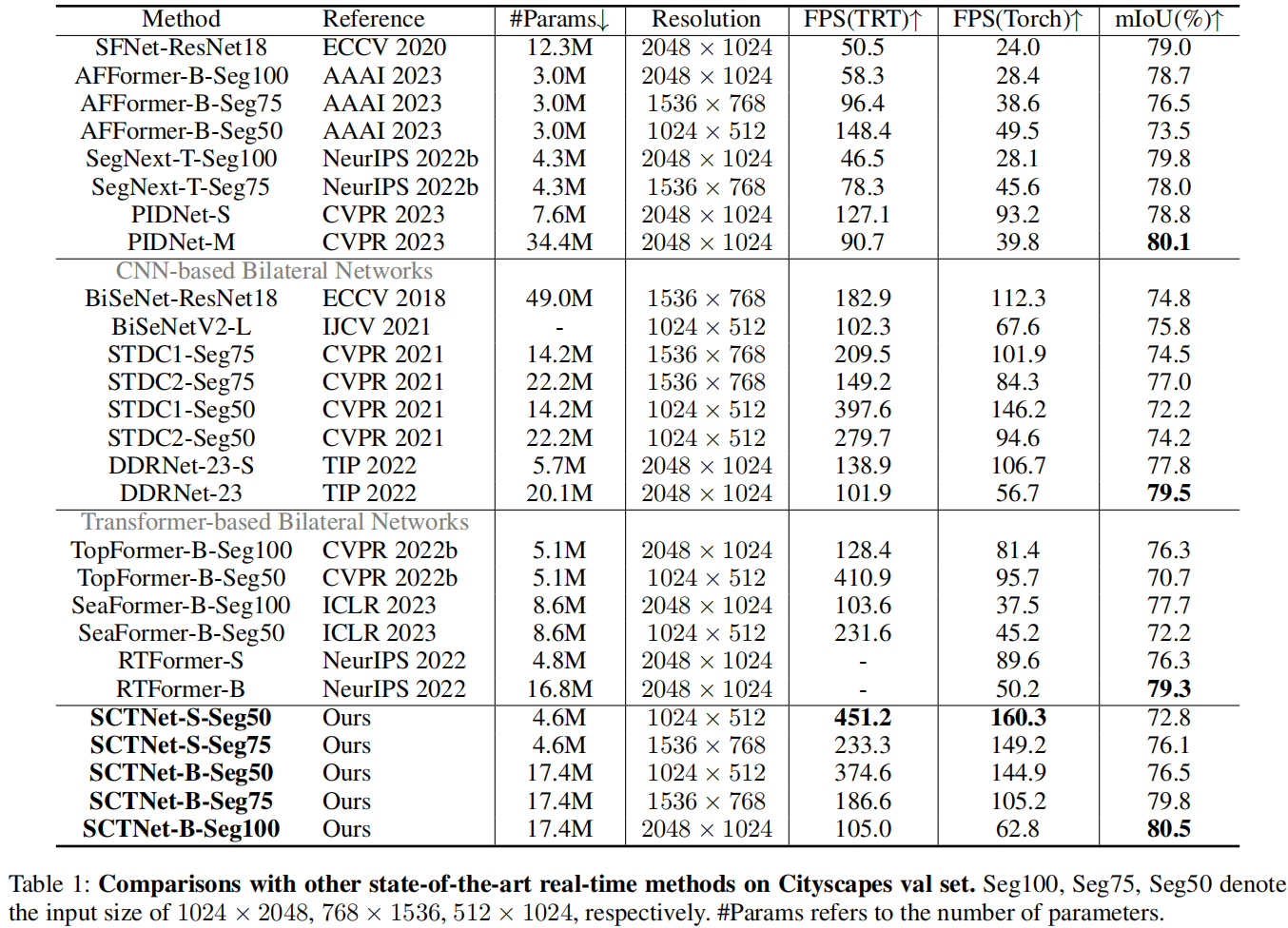

上图与表为Cityscapes语义分割上不同方案的性能对比,从中可以看到:
- 所提SCTNet以大幅优势优于其他实时分割方案,取得了最佳的速度-精度均衡;
- 所提SCTNet-B-Seg100去的了80.5%mIoU且速度达62.8FPS,达成实时分割新SOTA;
- 所提SCTNet-B-Seg75取得了79.8%mIoU,比RTFormer-B与DDRnet-23精度更高,同时速度快两倍;
- 在所有输入分辨率下,所提SCTNet-B均比其他方案指标更优;此外,SCTNet-S同样取得了比STDC2、RTFormer-S、SeaFormer-B、TopFormer-B更优的性能均衡。

上表为ADE20K与COCO-Stuff-10K两个数据集上不同分割方案的性能对比,很明显:所提SCTNet同样取得了更优的速度-精度均衡。
推荐阅读

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)