

LLM大模型入门-基于 InternLM 和 LangChain 搭建知识库
开源词向量模型 Sentence Transformer:是一种基于Transformer架构的开源词向量模型,专为生成句子级别的嵌入(embeddings)而设计。这个模型是在BERT、RoBERTa、DistilBERT等预训练的Transformer模型的基础上进一步发展而来的。Sentence Transformers在许多自然语言处理(NLP)任务中非常有效,尤其是在那些需要理解句子整体
引言
基于B站LLM大模型学习课程进行学习:https://www.bilibili.com/video/BV1sT4y1p71V/?vd_source=d5e90f8fa067b4804697b319c7cc88e4
并完成作业中的复现要求。
大模型开发范式
基座模型就是RAG中的天花板,不需要额外算力;
Finetune训练新的数据集,专业性强,成本高。
“大模型范式”(Large Model Paradigm)是指利用大规模的神经网络模型来处理各种复杂的人工智能任务。在这个范畴下,RAG(Retrieval-Augmented Generation)和Finetuning是两种常见的方法。
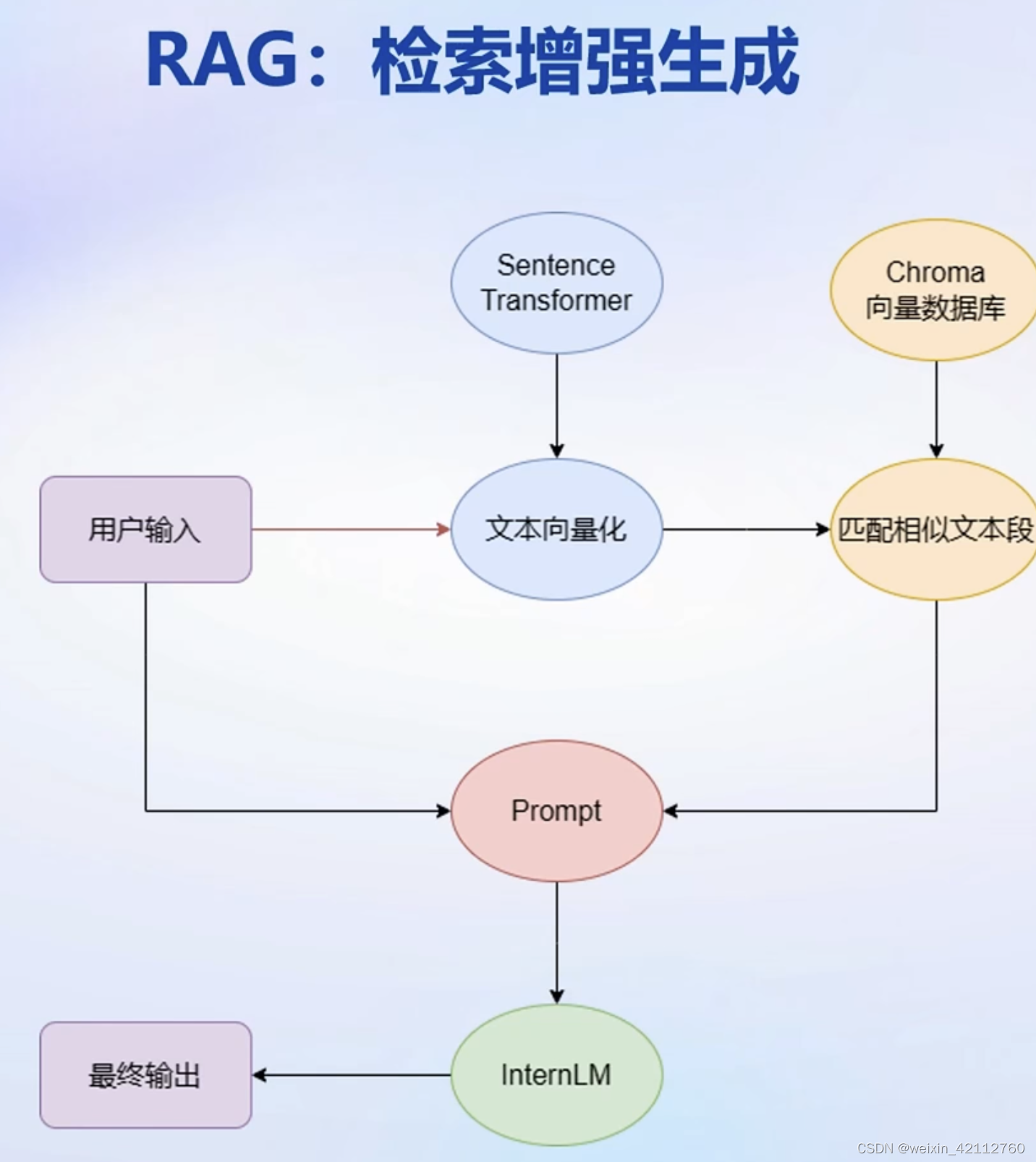
RAG(Retrieval-Augmented Generation)是一种结合了检索(Retrieval)和生成(Generation)的方法。它通常用于自然语言处理任务,尤其是在问答系统和聊天机器人中。
- 检索阶段:
- 在接收到一个查询(例如,一个问题)时,RAG首先执行一个检索步骤。它从一个大型的文档集合中检索相关信息。这个集合可以是维基百科、专业数据库或任何其他大型知识库。
生成阶段: - 然后,RAG使用检索到的信息来增强生成模型的回答。生成模型(如GPT系列)基于检索到的上下文生成回答。
- RAG通过结合检索到的外部信息和生成模型的能力,能够生成更准确、信息丰富的回答。
Finetuning是一种常见的机器学习技术,尤其用于神经网络。在大模型范式中,Finetuning通常指的是在一个大型、预训练好的模型(如GPT-3、BERT等)基础上进行额外训练以适应特定任务的过程。
- 预训练模型:使用大量的通用数据预训练一个模型,使其学习广泛的语言模式和知识。
- 微调过程:针对特定任务(例如情感分析、文本分类、特定领域的问答等)使用较小的、特定的数据集对模型进行微调。
Finetuning使得模型能够在保持原有广泛知识的同时,更好地适应特定的任务或数据集。
总结
RAG适合于需要结合广泛信息源进行回答的任务,例如开放域的问答。
Finetuning适用于各种特定任务,尤其是在有限定数据集的情况下,可以显著提高模型的性能。
LangChain 是快速开发RAG的开源框架。
LangChain 简介

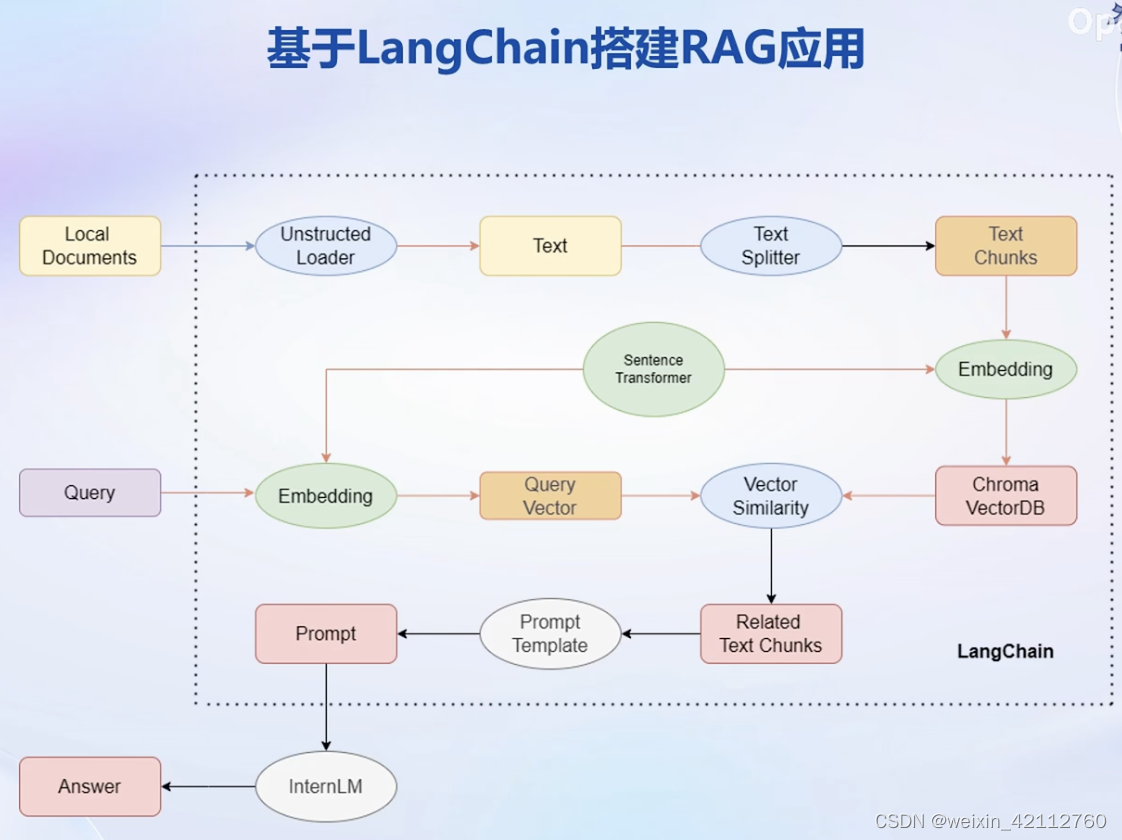
构建向量数据库


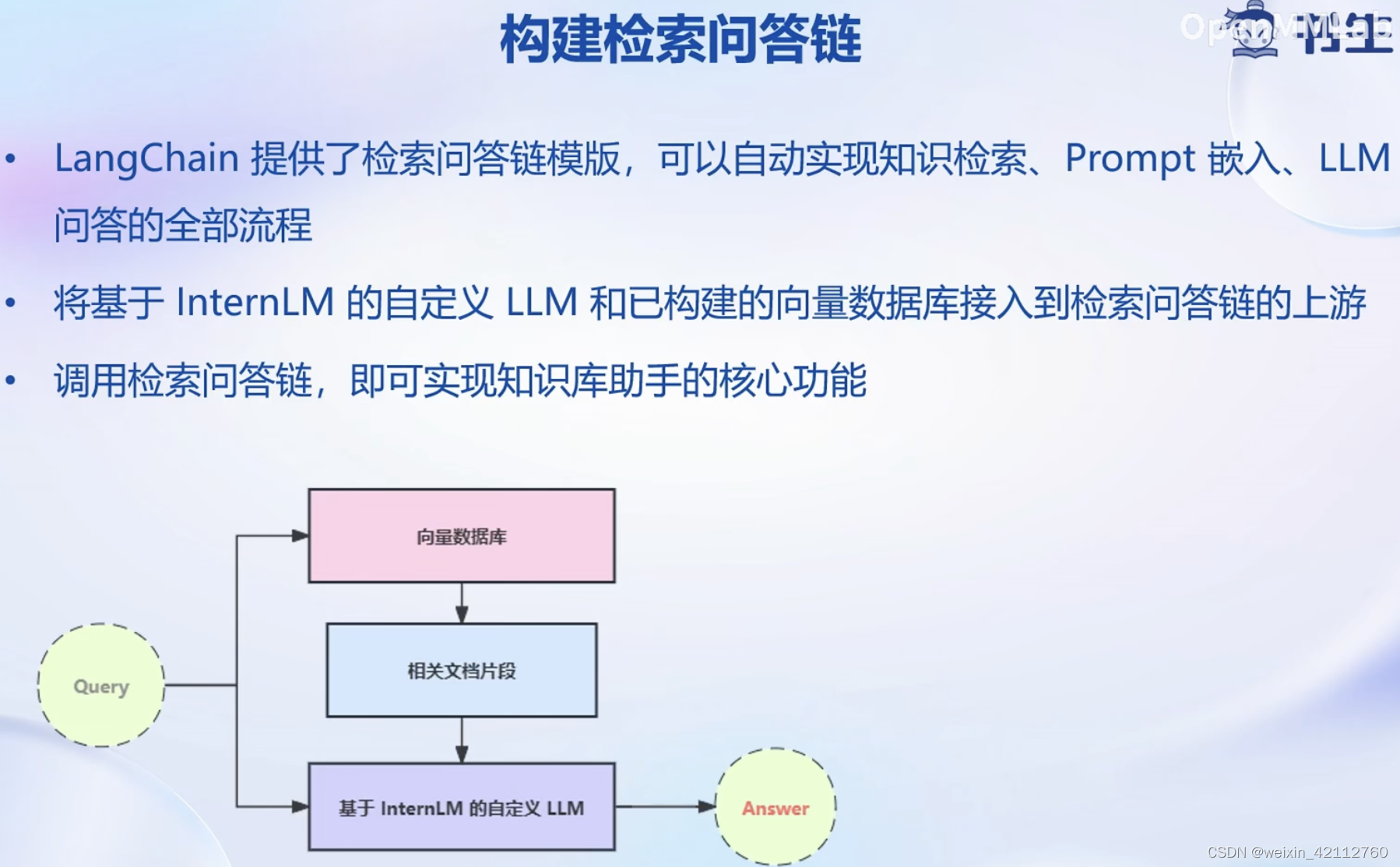
搭建知识库助手
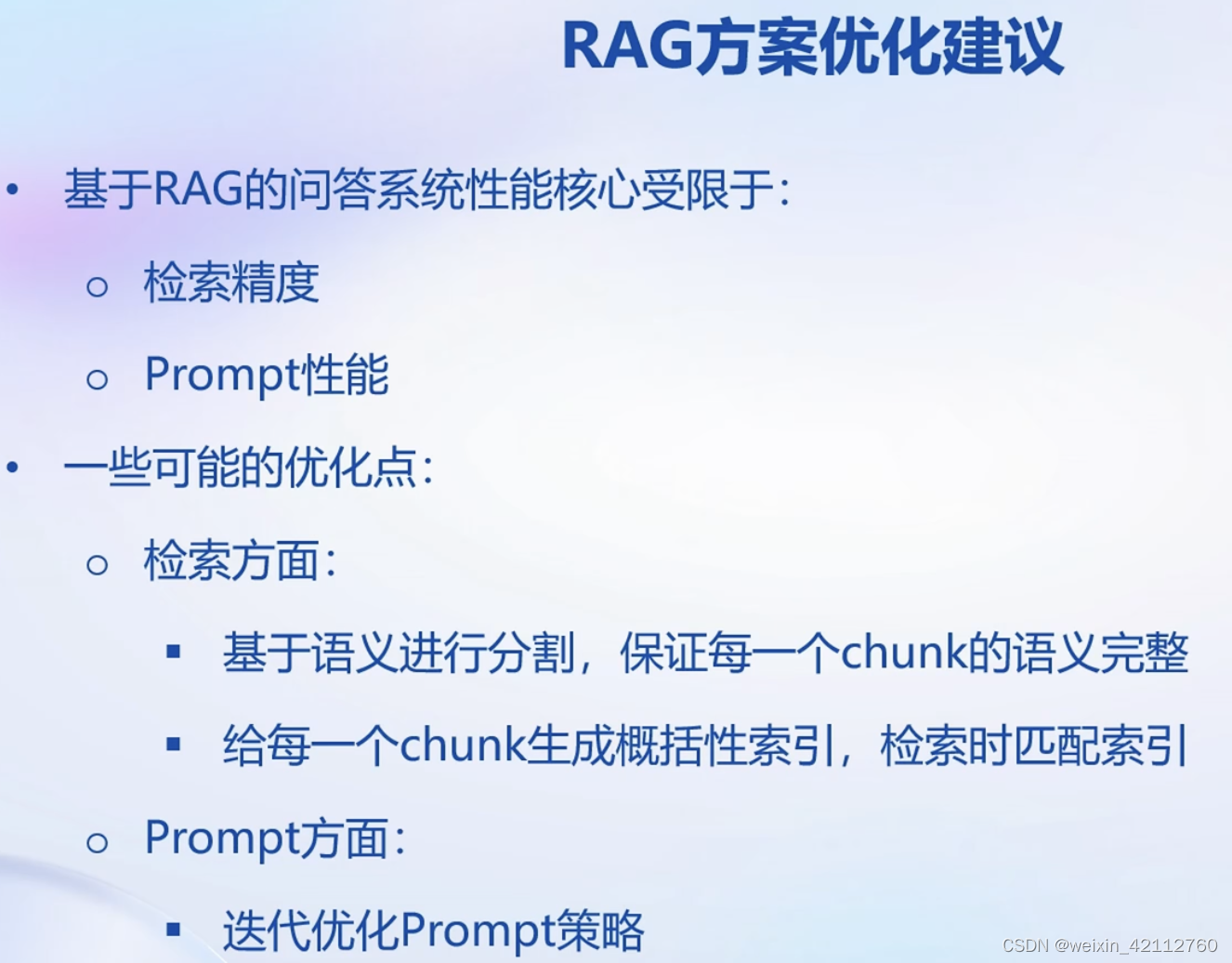
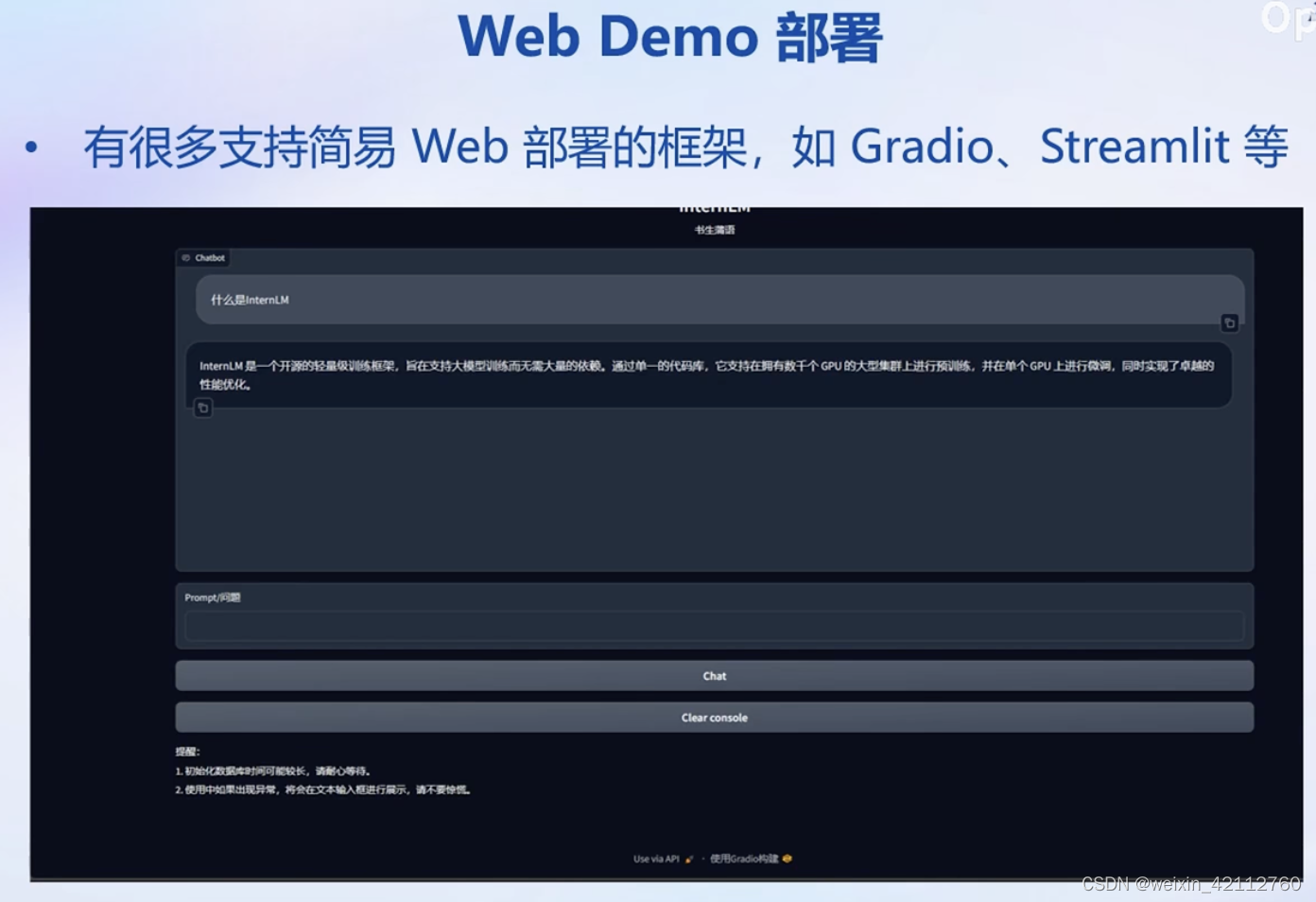
Web Demo 部署
实践
开源词向量模型 Sentence Transformer:是一种基于Transformer架构的开源词向量模型,专为生成句子级别的嵌入(embeddings)而设计。这个模型是在BERT、RoBERTa、DistilBERT等预训练的Transformer模型的基础上进一步发展而来的。Sentence Transformers在许多自然语言处理(NLP)任务中非常有效,尤其是在那些需要理解句子整体意义的应用中,如语义文本相似度评估、聚类、文本检索等。
特点
- 高效的句子嵌入:相比于直接使用BERT等模型处理句子,Sentence Transformers更高效。它通过一次性处理整个句子来生成嵌入,而不是单独处理句子中的每个词。
- 适用于各种NLP任务:可用于文本相似度计算、信息检索、聚类等多种任务。
- 简化的使用流程:直接提供句子级别的嵌入,无需进行复杂的后处理。
- 基于Siamese和Triplet网络:通过这些网络结构,模型在训练时学会将语义相似的句子映射到嵌入空间中的接近点。
训练和使用 - 基于预训练Transformer模型: Sentence Transformers首先利用像BERT这样的预训练模型作为其基础。
- 使用对比学习方法: 在训练过程中,模型通过比较不同句子的嵌入来学习如何生成有效的句子级嵌入。
- 多种可用模型: 提供多种不同的预训练模型,适用于不同的语言和任务。
- 易于集成和扩展: 可以容易地集成到现有的NLP处理流程中,同时也支持自定义和扩展以适应特定需求。
应用场景 - 语义搜索: 在大量文本中快速找到语义上相关的内容。
- 文本聚类: 将文本自动分组到不同的类别。
- 相似度评估: 比较两个句子的语义相似度。
NLTK,全称Natural Language Toolkit,是一个开源的Python库,用于编程和处理自然语言数据。它提供了简单易用的接口,支持大量的语言计算任务,包括词性标注、语义推理、文本分类等。
NLTK库包含了大量的预制和预处理的文本资源,例如词库、语料库、词汇表、关联数据等,以及一系列计算自然语言处理所需的统计度量和模型。同时,NLTK也提供了图形演示、教程和用户指南。
NLTK的主要功能包括:
- 语料库:NLTK为用户提供了多种语言的语料库,例如WordNet、Treebank等,并能够自定义语料库。
- 分词:提供了数种文本分词工具,有效地将文本数据分解为词、句子等单元。
- 词性标注:NLTK可以将文本分词后的单词标注上相应的词性,例如名词、形容词、动词等。
- 命名实体识别:提供工具,打标识各种类型的命名实体,例如人名、地名、组织名等。
- 语法树建设:用于句子的句法分析,提供了构建和演示语法树的工具。
- 文本分类:提供简单易用的工具用于训练文本分类器,支持多种分类算法。
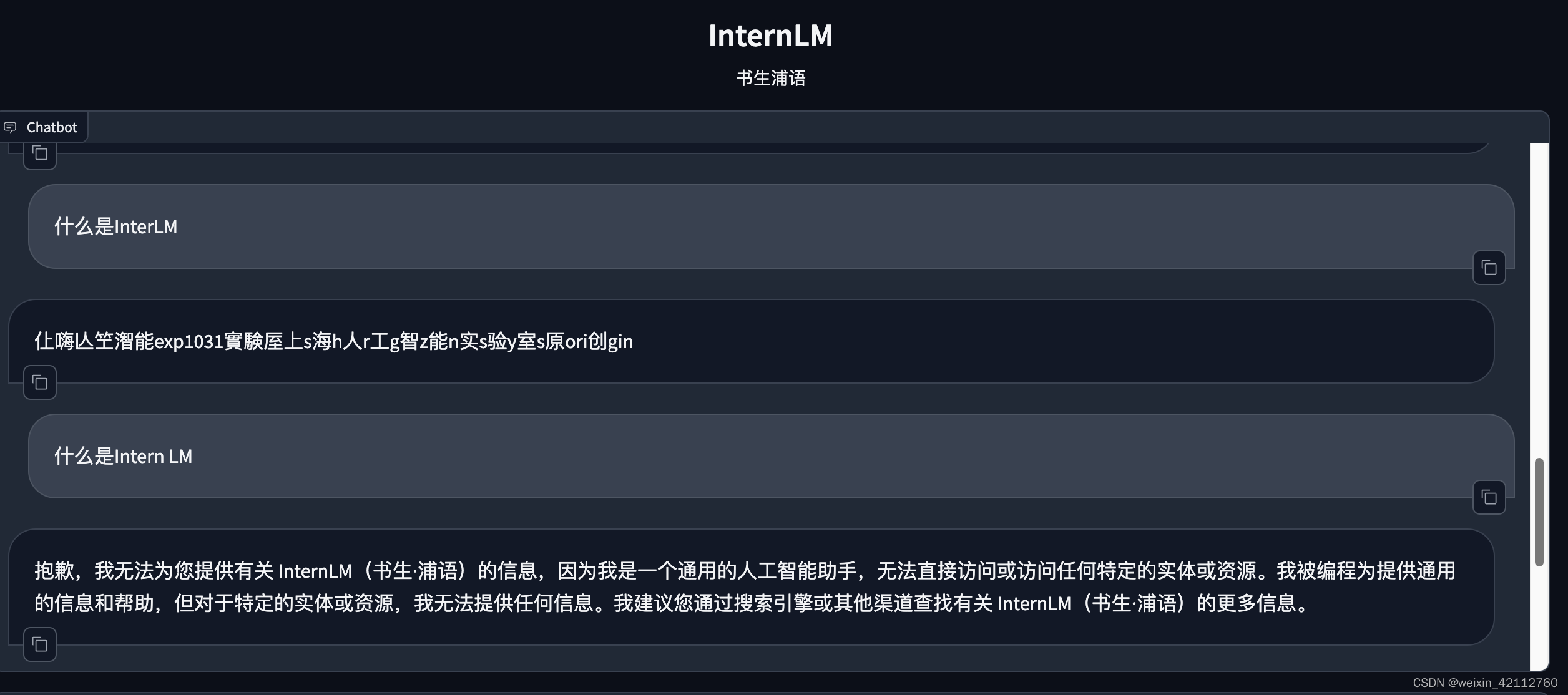
总体操作下来没有什么困难的地方,但是发现InternLM拼写错误会乱码。

尝试了多次提问,后面输出稳定,没有再乱码了。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)