一文读懂Langchain:ChatGLM3和ChatGPT的Agent调用分析
首先下载上面给出的github项目并安装环境,然后想想要测试什么问题。请问下面这个字符串的长度的三次幂是几:XXX,理想情况下,Agent加持的大模型会分析出需要调用获取字符串长度和计算三次幂这两个工具,然后连续调用它们得到正确的结果。所以第一步就是要把这两个工具定义好,在这个项目里,只要在Tool文件夹下定义好xxx.py和xxx.yaml这两个文件,xxx这个工具就算可以使用了,我们对这两个工
文章目录
关于Agent
Agent的中文名叫做代理或者智能体,和一般的对话模式相比,进入Agent模式的大模型,具有更多的自我意识和独立思考能力,同时它在回答问题时除了可以利用训练时内化到无穷参数中的知识,还可以利用不同的工具,甚至是将多种工具组合起来以解决特定的问题。
Agent的实现其实不难,其主要技术思路是通过提示工程在常规的思考问题之上再构建一层反思,引导大模型思考和拆解输入问题,并自主判断每个子问题需要完成的动作,也就是要调用的工具以及该工具的输入,在获取到每个动作的返回结果后,对结果进行分析和反思,在全流程结束后对结果进行整合。
现在已经有很多模型和框架支持Agent的实现,例如Langchain和ChatGPT的经典组合,最近发布的一些国产开源模型,如Qwen和ChatGLM3,也添加了对于Agent的支持。下面我就以ChatGLM3给出的langchain调用代码为例,测试一下ChatGPT和ChatGLM3的Agent能力,顺便读懂Langchain的整套逻辑,看它能不能完成一些较为复杂的任务。
基于ChatGPT的Agent调用与分析
工具定义
首先下载上面给出的github项目并安装环境,然后想想要测试什么问题。我打算问一个这样的问题:请问下面这个字符串的长度的三次幂是几:XXX,理想情况下,Agent加持的大模型会分析出需要调用获取字符串长度和计算三次幂这两个工具,然后连续调用它们得到正确的结果。
所以第一步就是要把这两个工具定义好,在这个项目里,只要在Tool文件夹下定义好xxx.py和xxx.yaml这两个文件,xxx这个工具就算可以使用了,我们对这两个工具的定义如下,注意这些工具的输入和输出都得是字符串。(yaml文件是给ChatGLM3用的,所以只是测ChatGPT的话不用定义也可以)
Get_len.py
import abc
import math
from typing import Any
from langchain.tools import BaseTool
class Get_len(BaseTool, abc.ABC):
name = "Get_len"
description = "输入一个str类型的字符串,返回结果为这个字符串的长度"
def __init__(self):
super().__init__()
async def _arun(self, *args: Any, **kwargs: Any) -> Any:
# 用例中没有用到 arun 不予具体实现
pass
def _run(self, para: str) -> str:
return str(len(para))
if __name__ == "__main__":
get_len = Get_len()
result = get_len.run("1234567")
print(result)
Get_len.yaml
name: Get_len
description: 输入一个str类型的字符串,返回结果为这个字符串的长度
parameters:
type: object
properties:
sentence:
type: string
description: The sentence to be counted
required:
- sentence
Get_mi.py
import abc
import math
from typing import Any
from langchain.tools import BaseTool
class Get_mi(BaseTool, abc.ABC):
name = "Get_mi"
description = "输入一个str类型的数字,返回结果为这个数字的三次幂"
def __init__(self):
super().__init__()
async def _arun(self, *args: Any, **kwargs: Any) -> Any:
# 用例中没有用到 arun 不予具体实现
pass
def _run(self, number: str) -> str:
"""输入一个str类型的数字,返回结果为这个数字的三次幂"""
number = int(number)
return str(number*number*number)
if __name__ == "__main__":
mi_tool = Get_mi()
result = mi_tool.run("3")
print(result)
Get_len.yaml
name: Get_mi
description: 输入一个str类型的数字,返回结果为这个数字的三次幂
parameters:
type: object
properties:
number:
type: str
description: The number to be calculated
required:
- number
模型定义
已知ChatGPT的api_key和base_url,回答时用到的llm定义如下:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(api_key='xxx', base_url='xxx/v1', model_name = "gpt-3.5-turbo-0301")
如果你写成下面这种:
from langchain.llms.openai import OpenAI
llm = OpenAI(api_key='xxx', base_url='xxx/v1', model_name = "gpt-3.5-turbo-0301")
就会喜提报错:
openai.lib._old_api.APIRemovedInV1:
You tried to access openai.ChatCompletion, but this is no longer supported in openai>=1.0.0 - see the README at https://github.com/openai/openai-python for the API.
You can run `openai migrate` to automatically upgrade your codebase to use the 1.0.0 interface.
Alternatively, you can pin your installation to the old version, e.g. `pip install openai==0.28`
A detailed migration guide is available here: https://github.com/openai/openai-python/discussions/742
如果你地址里少写了v1,写成下面这种:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(api_key='xxx', base_url='xxx', model_name = "gpt-3.5-turbo-0301")
就会喜提另一种看不懂的报错:
File "/home/df1500/anaconda3/envs/langchain1120/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/home/df1500/anaconda3/envs/langchain1120/lib/python3.10/runpy.py", line 196, in _run_module_as_main (Current frame)
return _run_code(code, main_globals, None,
AttributeError: 'str' object has no attribute 'dict'
工具导入
在main函数里面写:
from Tool.Get_len import Get_len
from Tool.Get_mi import Get_mi
run_tool([Get_mi(), Get_len()], llm, [
"请问下面这个字符串的长度的三次幂是几:你是谁?",
"请问下面这个字符串的长度的三次幂是几:你是谁你是谁你是谁你是谁?",
]),
然后看一下run_tool的实现,其实逻辑很简单,就是用传进来的tool和llm来初始化一个agent,然后执行prompt:
def run_tool(tools, llm, prompt_chain: List[str]):
loaded_tolls = []
for tool in tools:
if isinstance(tool, str):
loaded_tolls.append(load_tools([tool], llm=llm)[0])
else:
loaded_tolls.append(tool)
agent = initialize_agent(
loaded_tolls, llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
for prompt in prompt_chain:
agent.run(prompt)
Agent类型
在上面的代码中,初始化agent时需要指定agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION这个参数,不同AgentType对于结果的影响很大,下面汇总一下不同的AgentType。
首先介绍一些常见的关键词:
- ReAct:由单词“Reason”和“Act”组合而成,前者对应于推理,即大模型的通用文本逻辑判断能力,或者说是对问题进行思考和拆解的能力;后者对应于行动,即具备专业知识的特定领域精确回答能力,或者说是调用外部工具的能力。ReAct顾名思义就是把思考和行动相结合,通过二者的依次迭代执行完成任务。
- Zero-shot:零样本,或者说是无记忆。在运行时,只考虑与当前代理的一次交互,不保留对话历史。
- Conversational:引入了对话历史,因为有记忆了,所以需要初始化代理时引入memory 参数。其一个缺点是可能无法执行复杂的Tool调用任务。
- Chat:常规情况下以OpenAI方式初始化LLM,此类Agent可以以ChatOpenAI方式初始化模型。前者是更通用的接口,用于与不同类型的语言模型进行交互,可以与各种LLM模型集成。ChatOpenAI接口是对其的高级封装,更专注于对话式交互。
| AgentType | 介绍 |
|---|---|
| SELF_ASK_WITH_SEARCH | 提问时与搜索引擎相连接,把问题拆解后依次搜索并返回结果,对结果进行推理和总结,工具需要被限定命名为Intermediate Answer |
| OPENAI_FUNCTIONS | OpenAI模型在训练时被微调过,以识别并调用一些预设的函数,不同工具调用一次 |
| OPENAI_MULTI_FUNCTIONS | 一个工具调用多次,并且除了推理过程,会输出一大堆包括模型参数在内的乱七八糟的东西 |
| REACT_DOCSTORE | 调用 LangChain内部已经实现好的docstore 信息检索方法,需要实现并传递Search(文章级检索)和Lookup(文章内检索)这两个工具 |
| CONVERSATIONAL_REACT_DESCRIPTION | 保留了聊天记录历史,会有这么一句Thought: Do I need to use a tool? |
| CHAT_CONVERSATIONAL_REACT_DESCRIPTION | 允许使用聊天模型也就是创建对话代理时使用ChatOpenAI类型,中间步骤会把采取的action输出为json格式 |
| ZERO_SHOT_REACT_DESCRIPTION | 最通用的Agent类型,可传递任意数量的灵活定义的工具及其描述。回答时大模型遵循 Question(用户问题)、Thought(拆解问题)、Action(匹配动作)、Action Input(解析输入)、Observation(获取输出)的流程。重复该过程直到达到 Final Answer(最终答案)结束 |
| CHAT_ZERO_SHOT_REACT_DESCRIPTION | 同样,区别体现在可以使用ChatOpenAI方式初始化模型 |
| STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION | 一般工具的输入都是单字符串,这类Agent可允许定义多参数的工具,并根据工具的参数定义创建结构化的输入,适用于更复杂的工具使用 |
Agent测试
对基于REACT的几种Agent做了测试,结果如下,可以看出在我们的这个设定下,ZERO_SHOT_REACT_DESCRIPTION是唯一的,伟大的,好用的
- CONVERSATIONAL_REACT_DESCRIPTION
看到CONVERSATIONAL,就知道要引入memory了,代码修改如下,注意一定要把return_messages设为TRUE,不然会报
Error: variable chat_history should be a list of base messages, got这种奇怪的错误:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent = initialize_agent(
loaded_tolls, llm,
agent=AgentType.CHAT_CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True,
handle_parsing_errors=True
)
以自问自答形式思考,解析结果失败
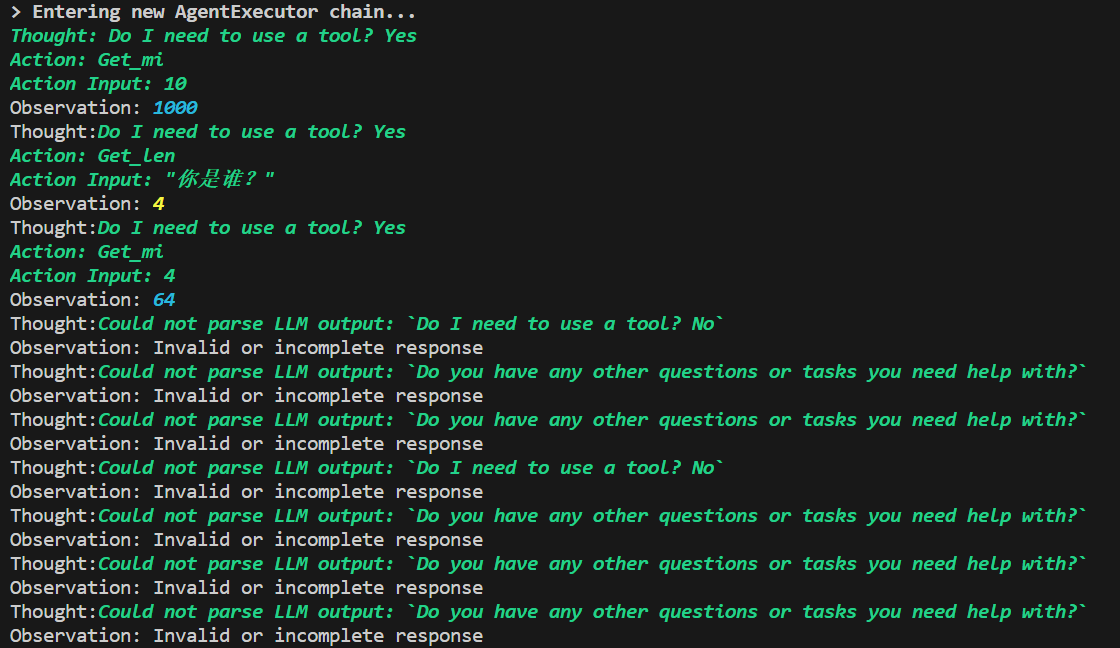
- CHAT_CONVERSATIONAL_REACT_DESCRIPTION
以JSON形式思考,但只能调用一次工具,回答得不对
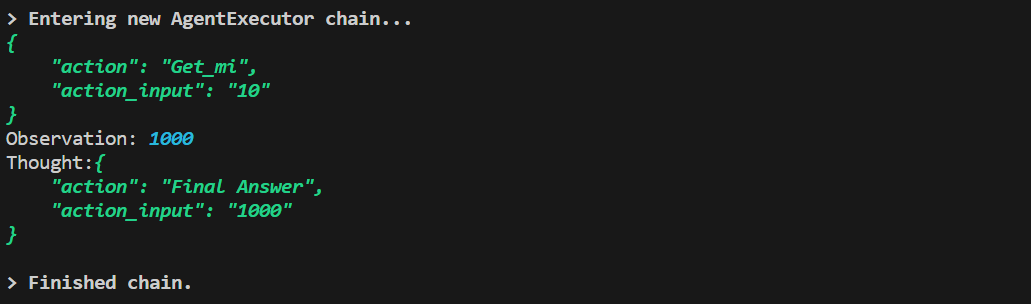
- ZERO_SHOT_REACT_DESCRIPTION
以思维链形式思考,非常完美的回答
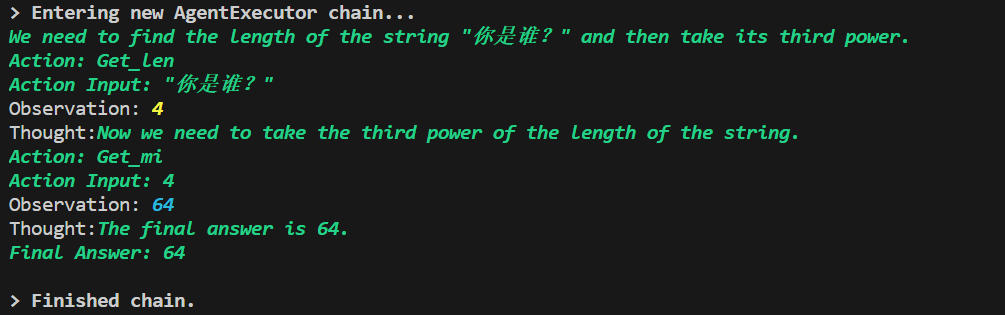
- CHAT_ZERO_SHOT_REACT_DESCRIPTION
以JSON形式思考,但整理成了无法识别的嵌套格式,报错了


- STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION
以JSON形式思考,很艰难地得到了正确答案
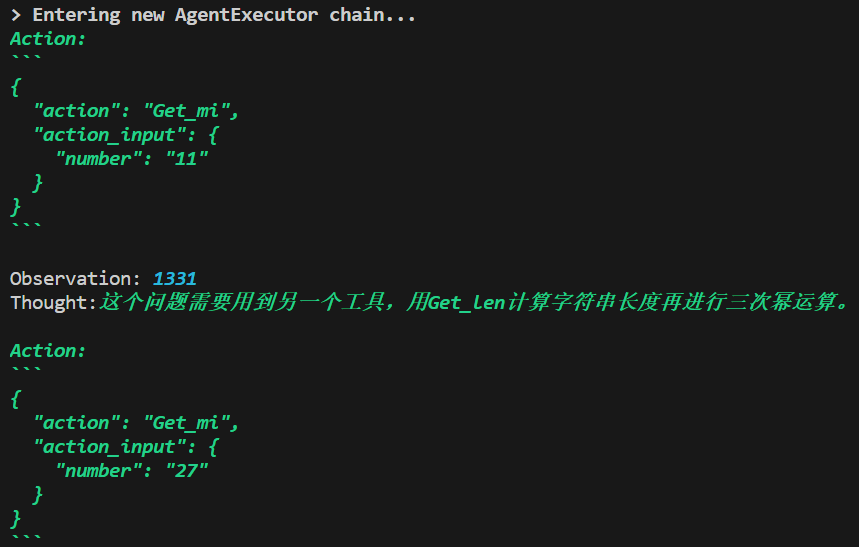


提示词分析
上面我们可以看到,不同Agent的输出格式相差很大,这主要是由于Agent内置的提示词不同导致的。在使用initialize_agent初始化agent变量之后,可以查看生成的提示词,比较它们的区别。
- 以ZERO_SHOT_REACT_DESCRIPTION为例,对其生成的变量agent打印
agent.agent.llm_chain.prompt.template可以看到一个非常完整的思维链提示
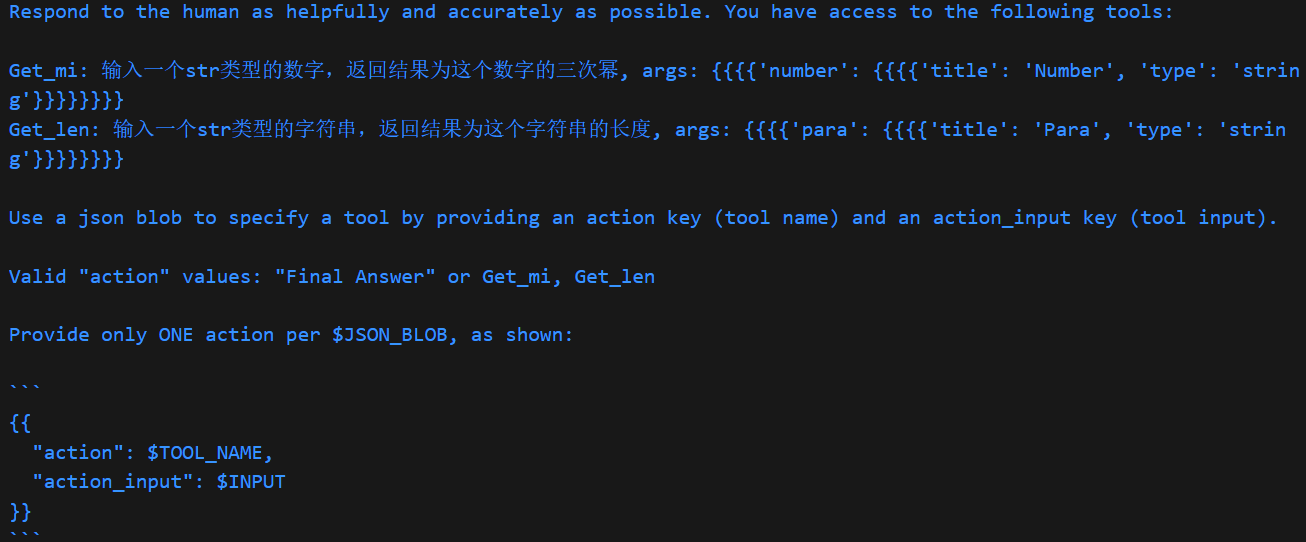
Answer the following questions as best you can. You have access to the following tools:
Get_mi: 输入一个str类型的数字,返回结果为这个数字的三次幂
Get_len: 输入一个str类型的字符串,返回结果为这个字符串的长度
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Get_mi, Get_len]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
-
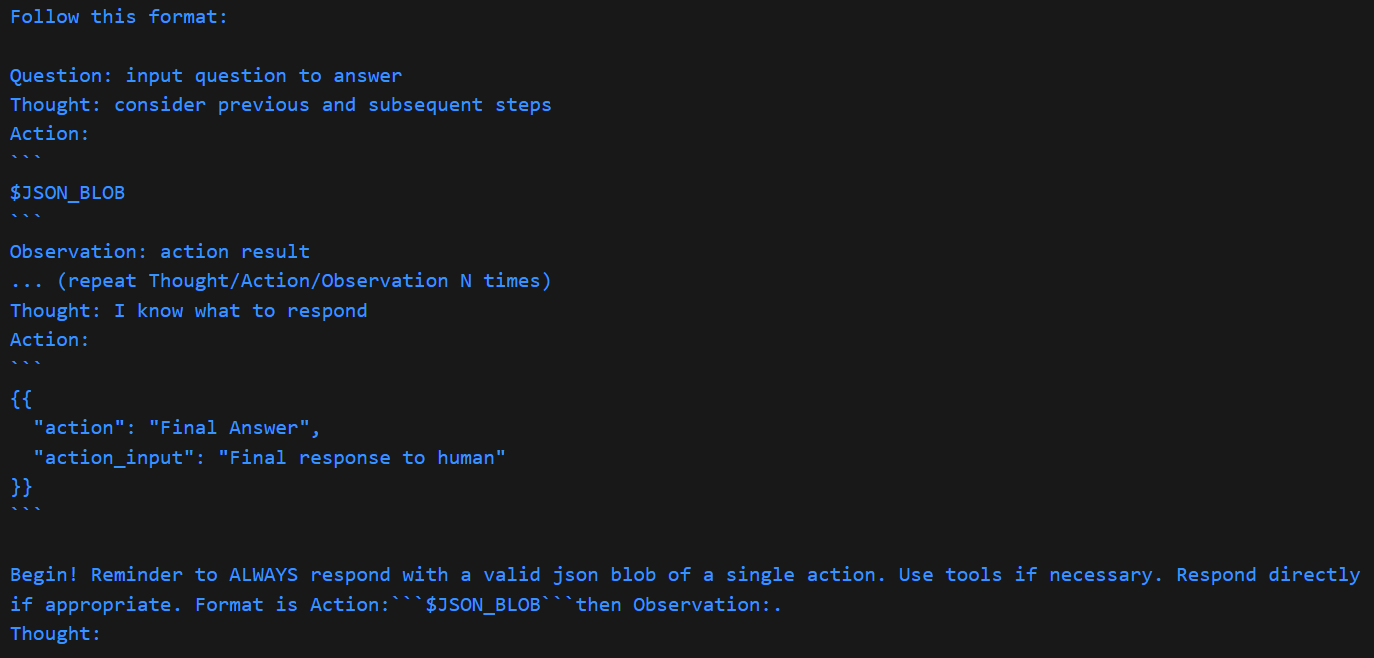
而STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION的情况比较不一样,拆分成了系统和用户提示词,可以分别打印
agent.agent.llm_chain.prompt.messages[0].prompt.template和agent.agent.llm_chain.prompt.messages[1].prompt.template来查看:-
系统提示
-
用户提示
{input} {agent_scratchpad}
-
Langchain中最核心的chain,其实就是llm+template+input。使用agent时的template又等于Template+tool,其中Template就是不同agent自带的模版定义,tool是用户传入的工具列表,input是当前输入的问题。从这个角度看,agent是一种特殊的chain,其整体执行过程如下图所示。

解析算法分析
不管是思维链文本形式还是json形式,大模型上面的输出都是很符合人类的推理思维的,那么程序内部又是怎么将文本转化成程序的实际动作,或者说是如何完成Action的呢。这就要看一下agent中用到的output_parser的实现了。
- 以ZERO_SHOT_REACT_DESCRIPTION为例,执行下面代码查看函数的实现
source = inspect.getsourcelines(agent.agent.output_parser.parse)
source_str = ""
for line in source[0]:
source_str += line
print(source_str)
代码主要通过正则匹配解析大模型输出,判断是否包含FINAL_ANSWER_ACTION和Action/Input,然后封装返回不同的对象。主要逻辑分支包括是否匹配、答案在前后、包含答案但没有匹配等情况。因此,大模型只有输出的回答非常符合规范才行,某些开源离线模型由于智商过低,回答得乱七八糟,很容易出现无法正确解析的情况。
如果格式正确,那么会返回两种类型,要么对话结束返回AgentFinish,要么继续动作执行 AgentAction。
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
includes_answer = FINAL_ANSWER_ACTION in text
regex = (
r"Action\s*\d*\s*:[\s]*(.*?)[\s]*Action\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)"
)
action_match = re.search(regex, text, re.DOTALL)
if action_match and includes_answer:
if text.find(FINAL_ANSWER_ACTION) < text.find(action_match.group(0)):
# if final answer is before the hallucination, return final answer
start_index = text.find(FINAL_ANSWER_ACTION) + len(FINAL_ANSWER_ACTION)
end_index = text.find("\n\n", start_index)
return AgentFinish(
{"output": text[start_index:end_index].strip()}, text[:end_index]
)
else:
raise OutputParserException(
f"{FINAL_ANSWER_AND_PARSABLE_ACTION_ERROR_MESSAGE}: {text}"
)
if action_match:
action = action_match.group(1).strip()
action_input = action_match.group(2)
tool_input = action_input.strip(" ")
# ensure if its a well formed SQL query we don't remove any trailing " chars
if tool_input.startswith("SELECT ") is False:
tool_input = tool_input.strip('"')
return AgentAction(action, tool_input, text)
elif includes_answer:
return AgentFinish(
{"output": text.split(FINAL_ANSWER_ACTION)[-1].strip()}, text
)
if not re.search(r"Action\s*\d*\s*:[\s]*(.*?)", text, re.DOTALL):
raise OutputParserException(
f"Could not parse LLM output: `{text}`",
observation=MISSING_ACTION_AFTER_THOUGHT_ERROR_MESSAGE,
llm_output=text,
send_to_llm=True,
)
elif not re.search(
r"[\s]*Action\s*\d*\s*Input\s*\d*\s*:[\s]*(.*)", text, re.DOTALL
):
raise OutputParserException(
f"Could not parse LLM output: `{text}`",
observation=MISSING_ACTION_INPUT_AFTER_ACTION_ERROR_MESSAGE,
llm_output=text,
send_to_llm=True,
)
else:
raise OutputParserException(f"Could not parse LLM output: `{text}`")
- STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION就比较复杂了,直接输出的结果是这样,可以定义
output_fixing_parser或者用base_parser进行解析,这里应该是调了预定义的output_fixing_parser。
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
try:
if self.output_fixing_parser is not None:
parsed_obj: Union[
AgentAction, AgentFinish
] = self.output_fixing_parser.parse(text)
else:
parsed_obj = self.base_parser.parse(text)
return parsed_obj
except Exception as e:
raise OutputParserException(f"Could not parse LLM output: {text}") from e
执行下面的命令,打印出output_fixing_parser的实现看看
source = inspect.getsourcelines(agent.agent.output_parser.output_fixing_parser.parse)
source_str = ""
for line in source[0]:
source_str += line
print(source_str)
def parse(self, completion: str) -> T:
retries = 0
while retries <= self.max_retries:
try:
return self.parser.parse(completion)
except OutputParserException as e:
if retries == self.max_retries:
raise e
else:
retries += 1
completion = self.retry_chain.run(
instructions=self.parser.get_format_instructions(),
completion=completion,
error=repr(e),
)
raise OutputParserException("Failed to parse")
可以看出其本质上就是在走这样一个流程,尝试用解析器解析,如果解析失败出现格式问题,使用retry_chain尝试重整格式并再次解析,最多重复max_retries次。
下面我们再看看parser.parse内部的逻辑,其实跟之前差不多,还是正则表达式,不同的是通过JSON来提取action的具体参数。
source = inspect.getsourcelines(agent.agent.output_parser.output_fixing_parser.parser.parse)
source_str = ""
for line in source[0]:
source_str += line
print(source_str)
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
try:
action_match = self.pattern.search(text)
if action_match is not None:
response = json.loads(action_match.group(1).strip(), strict=False)
if isinstance(response, list):
# gpt turbo frequently ignores the directive to emit a single action
logger.warning("Got multiple action responses: %s", response)
response = response[0]
if response["action"] == "Final Answer":
return AgentFinish({"output": response["action_input"]}, text)
else:
return AgentAction(
response["action"], response.get("action_input", {}), text
)
else:
return AgentFinish({"output": text}, text)
except Exception as e:
raise OutputParserException(f"Could not parse LLM output: {text}") from e
自定义Agent
其实Agent最重要的就是两个部分,一部分是要定义好Template模版规范模型的输出格式,一部分是要定义好output_parser去解析输出内容。前者可以通过继承StringPromptTemplate 类来实现,后者可以通过继承AgentOutputParser类来自定义,这里就不细说了。
基于LLM的Tool
Tool的定义不仅仅可以基于算法,也可以引入一个LLM,比如说写一个小说创作的Tool。
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
class Get_xiaoshuo(BaseTool, abc.ABC):
name = "Get_xiaoshuo"
description = "根据梗概添加细节写小说"
def __init__(self):
super().__init__()
async def _arun(self, *args: Any, **kwargs: Any) -> Any:
# 用例中没有用到 arun 不予具体实现
pass
def _run(self, para: str) -> str:
prompt_template = PromptTemplate.from_template(
"你是一名小说家,请根据下列梗概写小说:{info}"
)
chain = LLMChain(llm=myllm.llm, prompt=prompt_template)
return chain.run({"info":para})
基于ChatGLM的Agent调用与分析
模型定义
看了看ChatGLM3.py里定义的类,其实最重要的就两块,一个是模型加载
def load_model(self, model_name_or_path=None):
model_config = AutoConfig.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
self.tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path,
trust_remote_code=True
)
self.model = AutoModel.from_pretrained(
model_name_or_path, config=model_config, trust_remote_code=True
).half().cuda(1)
另一块就是模型推理了
def _call(self, prompt: str, history: List = [], stop: Optional[List[str]] = ["<|user|>"]):
print("======")
print(prompt)
print("======")
if not self.has_search:
self.history, query = self._tool_history(prompt)
else:
self._extract_observation(prompt)
query = ""
# print("======")
# print(history)
# print("======")
_, self.history = self.model.chat(
self.tokenizer,
query,
history=self.history,
do_sample=self.do_sample,
max_length=self.max_token,
temperature=self.temperature,
)
response = self._extract_tool()
history.append((prompt, response))
return response
注意在上面的代码中,传入的prompt即agent生成的模版内容,其中对工具及其传入参数的描述为字符串形式,形如args: {{'number': {{'title': 'Number', 'type': 'string'}}}}。但是ChatGLM可能训练时没有格式与之对齐,不能直接将其作为输入,因此需要使用_tool_history做一步转换,将字符串转换为json。
转换时首先用正则表达式提取出工具名,然后从本地读取对应的yaml文件为json,其中包含了对函数以及函数输入参数的详细描述,形如{'name': 'Get_mi', 'description': '输入一个str类型的数字,返回结果为这个数字的三次幂', 'parameters': {'type': 'object', 'properties': {'number': {'type': 'str', 'description': 'The number to be calculated'}}, 'required': ['number']}}。最后按如下格式返回history和query。
ans.append({
"role": "system",
"content": "Answer the following questions as best as you can. You have access to the following tools:",
"tools": tools_json
})
query = f"""{prompt.split("Human: ")[-1].strip()}"""
在执行推理步骤后,整个对话的history如下图所示:
_, self.history = self.model.chat(
self.tokenizer,
query,
history=self.history,
do_sample=self.do_sample,
max_length=self.max_token,
temperature=self.temperature,
)
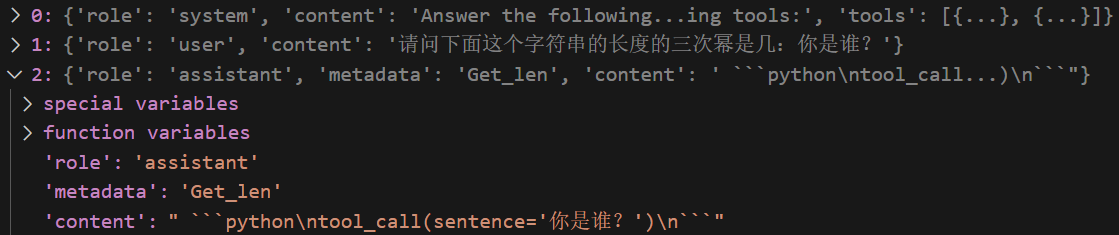
可以看到,如果调用了工具,content里面会有一句tool_call,基于这一点,可调用_extract_tool函数将其转换为agent的output_parser可解析的形式。
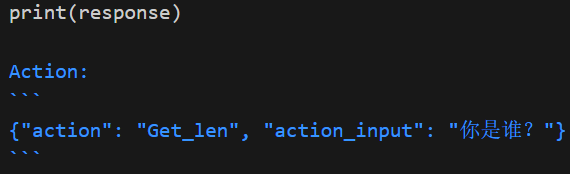
从上面的分析可以看出,ChatGLM并不原生支持Agent,它原生支持的是工具调用Tool_call,这里是将其输入和输出做了封装,以适应Agent格式。
测试效果
不知道为什么,直接使用的话智商会很低,每次只调用Get_len这一个函数,不调用Get_mi,最后乱说一气,让人非常恼火。

改了改prompt,成了

怎么改的呢,我称之为降智法:

支持对话
虽然现在功能算是测试通过了,但有一个小问题,那就是这个模型是不支持对话的,只能直接调用工具,在一些场景下,可能需要常规对话和工具调用并行不悖,这时候可以对其推理函数做一些小小的修改,加入对当前是否为agent模式的判断。
def _call(self, prompt: str, history: List = [], stop: Optional[List[str]] = ["<|user|>"]):
self.history = []
query = prompt
if "tool" in prompt:
if not self.has_search:
self.history, query = self._tool_history(prompt)
else:
self._extract_observation(prompt)
query = ""
res, self.history = self.model.chat(
self.tokenizer,
query,
history=self.history,
do_sample=self.do_sample,
max_length=self.max_token,
temperature=self.temperature,
)
if "tool" in prompt:
response = self._extract_tool()
history.append((prompt, response))
else:
response = res
return response

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)