
ComfyUI使用总结
ComfyUI,它的主要特点是以工作流的形式来进行和展现基于stable diffusion模型的文生图和图生图的过程,拖拽式操作来链接各个节点,比如base model、vae、controlnet、lora、hypernet等。让整个生成过程更加清晰,易于理解。
前言
目前github上star最多的文生图、图生图框架是stable-diffusion-webui,今天要介绍的是另一款很受欢迎的文生图、图生图框架ComfyUI,它的主要特点是以工作流的形式来进行和展现基于stable diffusion模型的文生图和图生图的过程,拖拽式操作来链接各个节点,比如base model、vae、controlnet、lora、hypernet等。让整个生成过程更加清晰,易于理解。在介绍ComfyUI的安装、配置、使用之前,先看一张ComfyUI的操作界面

github地址:https://github.com/comfyanonymous/ComfyUI
有趣的使用教程:https://comfyanonymous.github.io/ComfyUI_tutorial_vn/
节点说明文档:https://blenderneko.github.io/ComfyUI-docs/
1.安装
安装过程如下:
# 创建虚拟环境
conda create -n sd python=3.10
conda activate sd
# 克隆ComfyUI仓库,安装依赖
git clone https://github.com/comfyanonymous/ComfyUI
cd ComfyUI
pip install -r requirements.txt
# 启动ComfyUI
python main.py
将stable diffusion底模(如:stable-diffusion-xl-base-1.0和stable-diffusion-xl-refiner-1.0)放在models/checkpoints目录下;将vae、lora、controlnet等模型和插件放在ComfyUI/models/下的对应目录里。可以从Civitai或者LiblibAI下载各种sd的底模和插件

2.使用
ComfyUI启动后,默认的端口号是8188,在浏览器中输入http://127.0.0.1:8188/即可打开操作页面
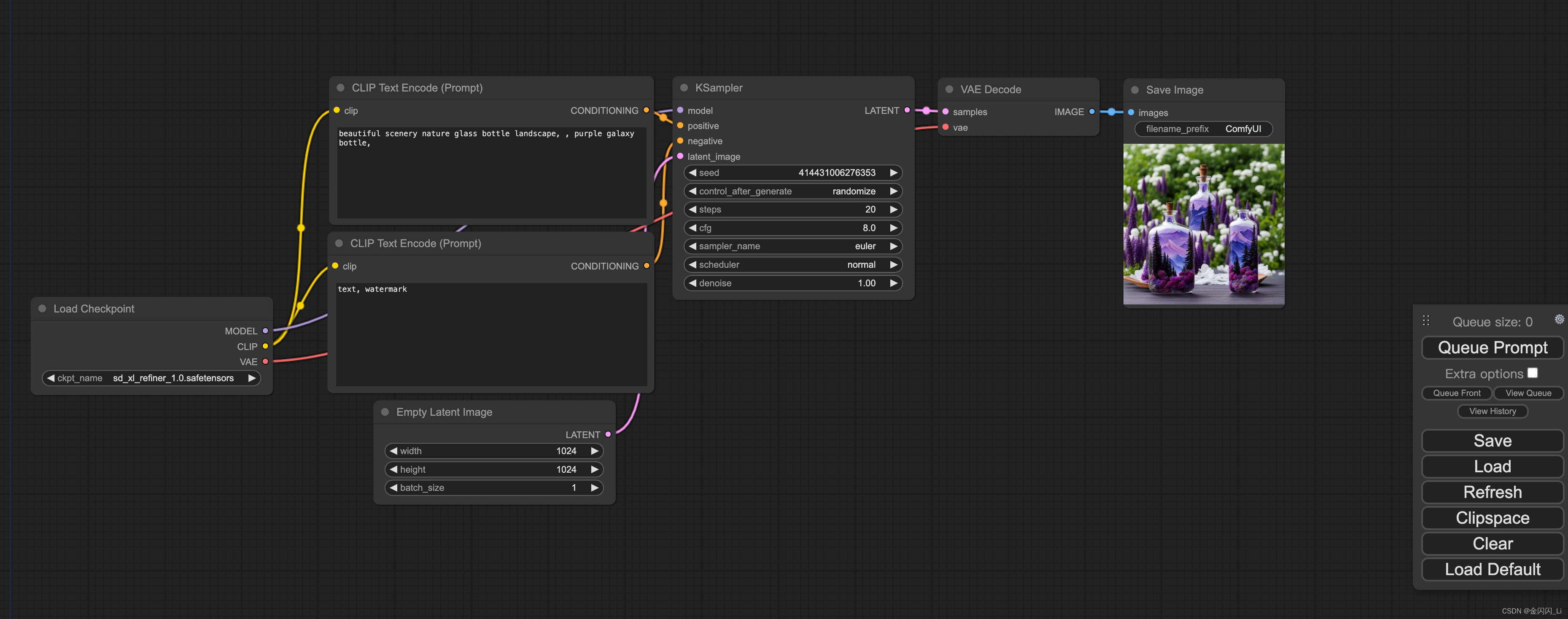
1.常用节点和功能介绍
Load Checkpoint节点:选择stable diffusion底模,输出model、clip、vae
CLIP Text Encode(Prompt)节点:输入正向提示和负向提示,输入的文本将被clip模型进行编码
Empty Latent Image节点:生成空的隐空间图片,可以配置图片的长、宽、数量
KSampler节点:采样器,输入model、编码后的正向提示、编码后的负向提示、隐空间图片,配置随机种子、扩散步数、降噪强度等参数
VAE Decode节点:用于将隐空间中的图片解码成像素空间的图片
2.图片放大
ComfyUI中的图片放大方法主要有两种,第一种是在采样器输出的隐空间中放大,然后再进行一轮采样,最后解码成像素空间;第二种是在vae解码后的像素空间上进行放大,将放大后的图片再经过vea编码成隐空间,然后再进行一轮采样,最后解码成像素空间

在像素空间放大时使用了upscale model,这里介绍一个upscale model的网站:https://openmodeldb.info/
3.图生图
从工作流的节点可以看出,文生图的过程也是一种图生图,只是文生图过程中传入的是一个空的隐空间图像。在图生图过程中,vae模型会先将给定的图片编码成隐空间特征,用隐空间特征替代文生图中的空隐空间图像,后面的过程就和文生图一样了

4.图片修复
加载一张需要修补的图片,mask是需要修补的图像特征,vae在会同时编码image和mask图像来得到隐空间特征。下面的例子是在需修补的mask区域填充一只猫

5.lora
lora模型会同时作用于model和clip,lora模型可以通过串联同时使用多个

6.hypernetworks
超网络只作用于model

7.Embeddings/Textual Inversion
文本嵌入通常在prompt中使用,目的是将prompt中的指定词汇用自定义的embedding模型进行编码,例如下面的图片是使用了embedding_MarblingTIXL模型对prompt进行编码

8.区域组合
区域拼接通过不同的prompt作用不同的区域,再将各个区域联结起来,一起用采样器去噪,最后得到一张保护不同风格景色的图。区域组合实际上是将clip编码后的文本特征组合在一起

9.噪声隐空间组合
和区域组合不同的是,噪声隐空间组合是将采样后的隐空间图片特征组合在一起

10.controlnets和t2i-adapters
controlnets和t2i-adapters可以在图像生成过程中通过示例图像控制生成对象的位置、姿态和形状等。controlnets既可以单独加载,也可以链接base model,通常作用与编码后的正向提示词和示例图片,将controlnets得到的结果再作为正向提示传入采样器中


11.gligen
文本框gligen模型可以通过prompt控制对象的位置,gligen和clip一起对控制文本进行编码,然后和编码后的正向提示融合,得到新的文本编码特征当作正向提示传入到采样器中

12.unclip
unclip模型是经过特别调整的SD模型的版本,除了文本提示符之外,还可以接收图像作为输入。使用这些模型自带的CLIPVision对图像进行编码,然后在采样时将其提取的概念传递给主模型。CLIPVision对像素空间的图片进行编码,然后和编码后的正向提示融合作为新的正向提示传入采样器

13.模型合并
模型合并的思想是将多个checkpoint中的model融合后再作用于采样器

总结
文生图和图生图的过程包含了多个步骤,主要步骤有1)初始化隐空间图片特征,或者通过vae model对像素空间图片编码得到隐空间图片特征,2)clip model对正向和负向提示编码,得到文本特征,3)将隐空间图片特征和文本特征一起通过unet model降噪得到新的隐空间图片特征,4)利用vae model对隐空间图片特征解码得到像素空间图片
整个生成图片的过程十分灵活,我们可以在各个步骤上添加一些插件或者模型,来影响生成结果,ComfyUI就可以方便灵活的实现这些功能
参考链接:https://comfyanonymous.github.io/ComfyUI_examples/

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 25
25 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)